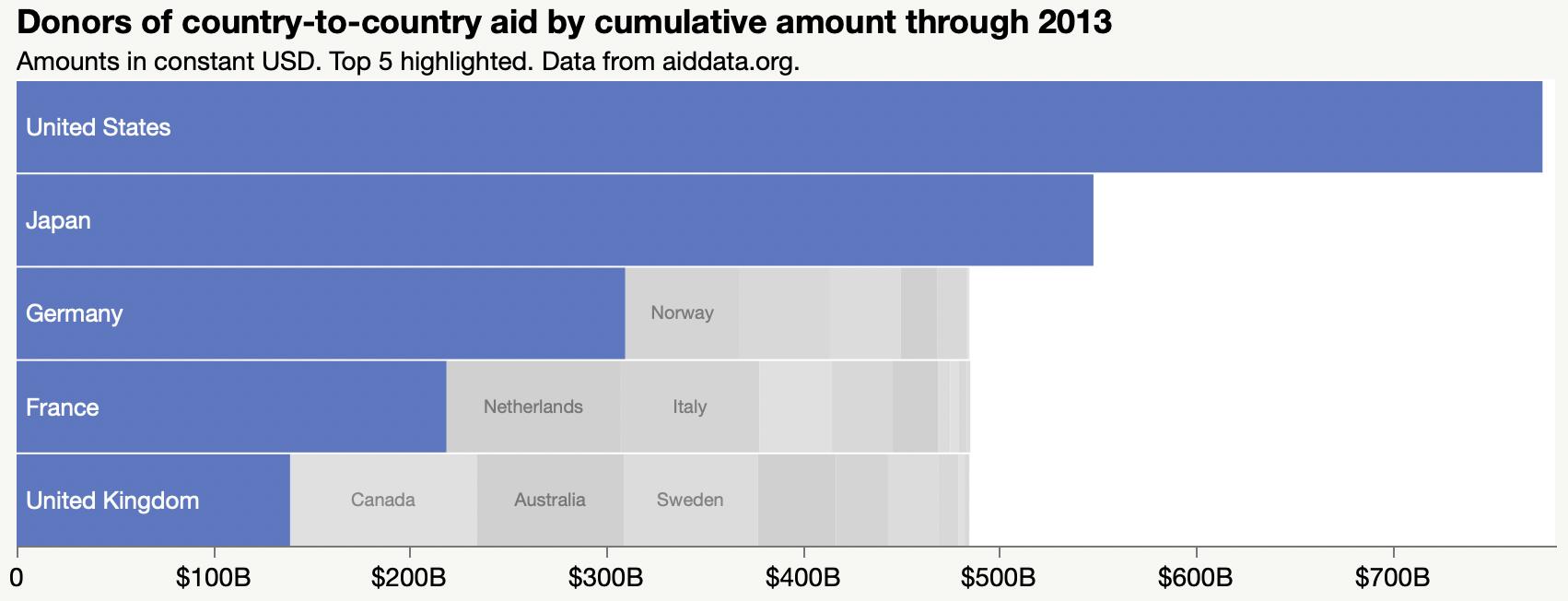
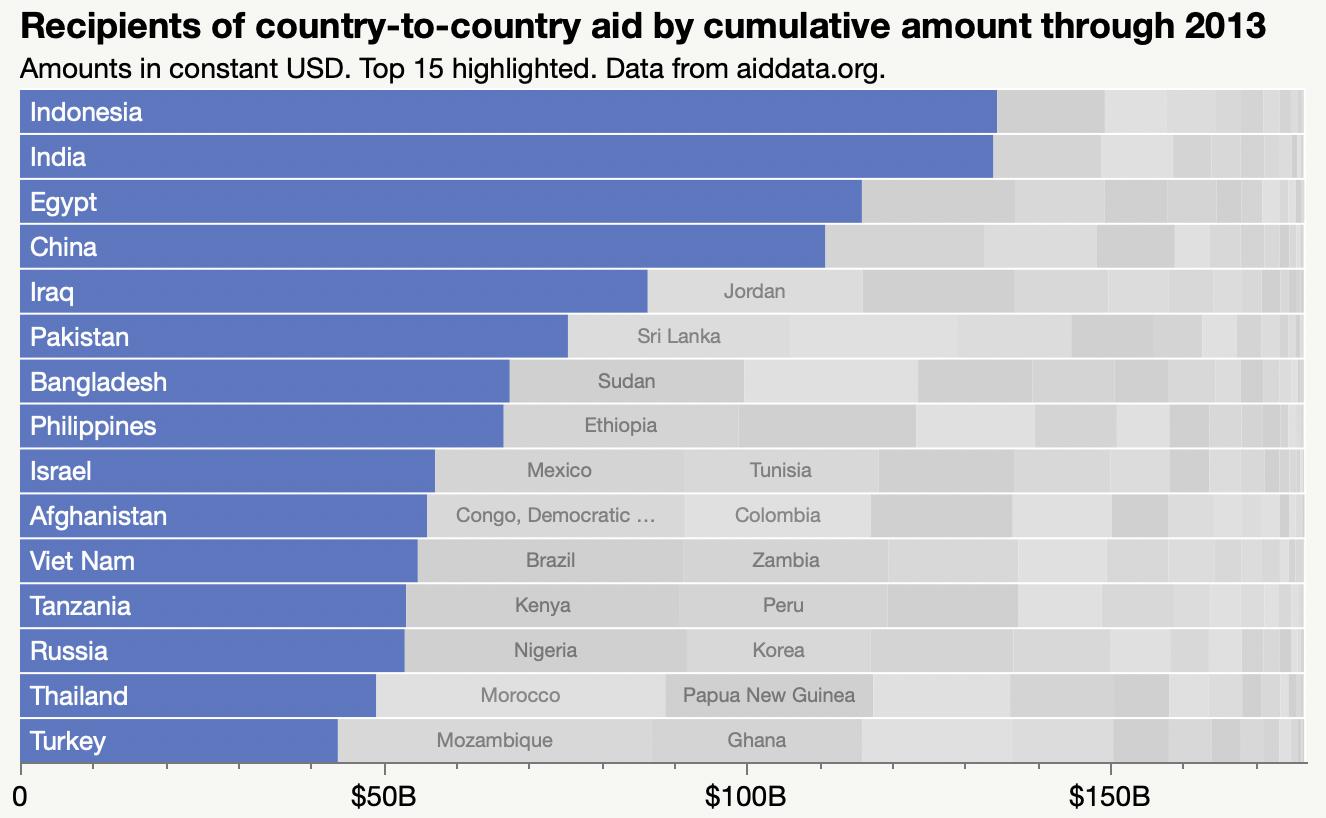
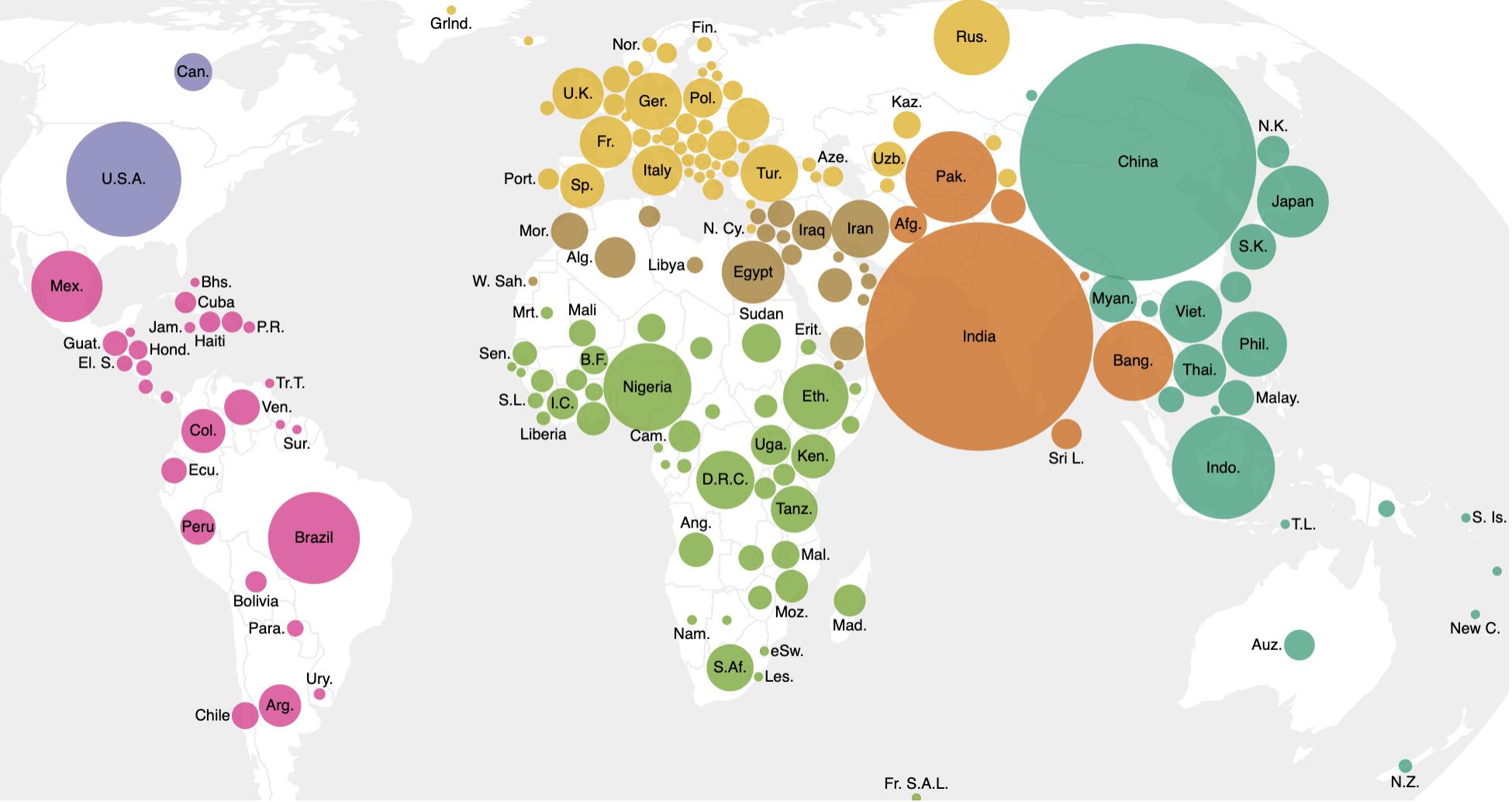
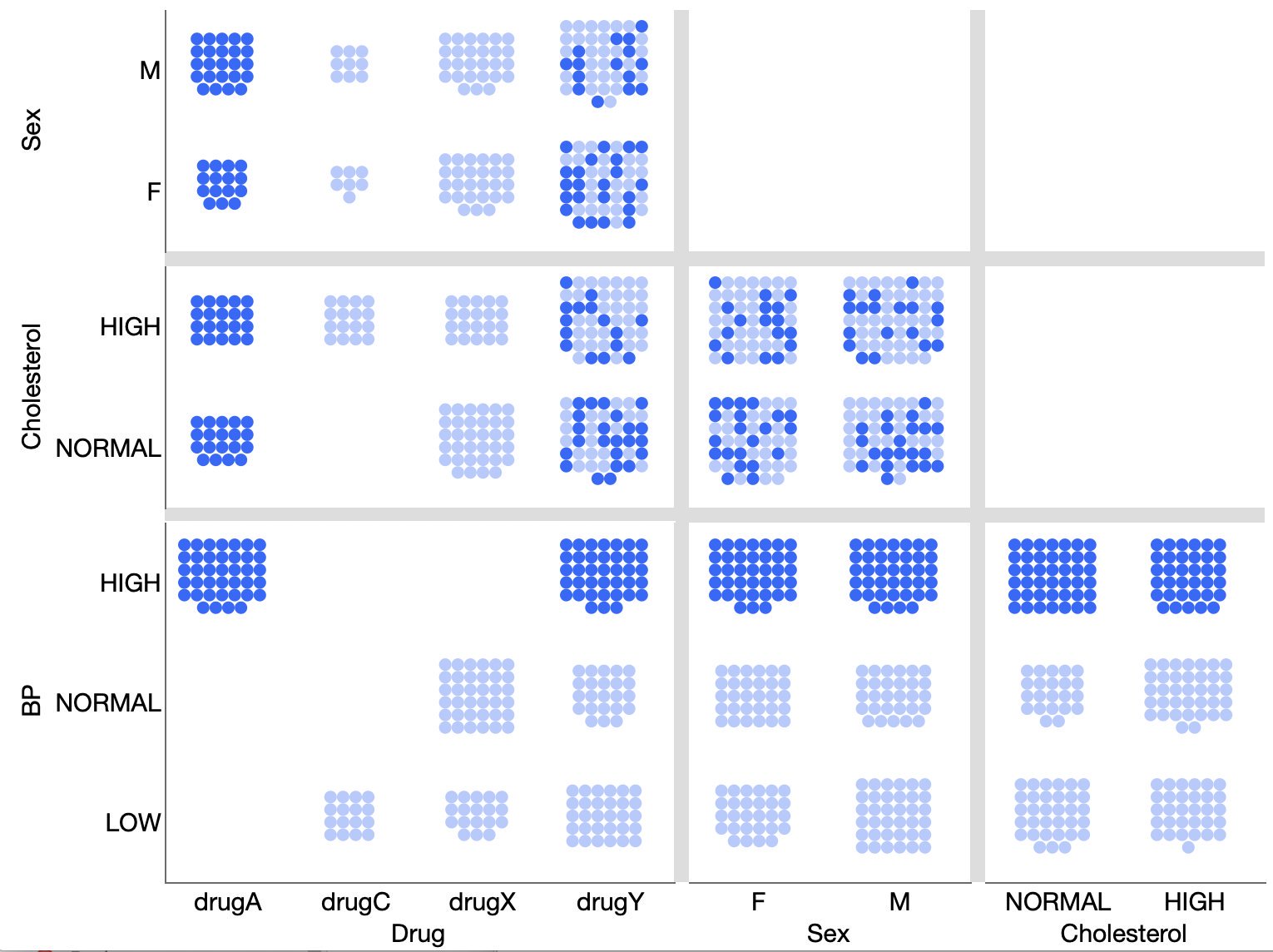
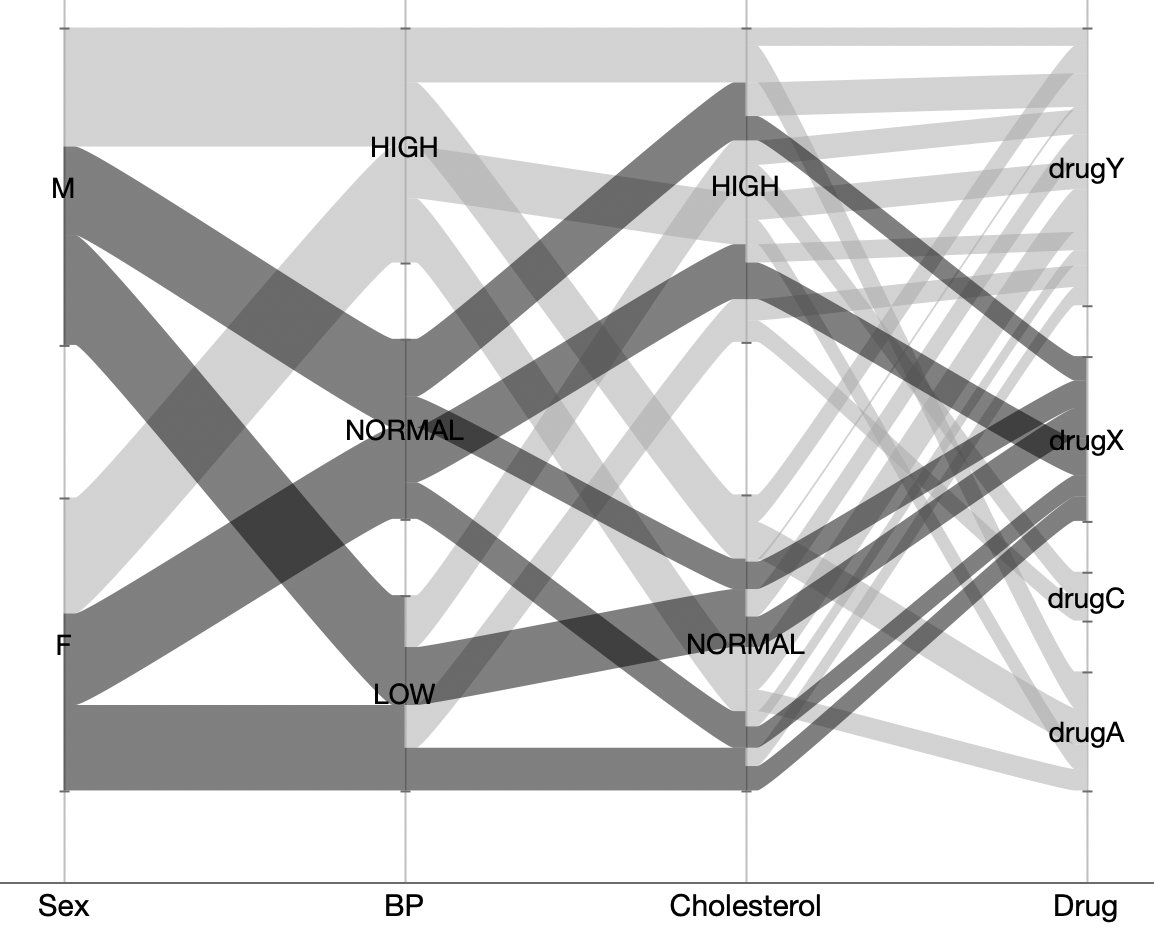
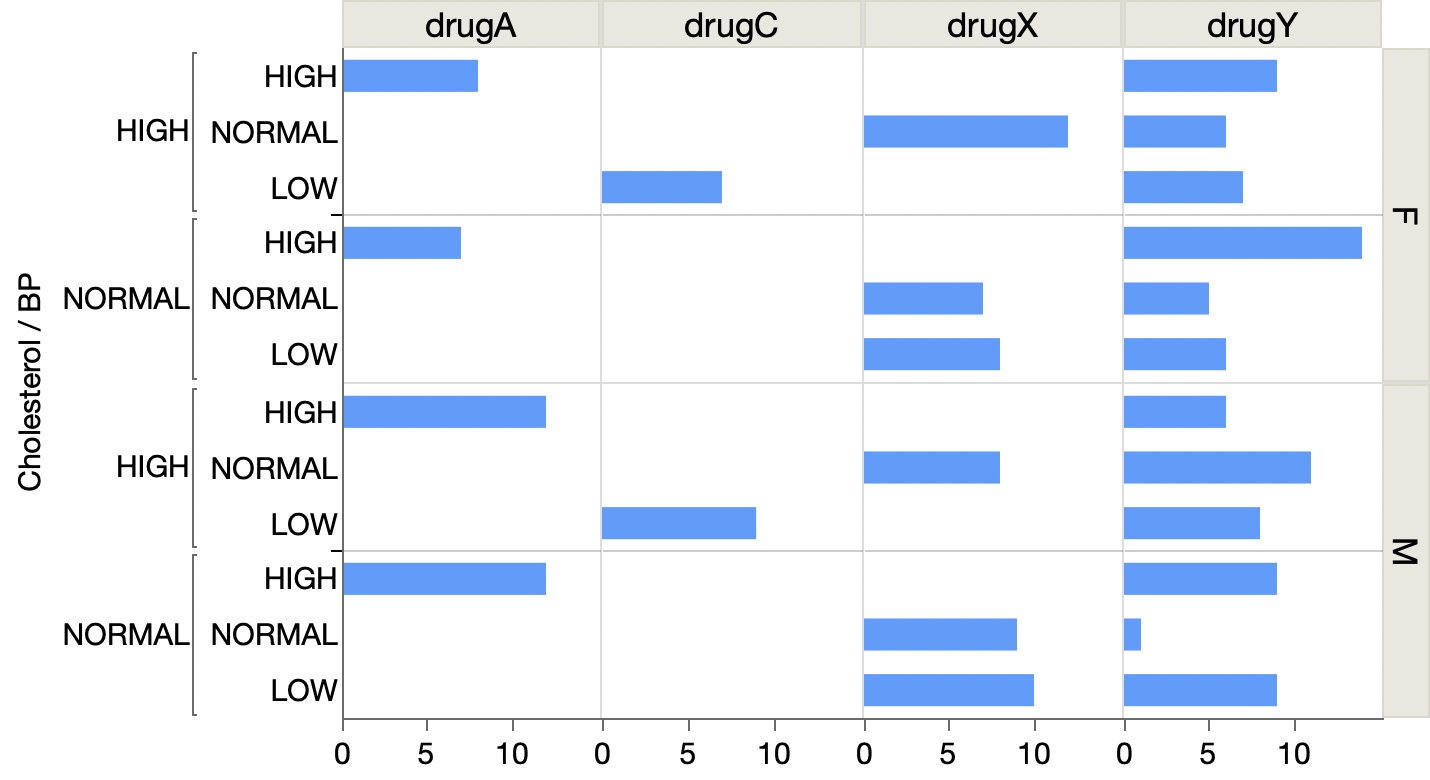
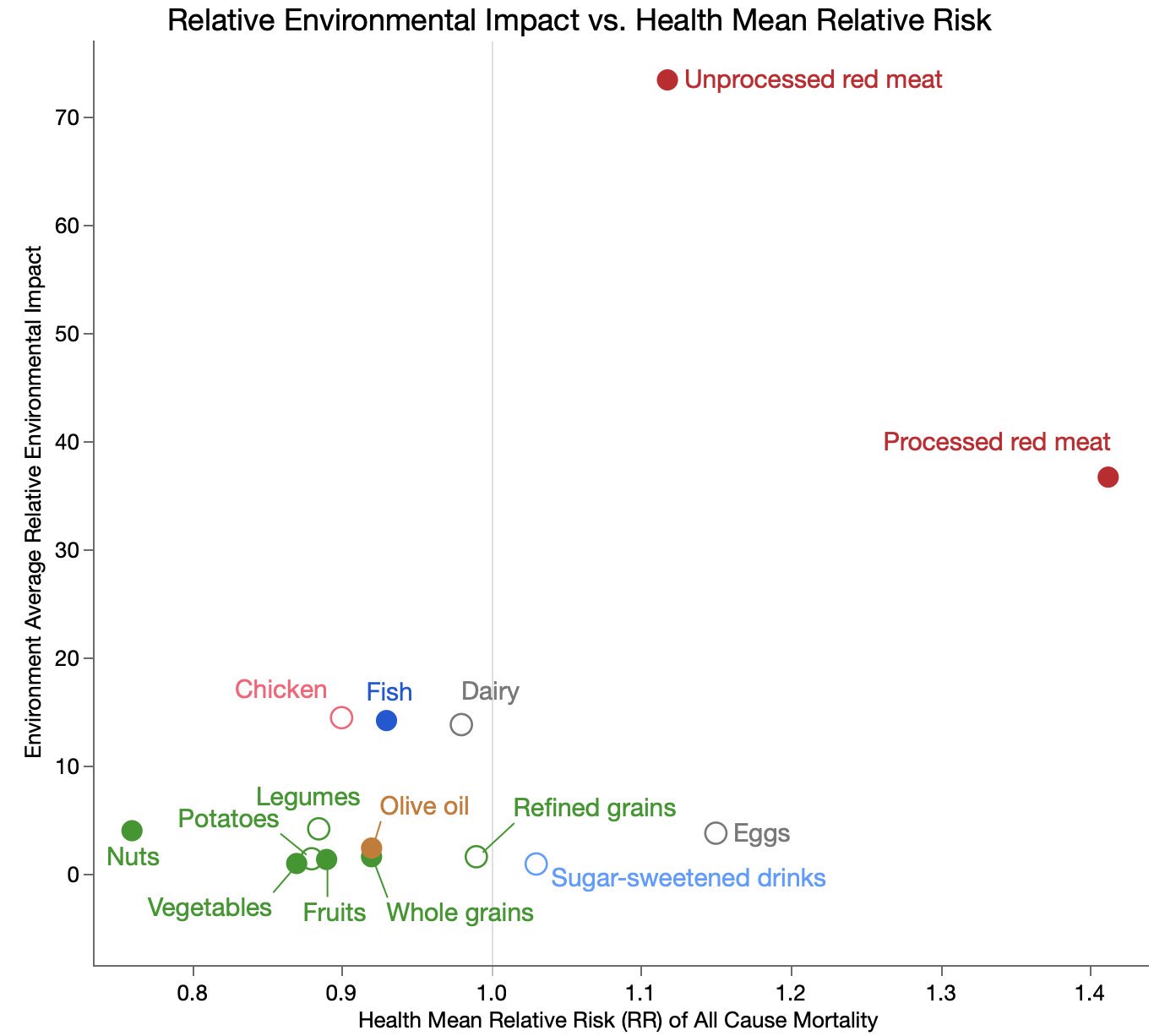
For my week-end data dives, I’ve found myself struggling to share the results in Twitter threads and decided to start blogging again. I created a new WordPress site, Raw Data Stories, for those posts and have migrated and updated a few posts from this blog to seed it with.
I’ll still be tweeting, but now I’ll at least have the blog posts for some of the context and details that can’t fit into a tweet.
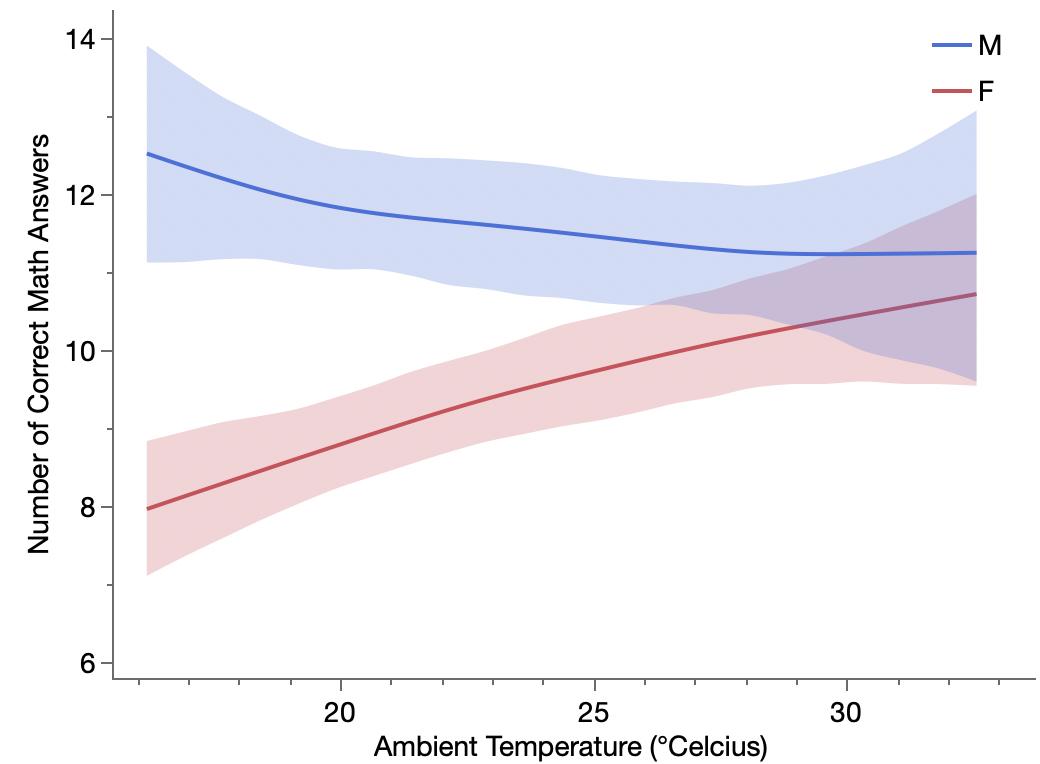
A recent paper, “Quantitative Translation of Dog-to-Human Aging by Conserved Remodeling of the DNA Methylome” in the journal Cell Systems has been getting attention in the media for a finding a new dog-age-to-human-age formula to replace the popular 7x formula. The paper estimates epigenetic age by measuring changes in DNA samples of dogs and humans of different ages. The new formula is not so easy to remember or compute: 31 + 16 × ln(dog years). It’s hardly news that the 7x formula is inaccurate, and the new equation seems plausible since it does incorporate the common understanding that dogs mature much faster than humans through adolescence and only somewhat faster during adulthood. However, looking closer at the study raises some questions about the final formula, and I’ll try to explore that in this post.
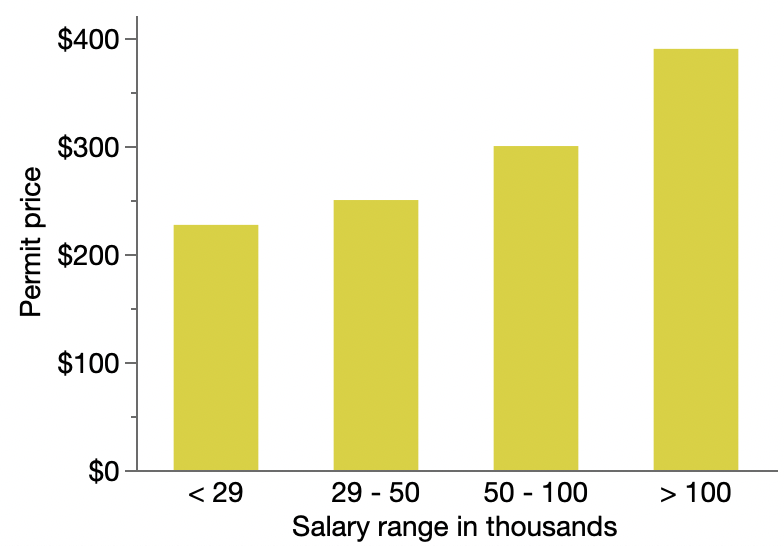
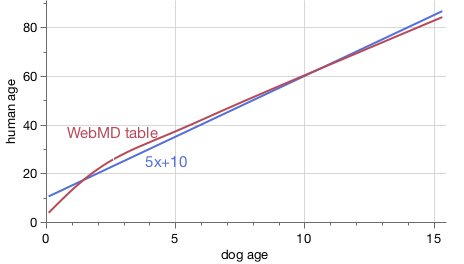
This WebMD dog-age–calculator article summarizes the previous expert knowledge of dog aging rates. I’m too lazy to find the original source; WebMD cites Purina, Humane Society and National Pet Wellness Month as sources for its table. The table has different data from small, medium and large dogs. Since the paper focused mainly on Labrador retrievers, I’ll use the WebMD data for medium-sized dogs and graph it against the other two models: the 7x rule and the epigenetic logarithmic model from the paper.
The 7x rule does a good job as a simple approximation of the relationship in the WebMD table and AVMA rule, especially for the mid-life range. However, the epigenetic age model is quite different in that region.
As a long-time dog owner, I have other doubts about the epigenetic model. It puts a 1 year old dog on par with a 31 year old human. While 1yo dogs are about full height, they still have some bulking up to do and their brains still seem adolescent. At the other end, there is a big physiological difference between a 10yo dog and a 15yo dog, but not much difference according to the epigenetic model. The most obvious explanation is that epigenetic age is not quite the same as observed physiological or mental maturity; however, the paper claims correspondence. Time for a deeper dive into the data.
Getting the data
What data? As far as I can tell the raw data is unavailable, even at the hosting Ideker Lab at UCSD.
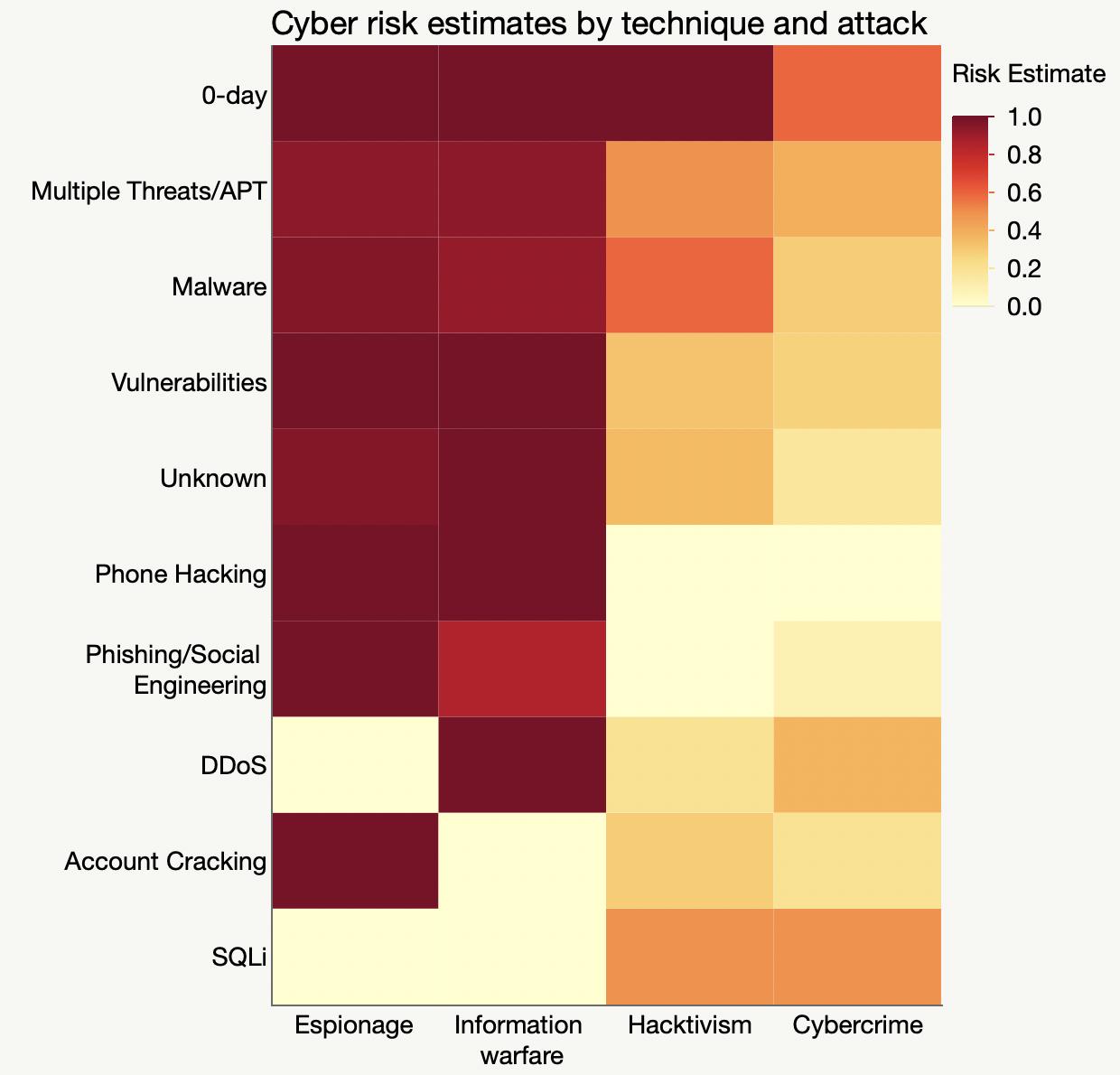
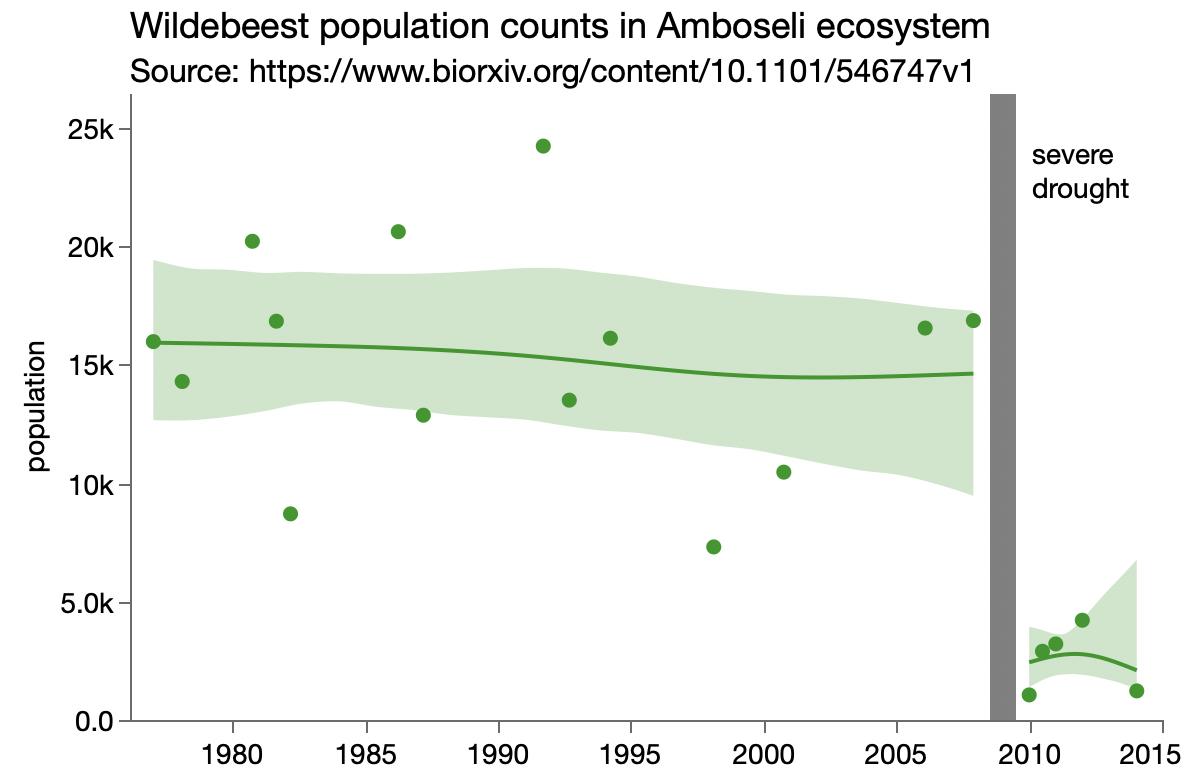
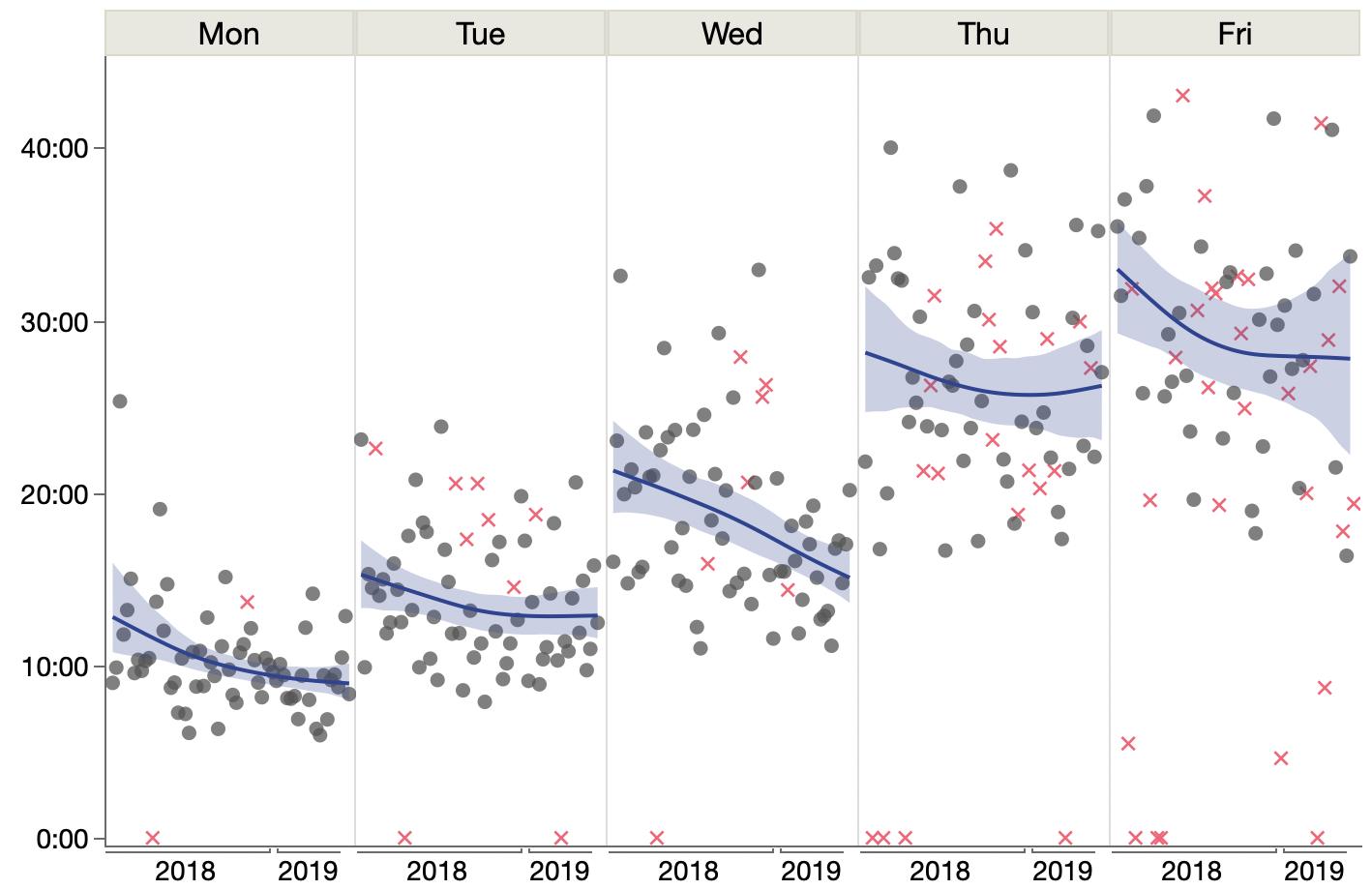
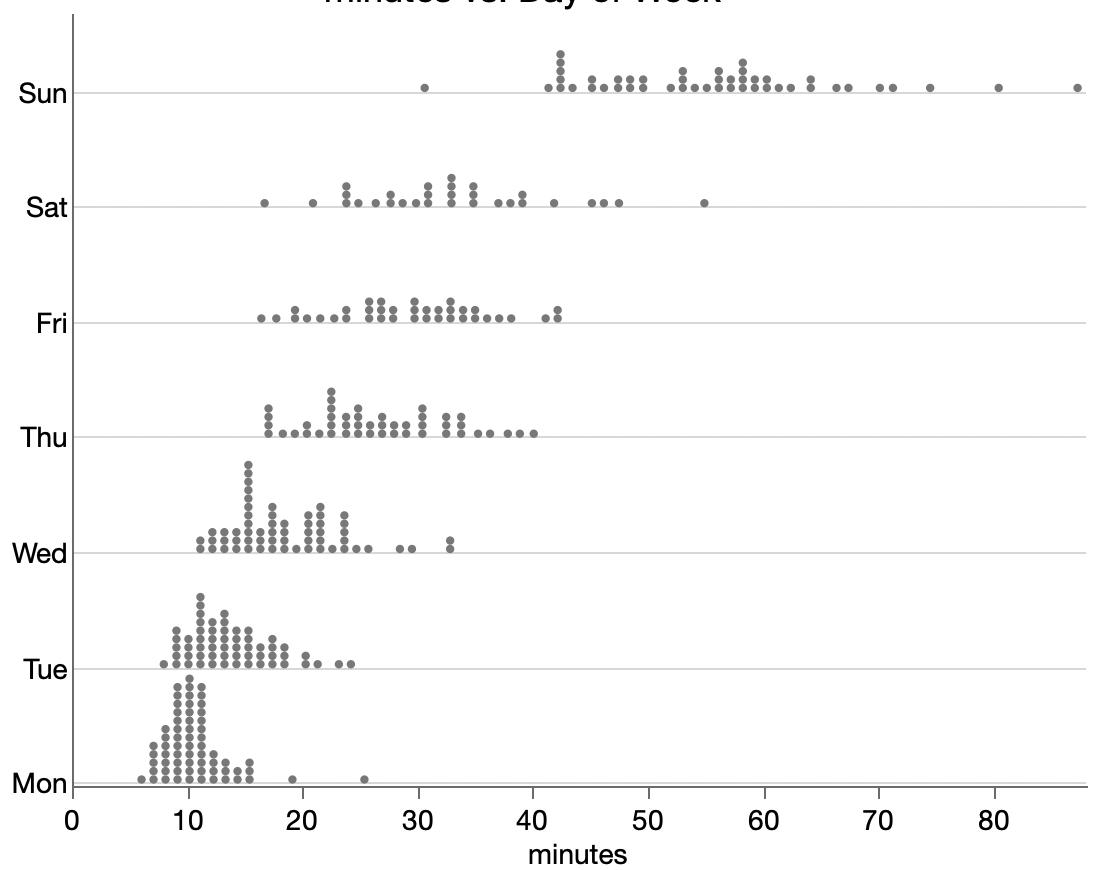
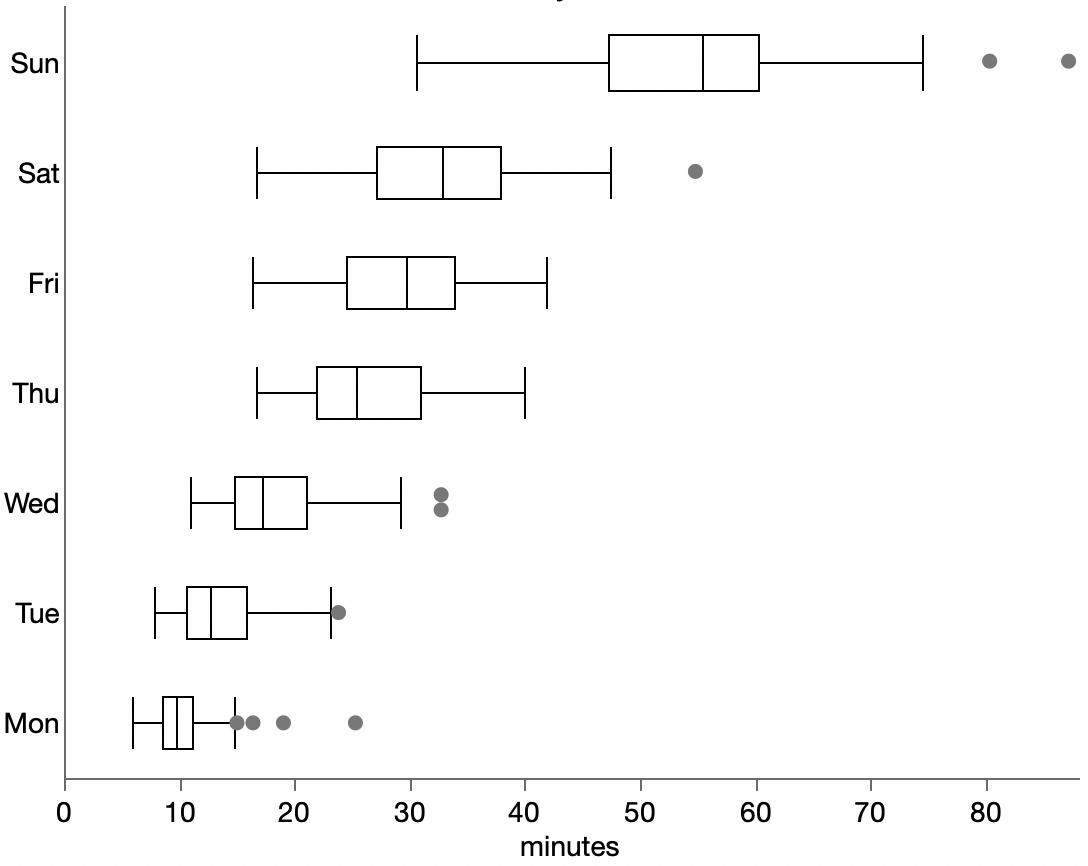
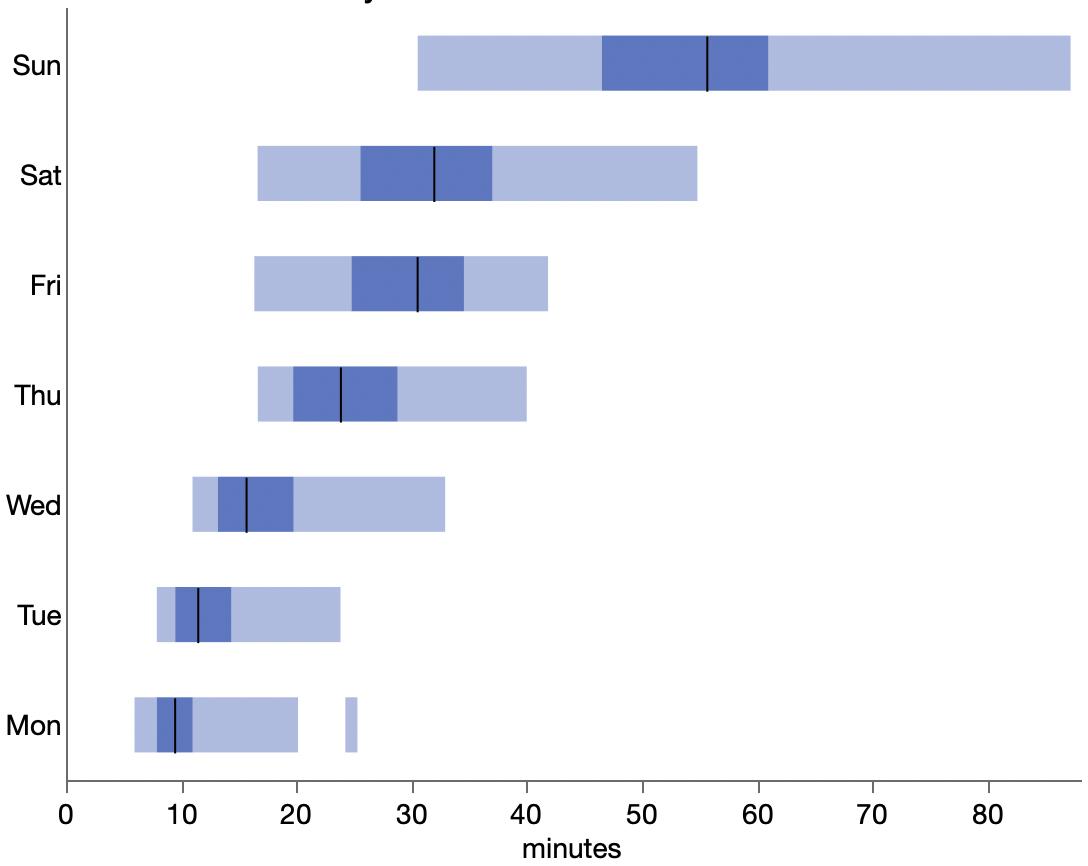
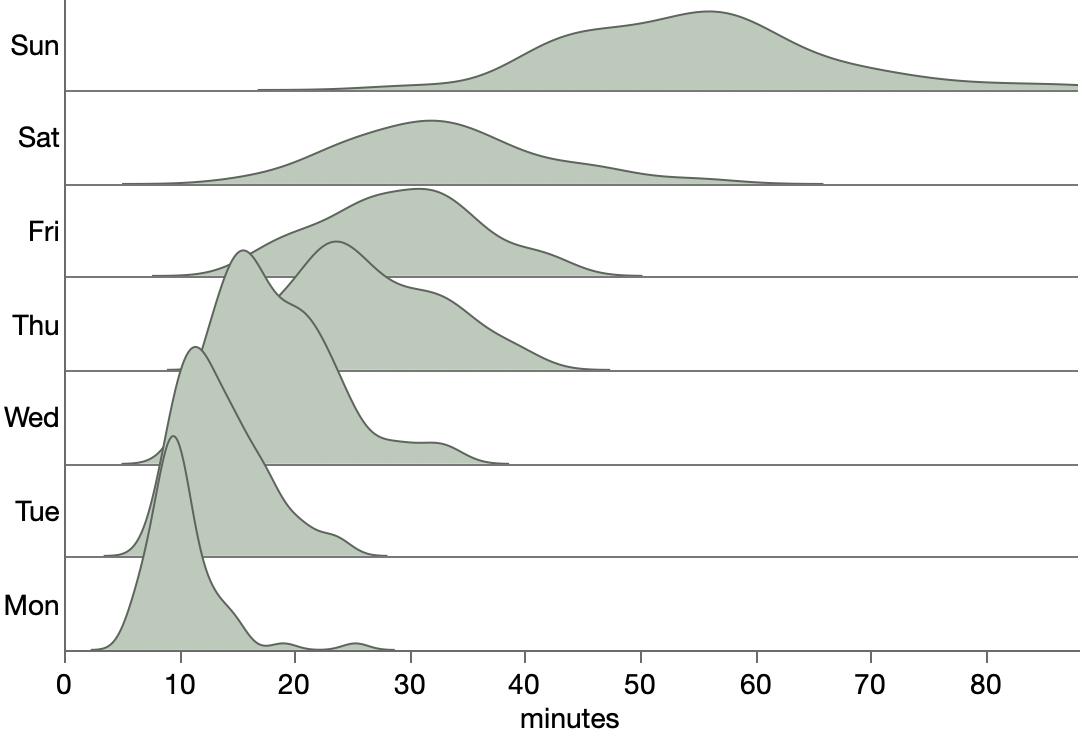
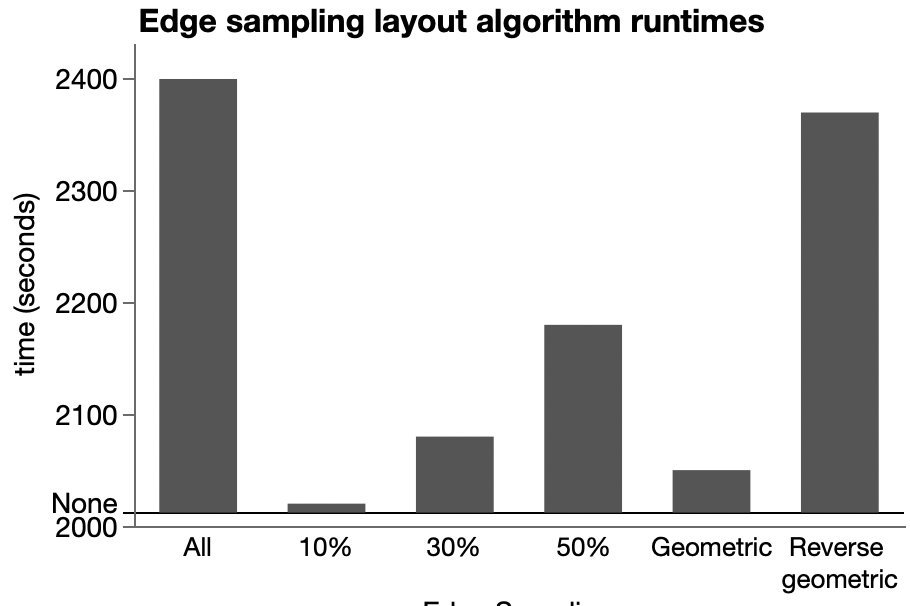
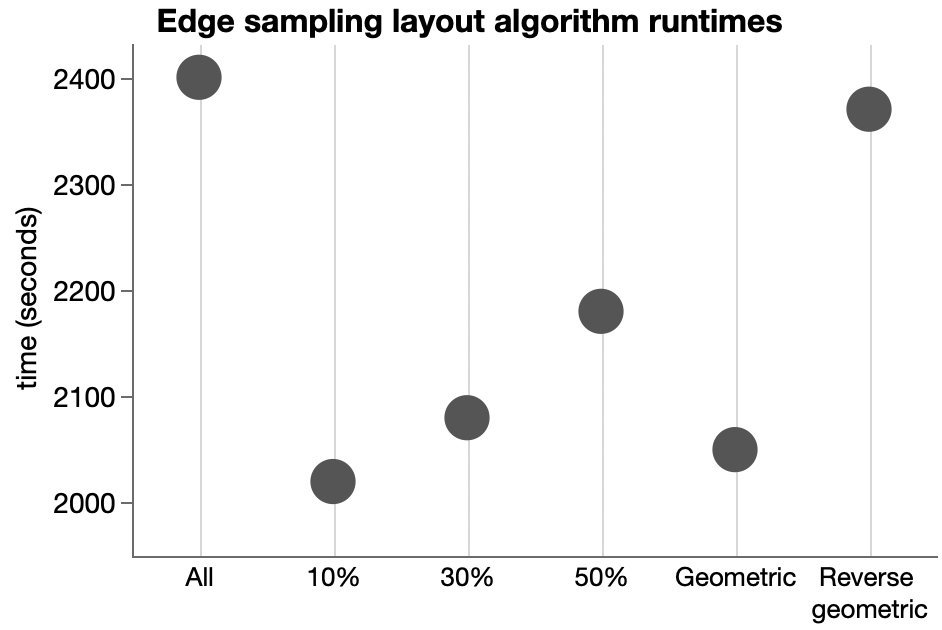
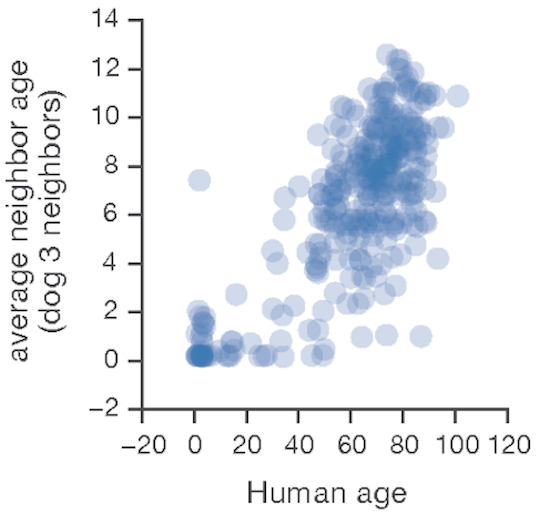
However, a resourceful person can glean a lot from the images in a paper. For the study, part of the analysis involved matching up similarly-aged dogs and humans. I’m imaging the epigenetic age has a high dimensional vector, so the matching is not trivial. They used the average of several nearest neighbors instead of a one-to-one match, which seems reasonable. The supplemental materials include a few graphs of different numbers of nearest neighbors. Here’s their plot after matching each dog with its three nearest humans.
Other charts show more neighbors averaged, but they aren’t much different. Presumably using fewer neighbors will have more variation, which will make it easier for me to distinguish the points and will be variation will handled by any modeling. To read the position of the dots, I used an online tool called WebPlotDigitizer, which lets me click on each point and get a table of numbers out. It also has some auto-detection methods, but I haven’t had much luck with those. Here’s the result with my clicks represented as red dots.
There is still a lot of overstriking and it’s hard to be sure I got them all. I tried a few diagnostics, even modeling the shade of green that transparent overlaying would produce for a given number of overlaid dots. I found a couple dots I missed but still couldn’t figure out why I only found 92 dots while the paper mentioned 104 dogs. Finally, I saw in the paper that 9 dogs were excluded for incomplete data, and I noticed from the list of dog ages that I likely undercounted the number of dogs in that lower left blob around the origin. So I added 2 there, which brings my total to 94 dog-age-human-age pairings.
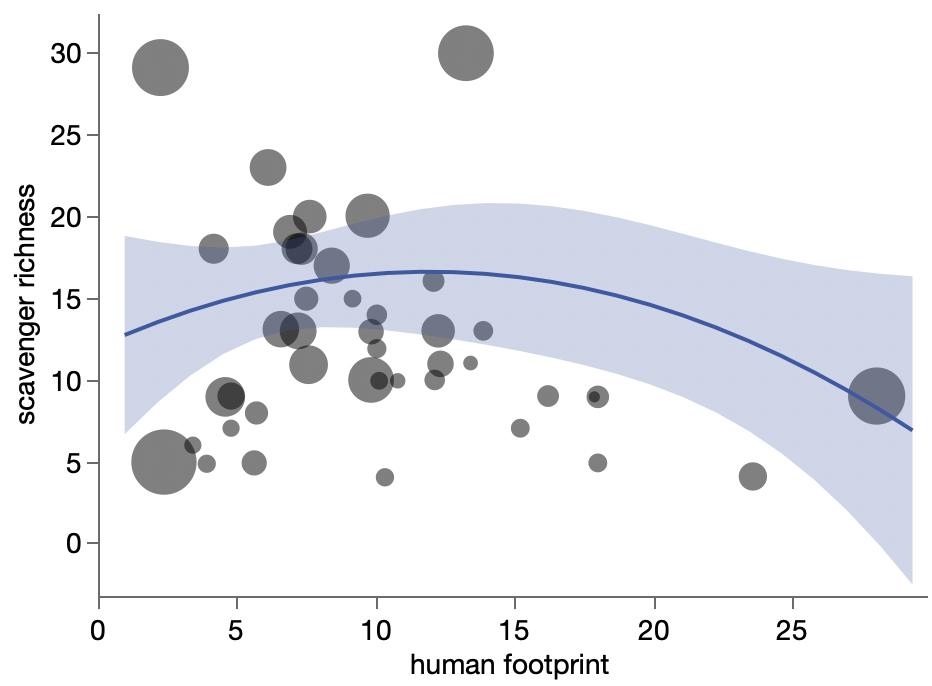
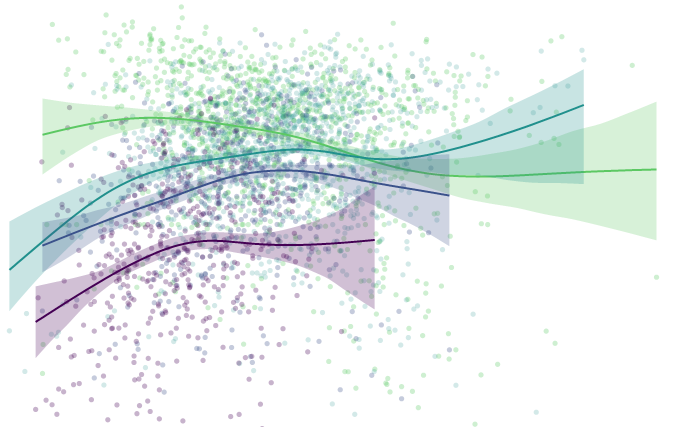
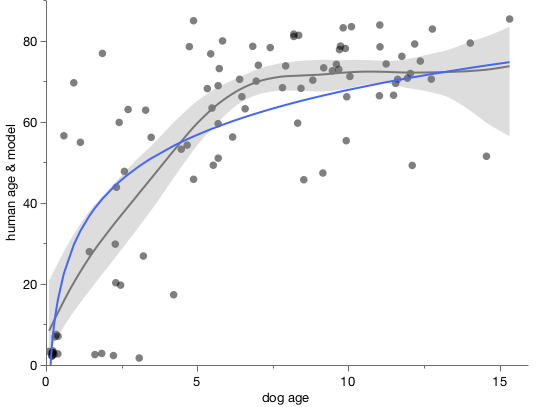
Here’s my data (gray dots) plus a smoother (gray line), bootstrapped confidence interval (gray region) and the paper’s epigenetic model (blue line).
A few oddities come to light from the graph:
The variation is much higher for young-aged dogs: some very young dogs get matching with very old humans. And some 2-3yo dogs get matched with human infants.
The smoother makes it looks like the underlying model is linear up to about 6 years and then levels off, which is surprising.
The smoother is by definition constrained to be smooth, and the log curve is even more constrained. Maybe it’s too constrained here since it’s not following the middle ages or the smoother confidence interval.
Human ages
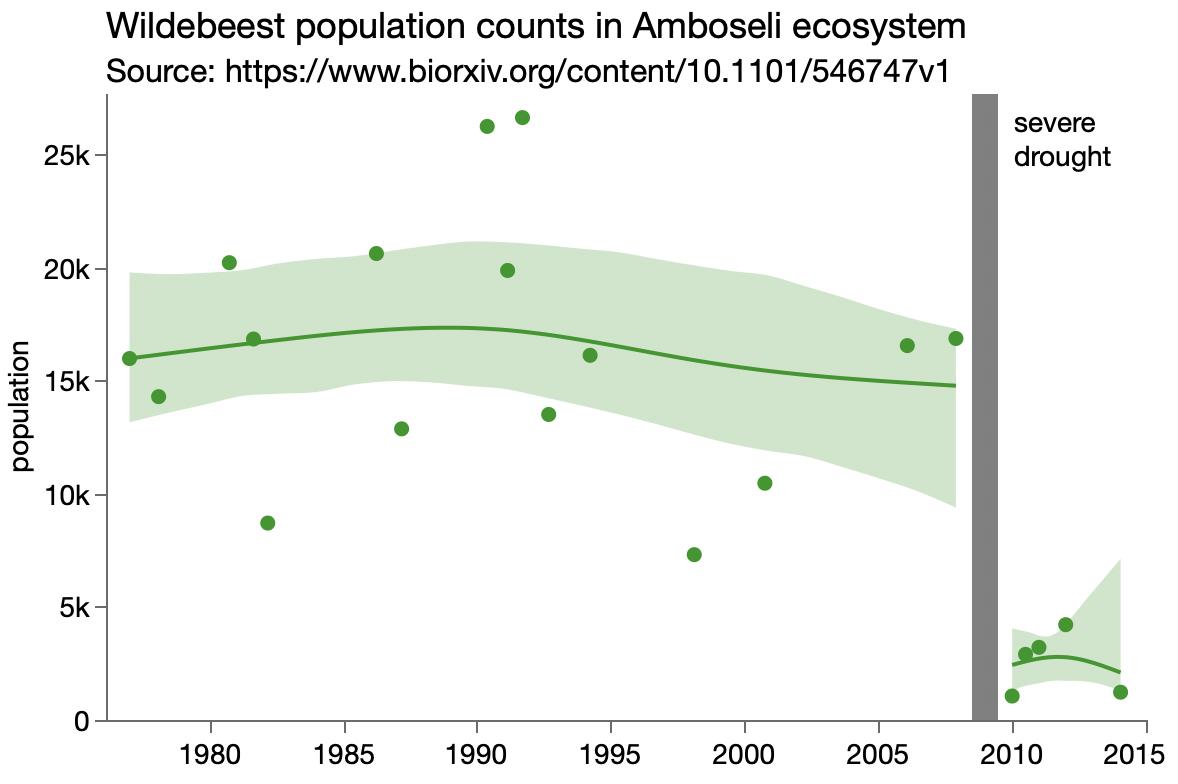
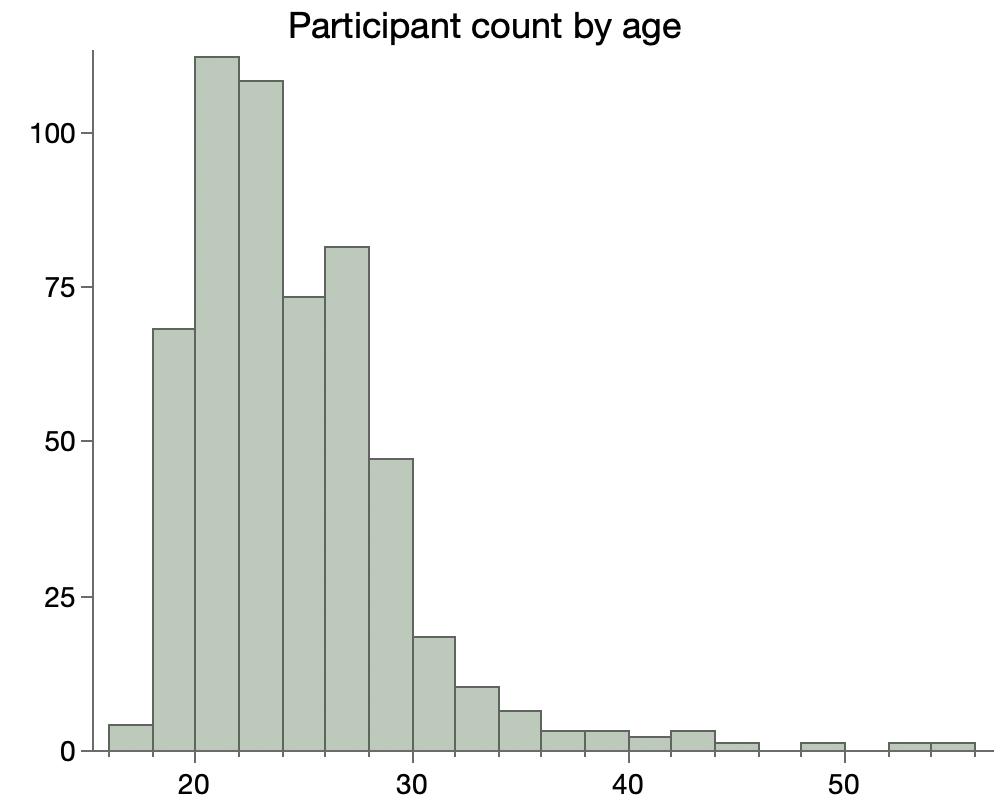
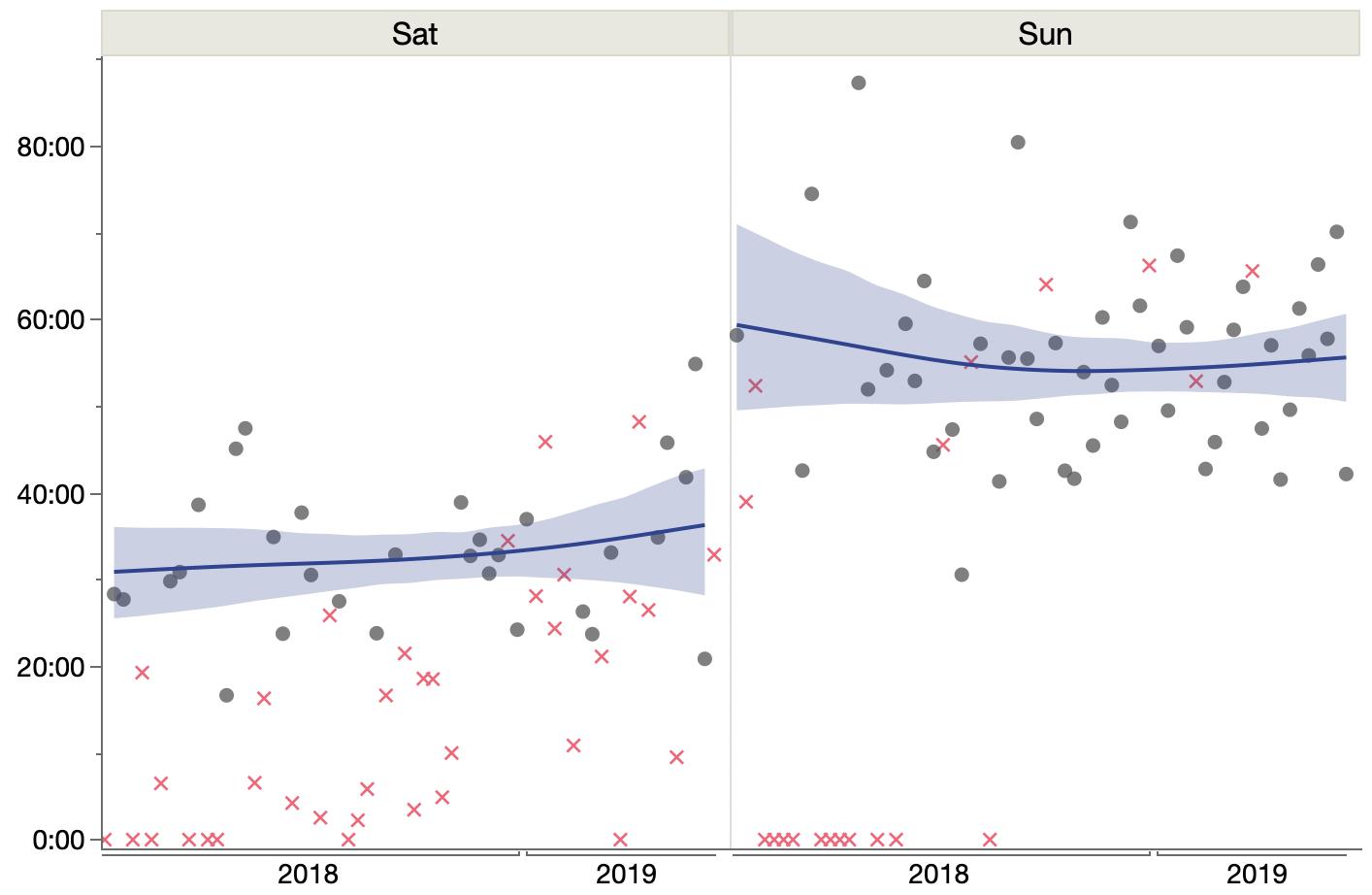
I think a big part of these oddities is the distribution of human ages, which again we have to infer from the graphs. The paper only says they had 320 human from 1yo to 103yo. Looking the their plot of dog age by human age, there is one dot per human. Too much overstriking to digitize the values this time, but it’s clear that the ages are strongly bimodal with relatively fewer subjects in the 10yo to 50yo range.
Digging a little deeper, the paper cites two sources for the human data. One source has data for humans age 17yo and younger, and the other is mostly older humans, as shown by this histogram from that paper:
So with few mid-life humans to match with, it’s not surprising that mid-life dogs would match to young or old humans (but mostly old humans since there appear to be more of them). As a result, I suspect the paper over-estimates the epigenetic age of mid-life dogs, which is in agreement with the deviation from the WebMD table of dog-human ages.
Fitting a log curve
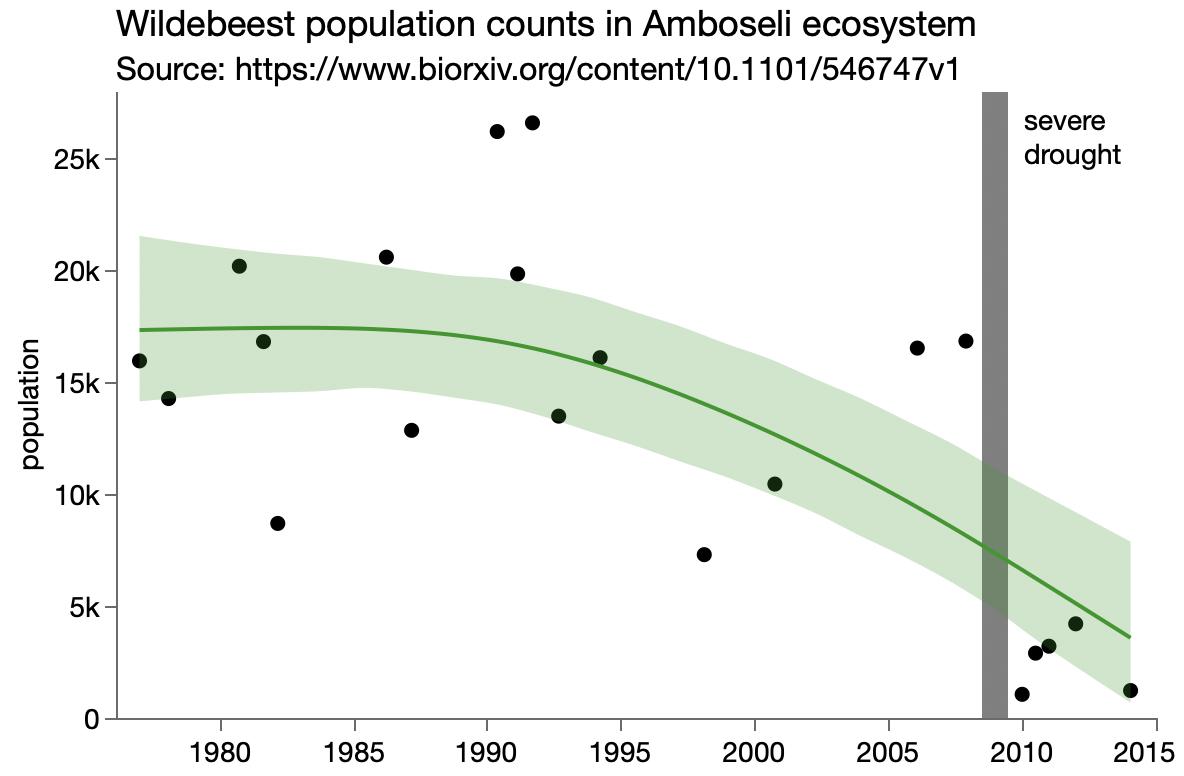
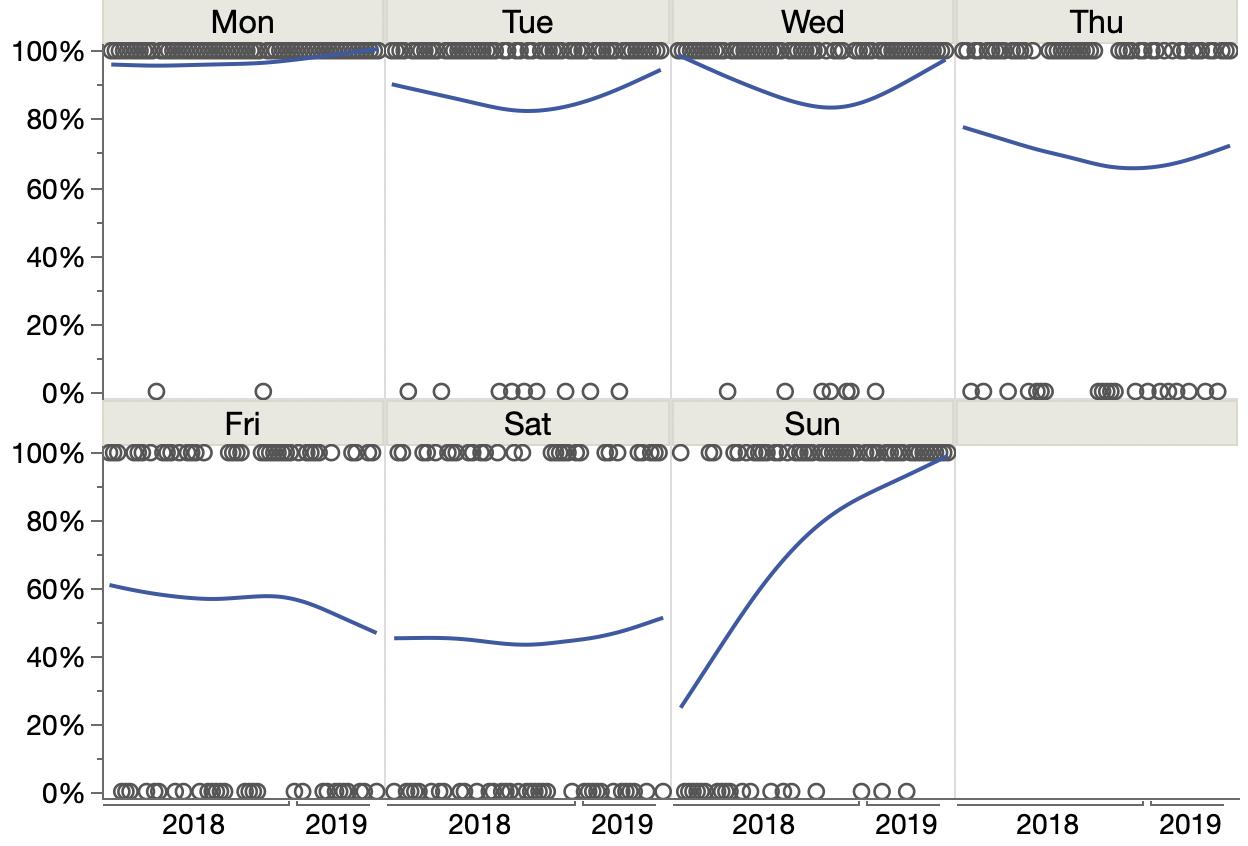
Fitting human age as a logarithmic function of dog age is equivalent to fitting a straight line function against the log of dog age. However, if we plot human age versus dog age on a log axis, it doesn’t exactly call out for a straight line fit.
Though the dog ages have a fairly uniform distribution, taking the log skews the distribution to match the human age distribution.
I was going to try a few other models, but since I’m now having serious doubts about the quality of the dog-human matching, there’s no use modeling it. This is a good time to point out that the most likely explanation for my doubts is that I’m an idiot and haven’t spent months with this study like the authors have.
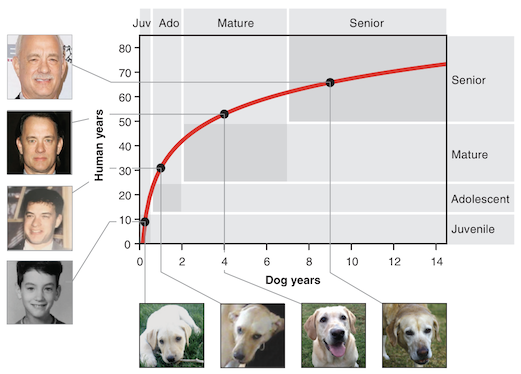
Physiological Age
From the paper, regarding the logarithmic function:
We found that this function showed strong agreement between the approximate times at which dogs and humans experience common physiological milestones during both development and lifetime aging, i.e., infant, juvenile, adolescent, mature, and senior.
Wang et al., Quantitative Translation of Dog-to-Human Aging by Conserved Remodeling of the DNA Methylome, Cell Systems (2020), https://doi.org/10.1016/j.cels.2020.06.006
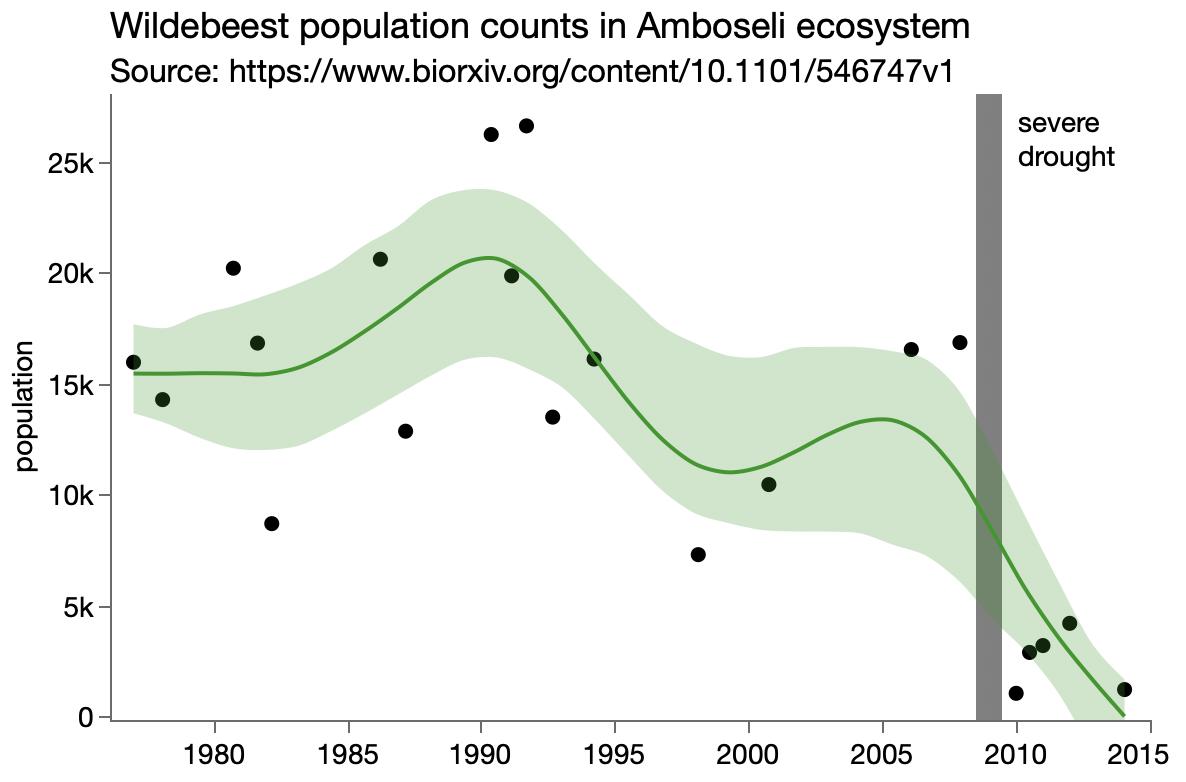
The following chart is used to support the “strong agreement”:
However, it’s not very convincing to me. The model almost completely misses the adolescent and mature physiological regions, and given that you can’t possibly miss the two corner regions with any reasonable model, I’d say the model scores zero out of two for predicting physiological age.
Interestingly wording note: the article says that the correspondence in the middle stages is “more approximate” which I guess might be a positive spin on “wrong”.
Simple Model
I was initially excited to see this paper touting a dog-age formula based on DNA data, but now I’m doubting the results due mainly to the skewed human age population. So for now, I’ll stick with the expert wisdom summarized in the WebMD article. If you’re looking for a simple formula, you can get close to that table with the formula:
One of first articles on the new investigative journalism site, The Markup, is about Allstate’s proposed changes to Maryland’s insurance premiums, supposed driven by an “advanced algorithm.” The Markup got the data and found a simple and embarrassing model behind the new proposals. However, the most interesting parts for me were in the companion “show you work” article. Not only are there deeper details about the analysis (with graphs!) but also a link to all the raw data and analysis files.
The main data file has information on premiums for 93,000 Allstate customers, and I’m going to focus on three variables, using names from the data file:
Current premium: what the customer was originally paying
Indicated premium: Allstate’s calculation of what the premium should be, based on a risk assessment. Called “ideal price” in the article.
Selected premium: what Allstate was asking for approvals as the new premium, based on the secret algorithm that would take many variables into account and move the new premium in the direction of the indicated premium. Called “transition price” in the article.
Distributions
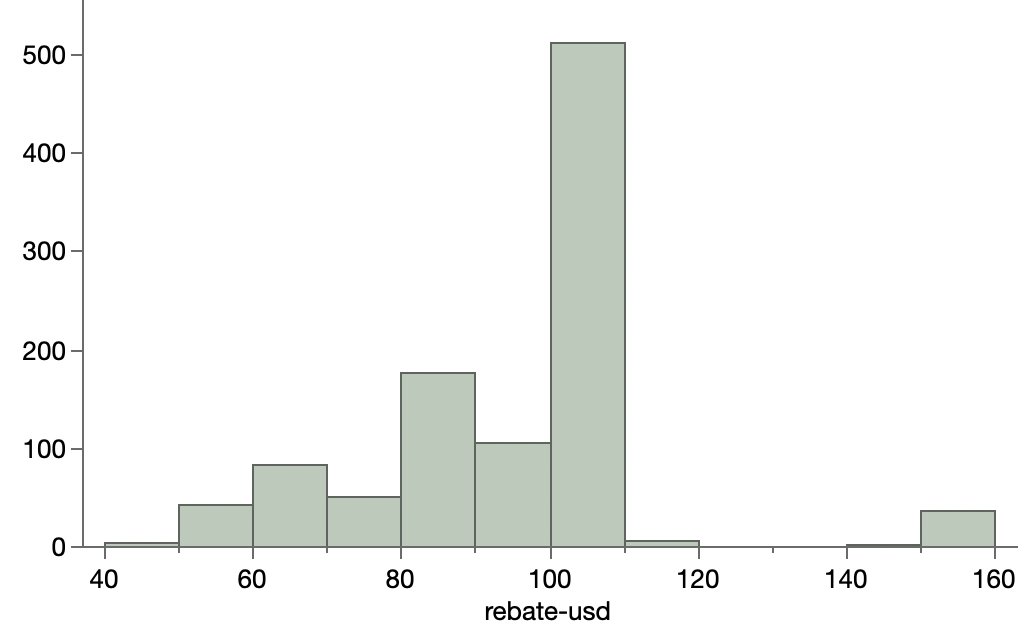
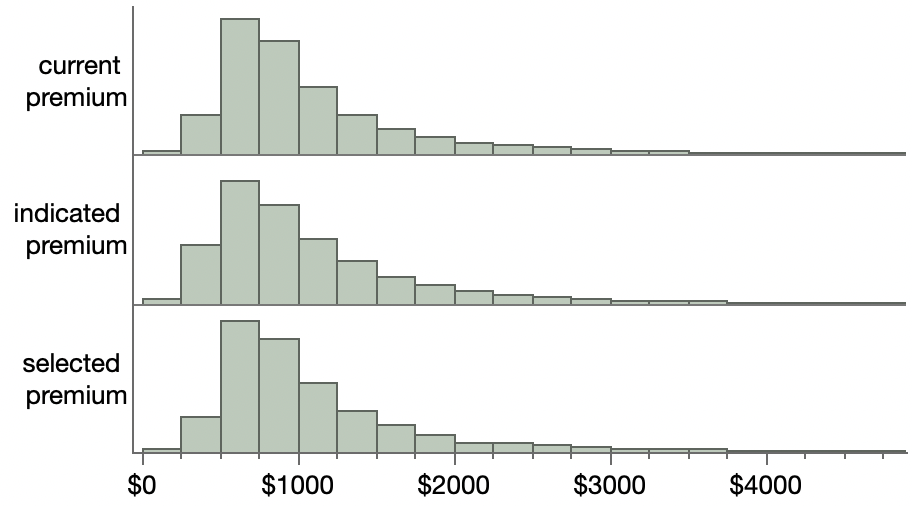
At first glance all the premium variables look pretty innocent. Here are the distributions.
I’ve truncated the axis so that a few outliers don’t distract from the core group. An important take-away to keep in mind is that most of the premiums (62%) are under $1000.
Looking at the difference between the indicated and current premiums also looks normal – about half the time the indicated values are less than the current values.
It’s when you compare the selected premium against the currentpremium that things start to look a little suspicious.
A couple things stand out: the differences are much smaller overall and they are skewed with the negative differences being even smaller. Many of the negative differences (about 10,000) are less than one dollar. Apparently (read the article) the small increases are for the sake of customer retention and the nominal decreases are to meet the promise of moving in the “general direction of the new risk model” aka the indicated premium.
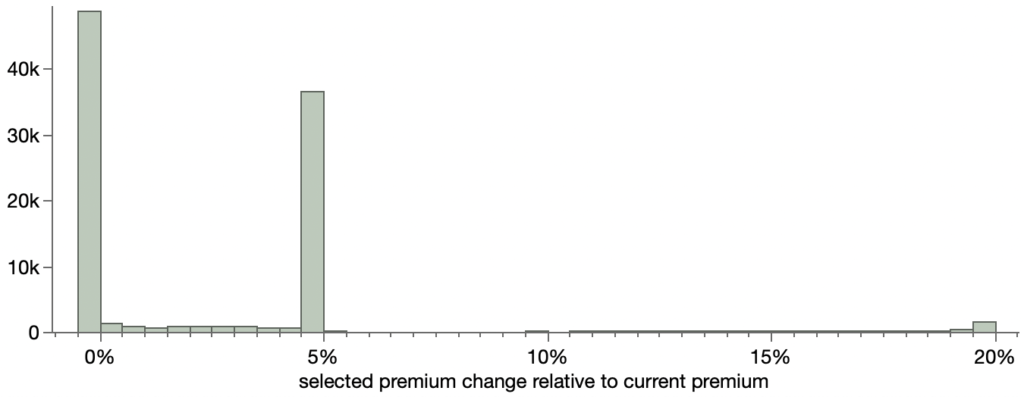
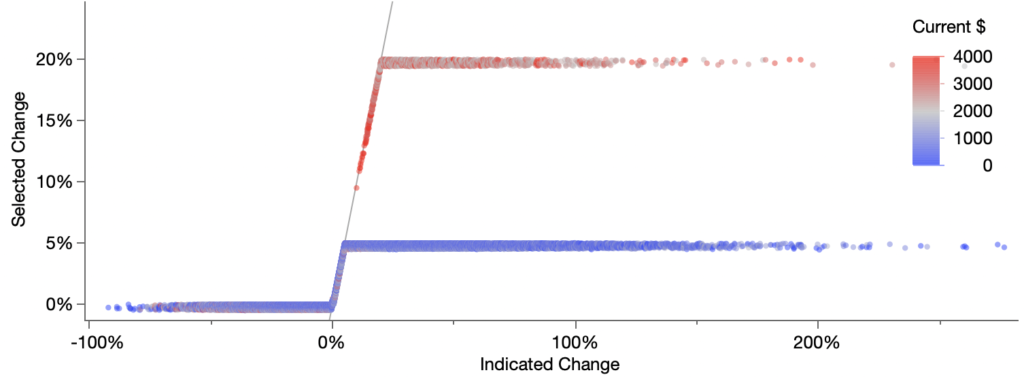
Looking at the selected change as a percentage of the current premium is where things start to get really fishy.
Almost all of the changes are around 0%, 5% or 20%. I think the 20% group is what the article refers to as the “suckers list,” but, as we’ll see next, those customers are actually paying less than their indicated rate suggests and the customers in the 0% group are actually the ones losing out.
Scatterplot make-over
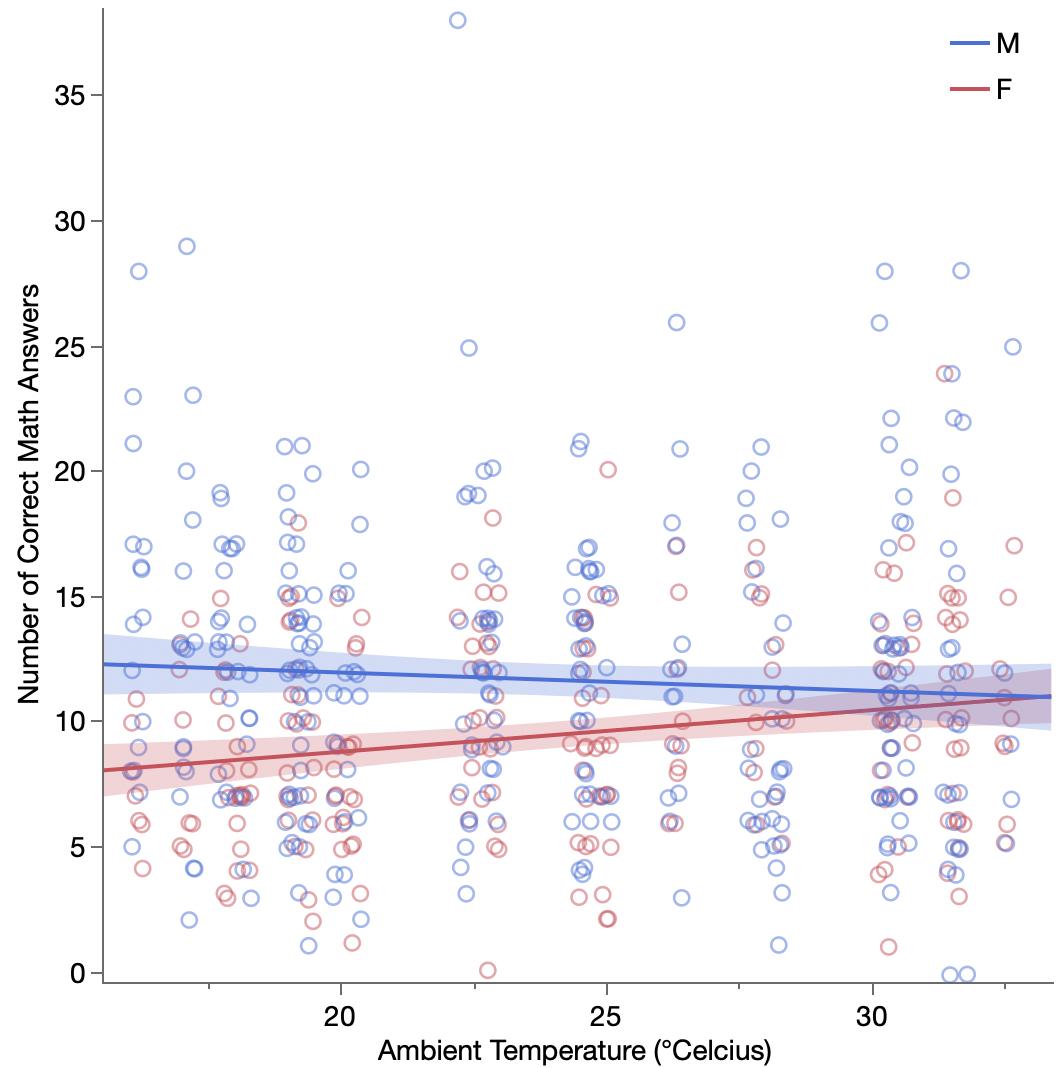
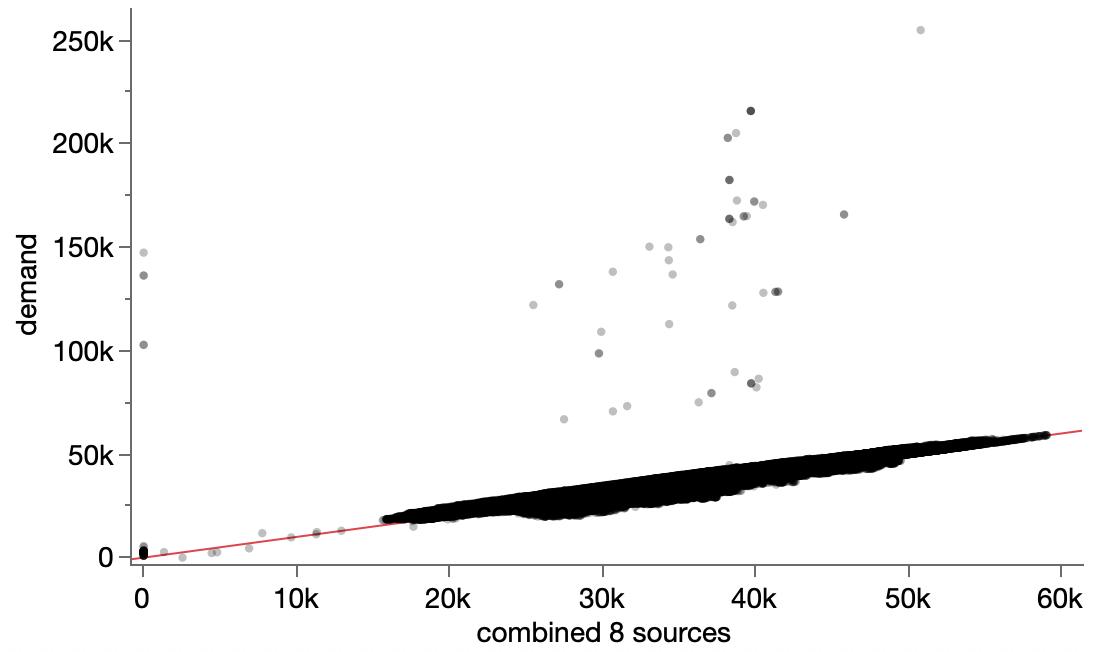
We’ve already gained a quite a bit of insight just from looking at distributions of the three variables and their differences, but what I was really after when I started was to find a better multi-dimensional view of the data. Even though there are only three variables, it’s not easy. I think the terminology is part of it, which may be why The Markup invented their own terms. In their “show your work” article, they modeled selected premium as a function the other two variables. Their model looked really good from a p-value perspective, but that only means it was definitely better than nothing. They shared this graph using the residuals from their model.
I can tell it’s showing something important, but I’m not sure what. (Interestingly, it almost looks like a smoking gun.) I know the residuals shouldn’t have any pattern, but I find it hard to translate the pattern I’m seeing back to the original data in my mind.
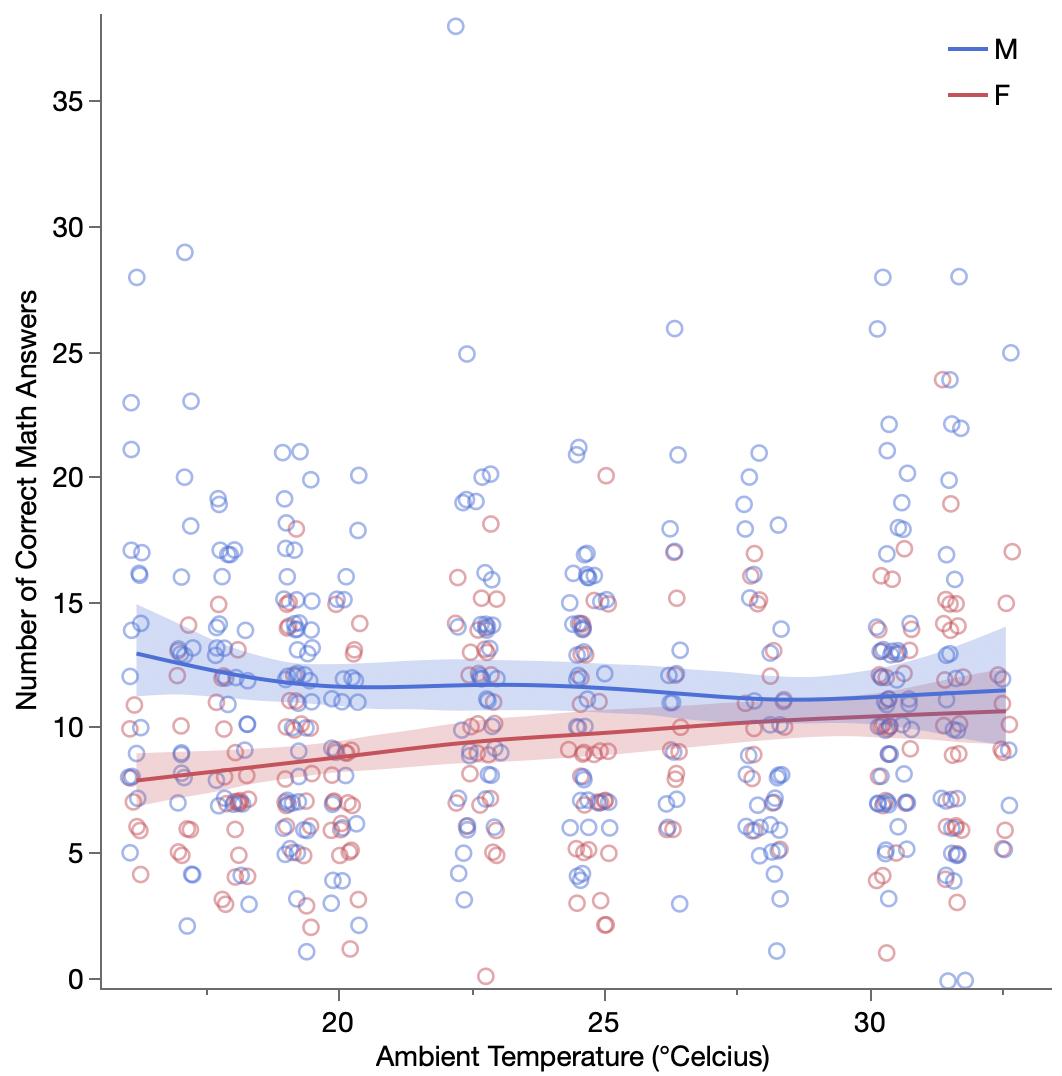
I started looking for more direct representations (without involving the model) so get the equivalent insight in plainer terms. I ended up with this graph, which still needs some explaining.
Compared to the original, I’ve replaced residuals on the x axis with the indicated change, as a percentage of the current price. In theory, the selected change would be some function of the indicated change. I’ve added a gray diagonal line to show where the selected change equals the indicated change. So we see the clusters at 0%, 5% and 20% as we did in original scatterplot and in the earlier histogram, but now we can see how they relate to the indicated change, including for the values not in those clusters.
I’ve also colored the points by the current premium, partly to link the relative values to absolute dollar amounts and partly to confirm The Markup’s finding that mostly high-dollar customers were put into the 20% group.
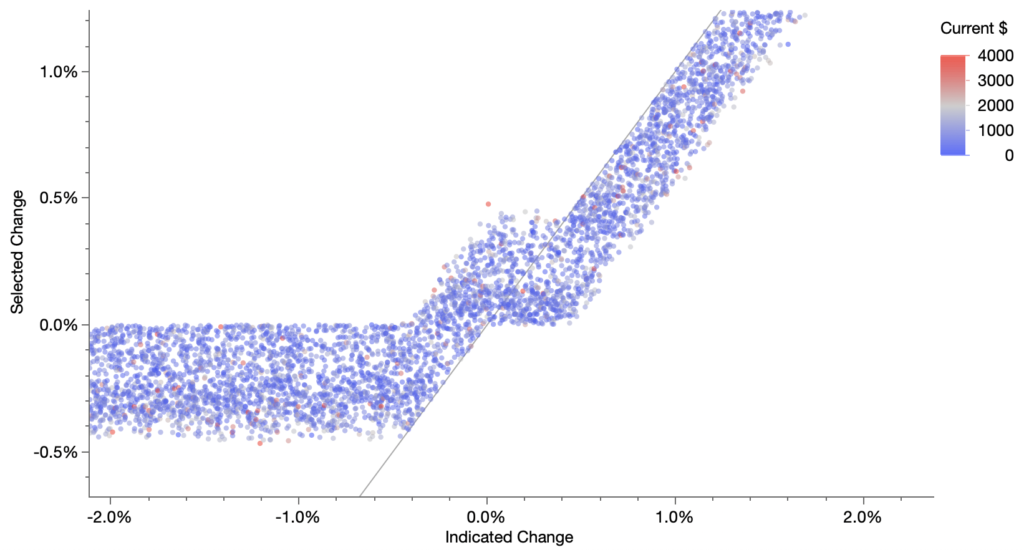
The pattern is so stark, you may not believe it’s a scatterplot, so I’ll zoom in.
And again, showing the 0% and 5% connection.
And once more, right around the 0% bend. It’s interesting how the points look randomly jittered within 0.5% of the target, but these are the actual values. Also, I have no explanation for the little jig around 0%.
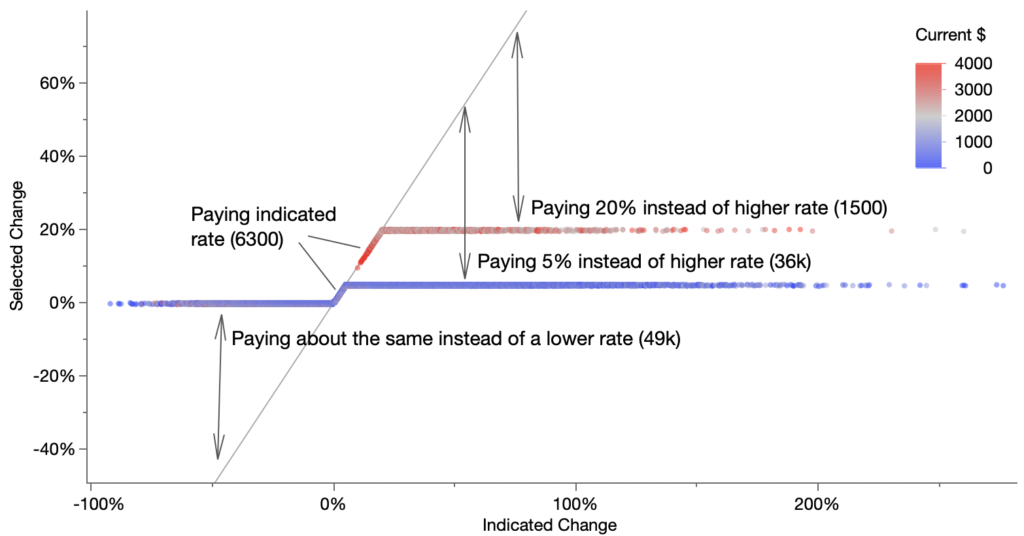
What does this scatterplot show us? Here’s an annotated version, zoomed out.
Dots above the diagonal line have a selected premium more expensive than the indicated premium. That is, they would be paying more than they merit (according to the indicated risk model). The annotations call-out four groups:
The left-side group at 0% (“decreases”) are missing out on a larger discount. This is the largest group.
The right-side group at 5% (“small increases”) have a selected premium with smaller increase than is merited, for the sake of retention.
The right-side group at 20% (“large increases”) have a selected premium with smaller increase than is merited, for the sake of retention. But because of their higher current premium than group 2, they apparently have a higher retention tolerance.
The group along the diagonal (not categorized in original article) have an indicated increase less than their retention threshold and have a matching selected premium.
You might look are this plot and think Allstate is being generous in charging less to all the customers in those long right-side groups. However, the number of dots doesn’t convey well when you’ve got 93,000 dots in a small space, even with some transparency enabled as I have done. The annotations include the counts to help a little. Here is a heatmap version, colored by the number of customers in each cell.
You can barely see some of the faint green cells that have under 1000 customers in them.
How to combine the count info and the current premium for each position? We could bin the x and y coordinates to get an aggregated group for each combination or rate changes and draw them as bubbles colored by the mean current premium and sized by the count.
Not bad.
Wrap up
There are plenty more angles covered in the article, including breakdowns by age, gender and location. I haven’t even gotten into sums. Interestingly, the sums of the increases and decreases almost exactly balance out. The more I think about it, it seems the articles got it wrong by saying the big spenders were on a “suckers list” because they’re getting a 20% increase instead of a 5% increase. They’re still paying less than they should and the savings are being offset by the real suckers, those who deserve a reduction they aren’t getting.
I hope others have taken or will take the opportunity to explore this data.
Meta
I have Allstate car insurance. I am not a statistician or a journalist or an actuary. All my graphs were made in JMP, which I help develop.
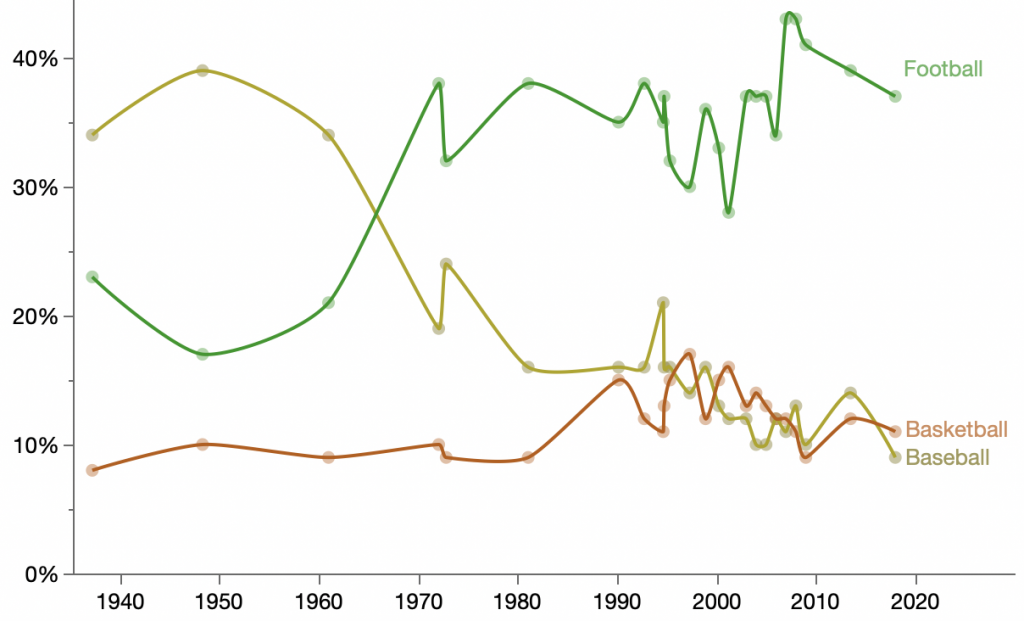
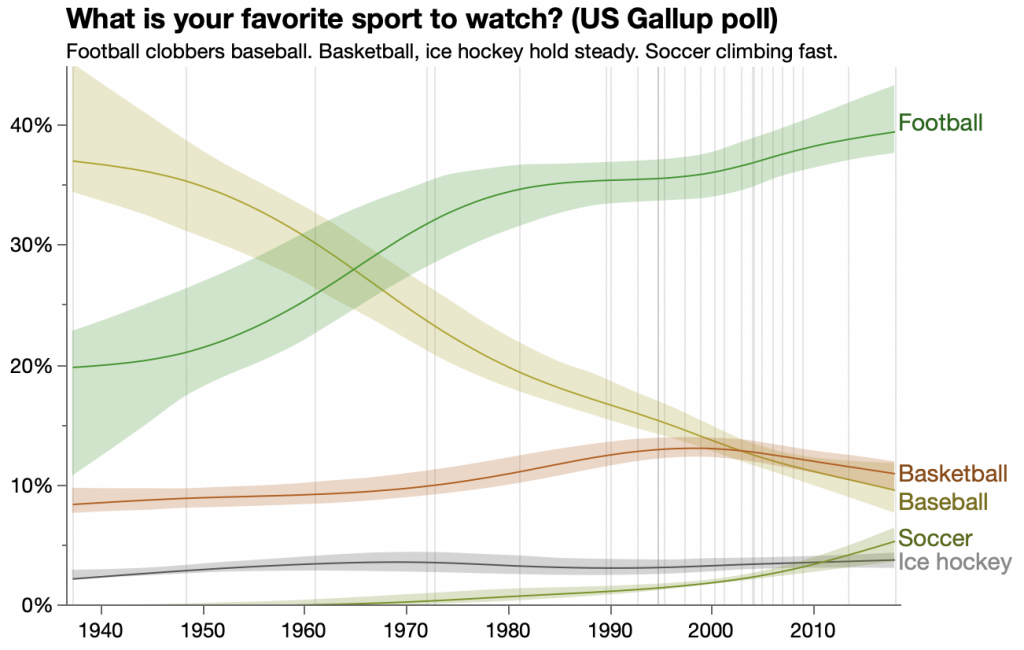
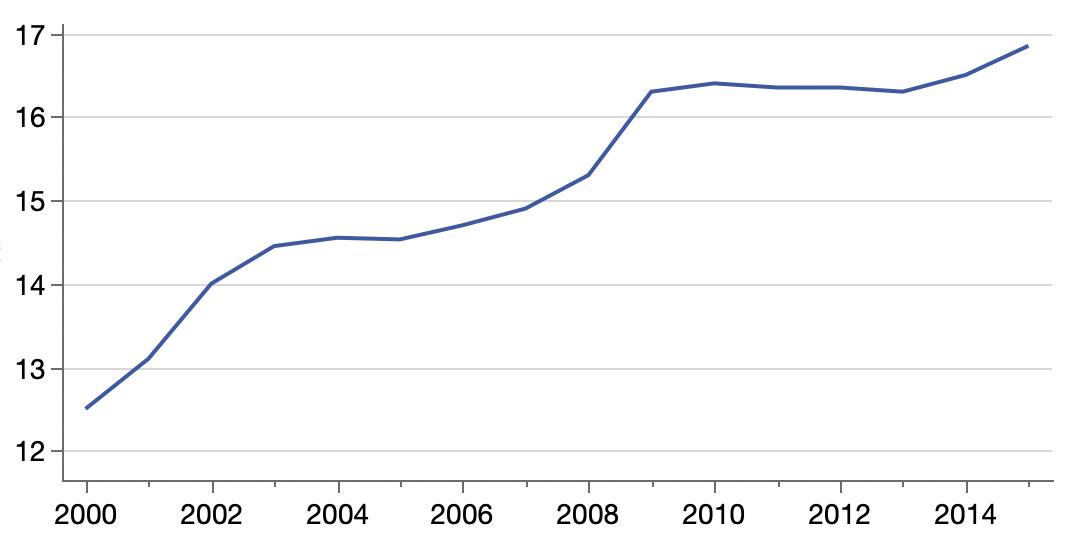
It’s been a year since my last official MakeoverMonday entry. I’m finally realizing that most if the action is for Sunday, so maybe I’ll do more this year. Week 1 for 2020 looks simple but it’s already confusing me. The task is to makeover this Vox chart from 2014:
The chart shows Gallup poll responses for favorite sports to watch over 70+ years for the three most popular sports (US only). However, the Makeover Monday data covers responses for 19 sports but only seven polls spanning 14 years. So perhaps I’m already breaking the rules, but I’m going to use the full data since it’s available on the same sourced page at Gallup. That includes only seven sports, but others are tiny and can be ignored for this makeover.
Review of the original
I like main design decisions of the original:
Showing trends over time
Dropping less popular sports to focus on the main sports
Smoothing the trend lines
Labeling the lines directly instead of with a separate legend
Trying to use semantic colors — I didn’t realize it until I tried to pick semantic colors myself: football fields are green; basketballs are orange; baseball bats are yellow.
Abbreviating the years so the x axis is not so crowded.
Oddities of the original:
Uneven amount of trend line smoothness
Y axis labels and gridlines are at 10% except, the top one is at 13%.
Labels colors don’t match the lines and are not quite aligned with the ends of the lines.
Putting the y axis labels above the ticks/gridlines instead of inline with them is not that uncommon, but it still takes me longer to parse the positions.
The uneven smoothness was the most prominent feature for me. At first, I read it as saying the change had been steady for decades before starting to fluctuate in the internet era. However, I realized it was more likely that the poll was conducted less frequently in the past, which is indeed the case.
Data exploration
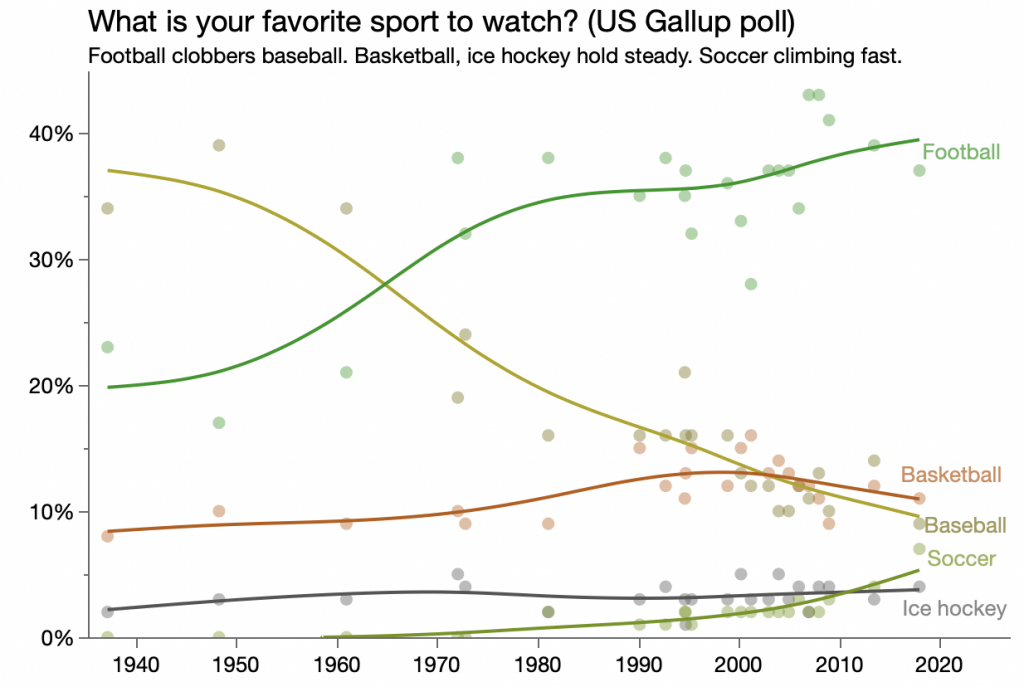
Continuing that thought, let’s look at all the data values for those sports. Here’s a remake using the same technique as the original, connected line with smooth connections, but also showing the data points.
This matches pretty well, except for 1972 and 1994 when the polls were conducted twice each year. It looks like the Vox author ignored one of the polls in each of those years. Also, the data I retrieved has an additions year of data (2017) after the Vox article came out in 2014.
Beyond the granularity, the shared data includes seven sports instead of three, adding ice hockey, soccer, auto racing and figure skating. Of those, only ice hockey and soccer had more that 2% of responses.
The dates are given as month/year values which distinguishes the multiple polls taken in some years. One year, 1997, the poll question was “What is your favorite sport to follow?” instead of “to watch.” The results weren’t that different, but I can imagine quite different interpretations.
Though I didn’t use the official 19-sport data set which only goes back to 2004, I noticed it also tallied responses such as “other” (about 5%) and “none” (about 13%). I can dream that ultimate frisbee accounts for a decent chunk of other, but unlikely. I’m sure it would be up there for a question on “your favorite sport to play.”
Graph makeover
I do think the long-term trends for the main sports over time is a good message, so I sought to show that while minimizing the recognized oddities. The most straightforward thing to do is a scatterplot and a real smoother (in this case a spline regression):
The data marks help communicate the irregular polling and variation but also add a bit of visual noise. I didn’t try abbreviating the years, and I didn’t put a lot of effort into lining up the line labels. One downside of attaching my labels to data points in the graph is that I had to expand the graph which means 2020 and beyond is now visible on the date axis. Not terrible but seems like a negative.
I added the next two sports for a fuller story and since soccer seems to be really gaining this past decade. And for some pedantic reason, I dropped the 1997 responses when the poll question had a slightly different wording. Didn’t want to have to add an asterisk to chart title.
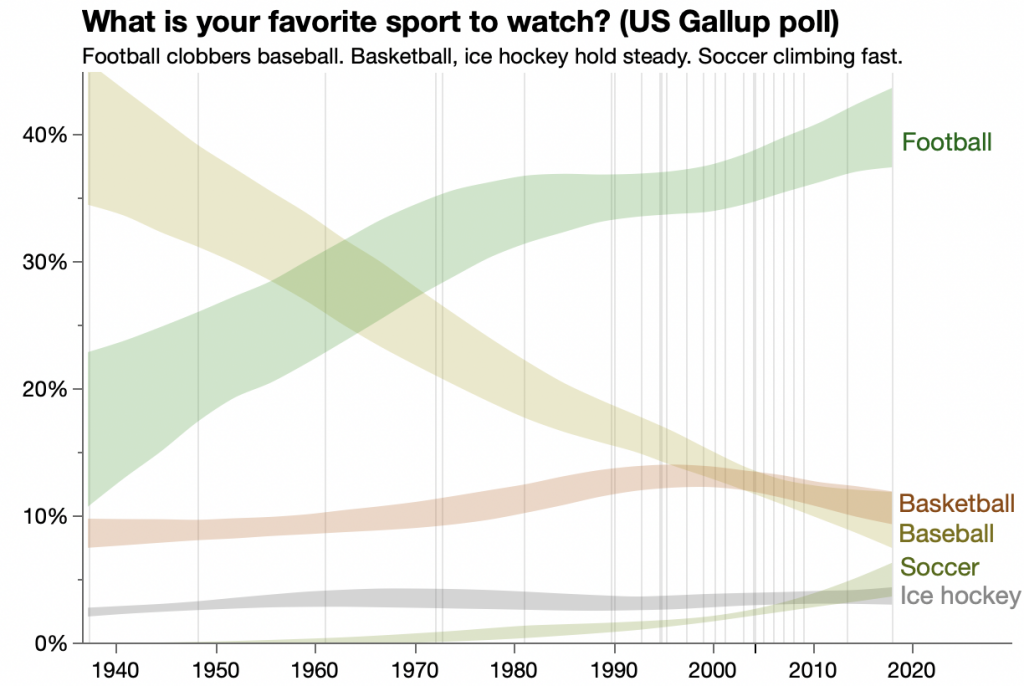
Another way to show the irregular polling would be to show vertical lines on the polling dates.
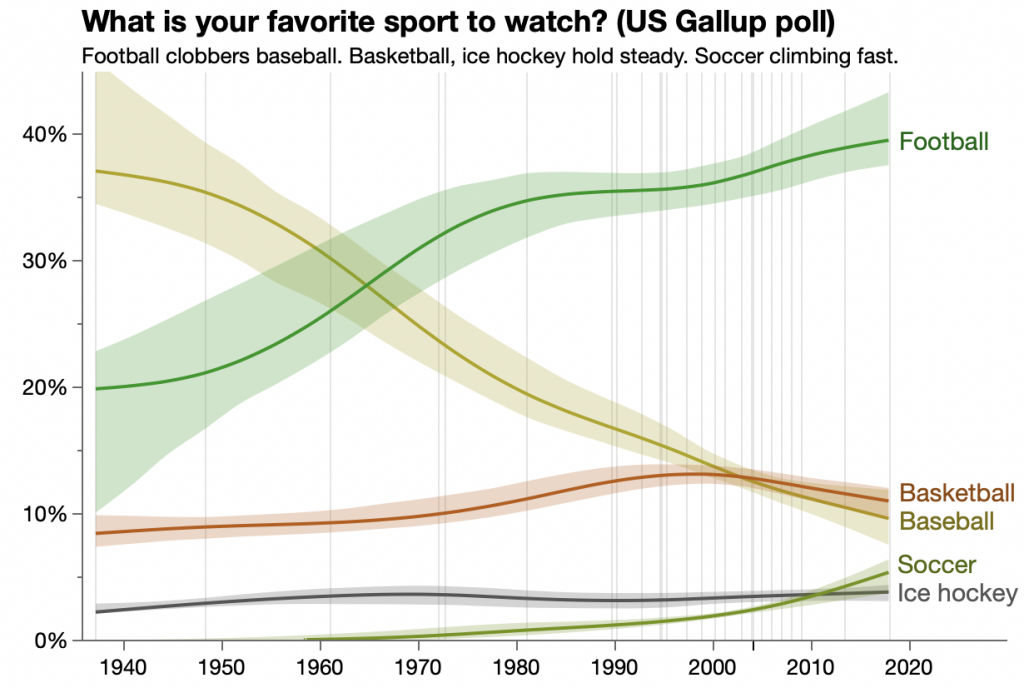
Not bad — I hadn’t really noticed how the frequency had dropped off in the last 10 years. We’ve lost any indication of the variation in the responses, though. We can get an estimate by adding a bootstrap confidence interval to the spline regression.
There’s some argument for only showing the confidence band.
Not sure I like that, but maybe I’m just not used to it. I’ll compromise and go with a thinner trend line.
For this last graph, I put a little more effort into lining up the line labels without extending the axis.
More data exploration
Though my chart has a small text summary in the subtitle, I don’t speculate on the why of the trends. The Vox article suggests the creation of the Super Bowl and modern NFL were catalysts for the shift from baseball to football. I imagine the rise of TV viewing was an issue, where football may be more accessible or more fun to watch with TV. And the recent rise of soccer in the US could be related to the rising Hispanic population, the success of the women’s national team, or just more internationalization in general.
The Gallup data also includes the month of the poll, which I showed in my charts as the 15th of the given month. One might also wonder if the popularity of a sport depends on whether the sport is in season or not during the poll. Unfortunately, there’s not enough data and month variation to read too much into it. Most of the recent polls have been done in December in the thick of football season. I did try a linear model with month as a separate factor, and a few month-sport interactions had p-values less that 0.001. For instance, the effect on football of polling around March is about negative three percentage points.
The end
I not even sure my work qualifies since I didn’t use the official data set, but I think I’ll submit the last chart above as my entry.
Here are 166 graphs I made and tweeted in 2019. There’s minimal commentary, and I copied them from my tweets rather than track down the originals, so not sure about the image quality. I omitted a few near-duplicates. All were made with JMP except where noted. Each image should be hyperlinked to its tweet (but I probably missed a few).
January
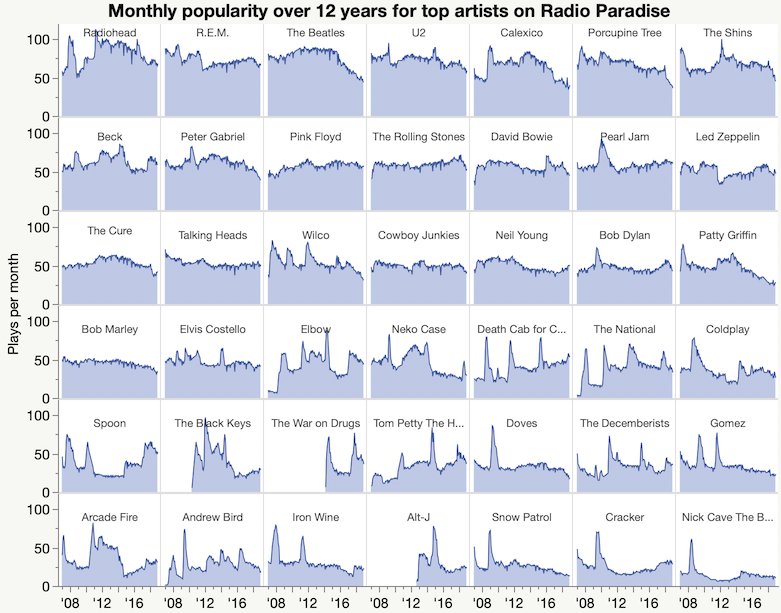
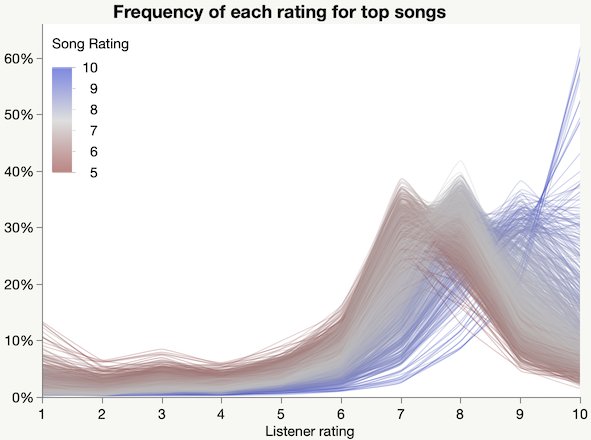
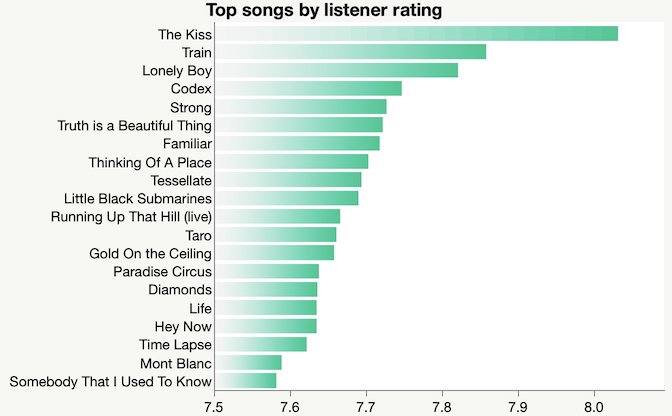
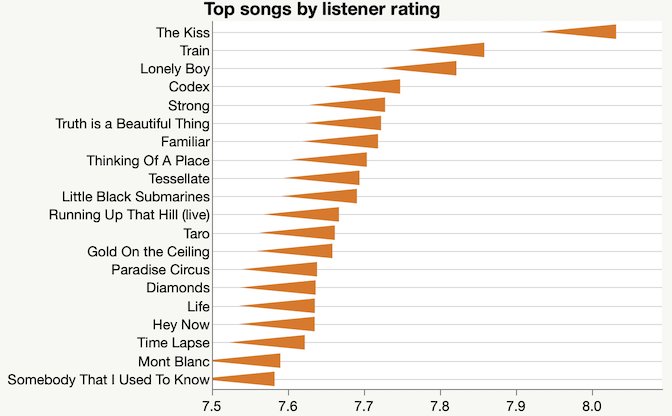
I started out 2019 with some data I collected from the Radio Paradise online playlist. This packed bar chart of artists is not a great fit for packed bars, which is a good sign for the radio station: it means the artist distribution is not very skewed.
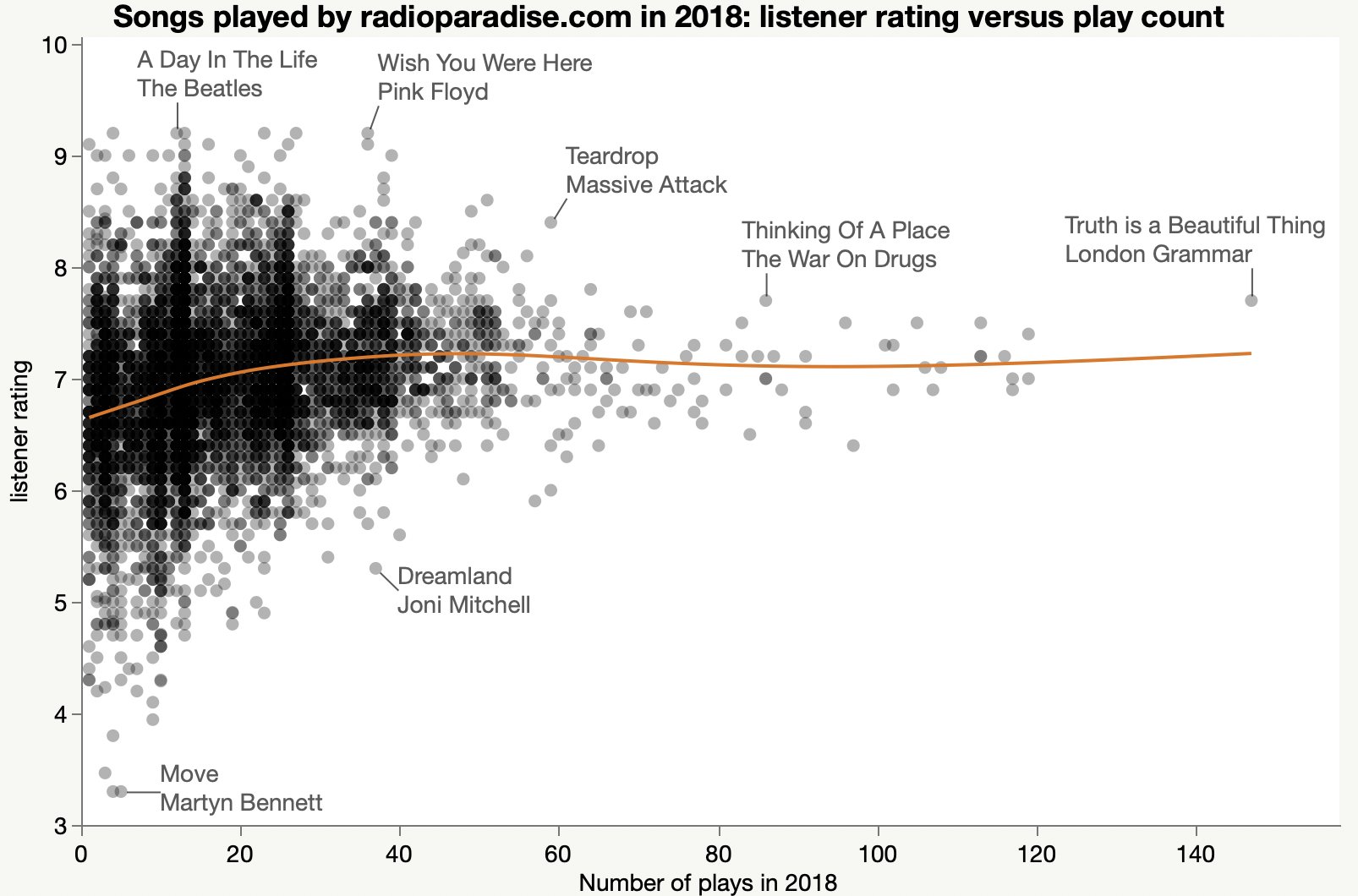
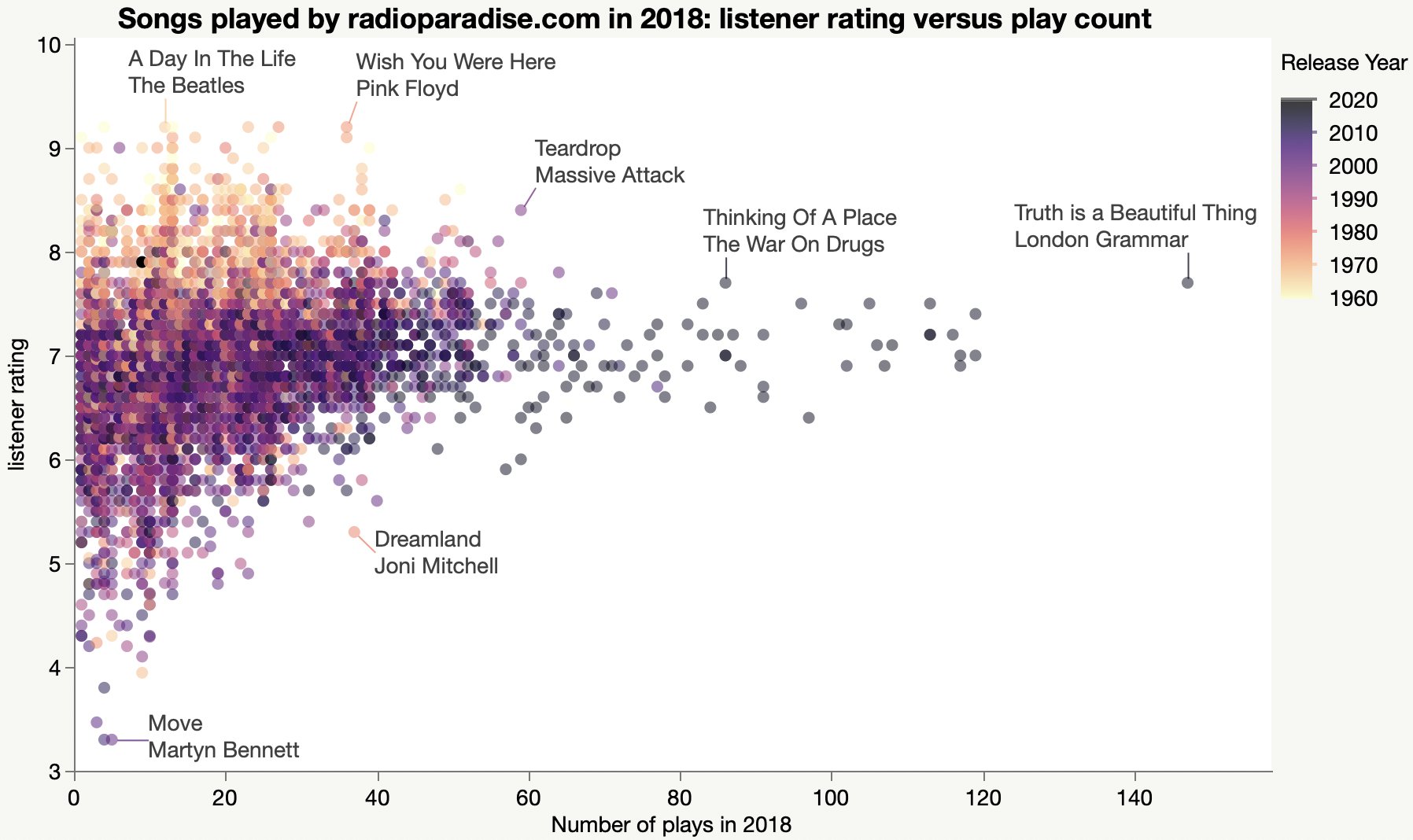
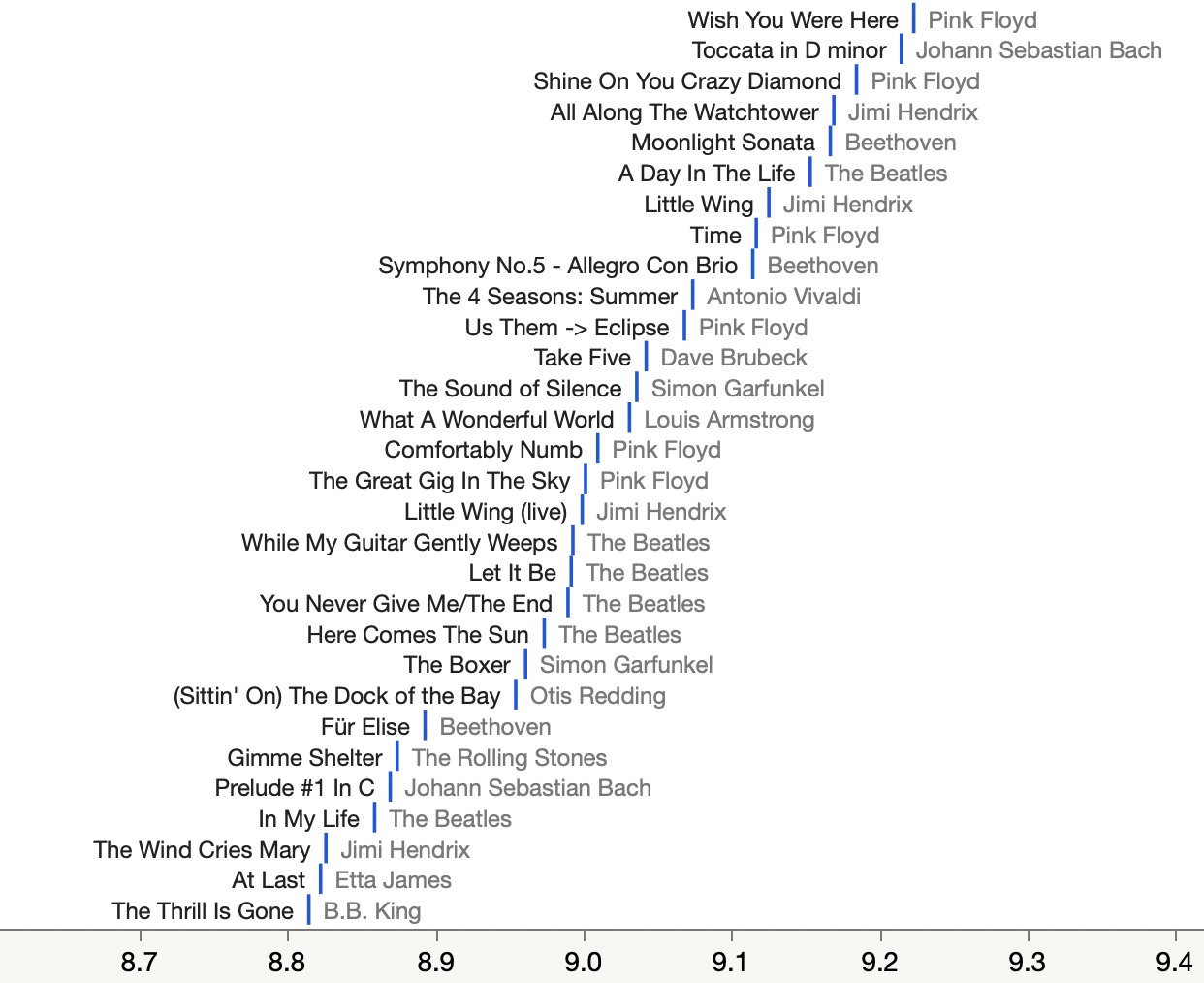
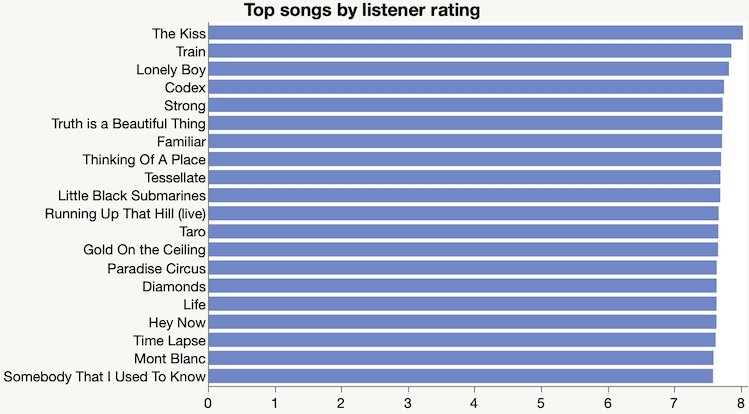
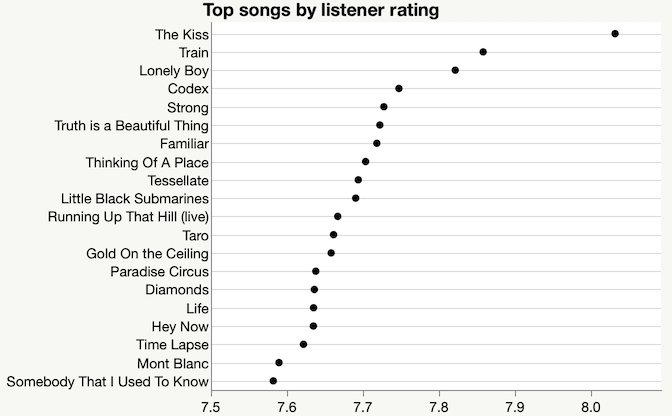
I also collected the song ratings, hoping to understand why they keep playing Joni Mitchell.
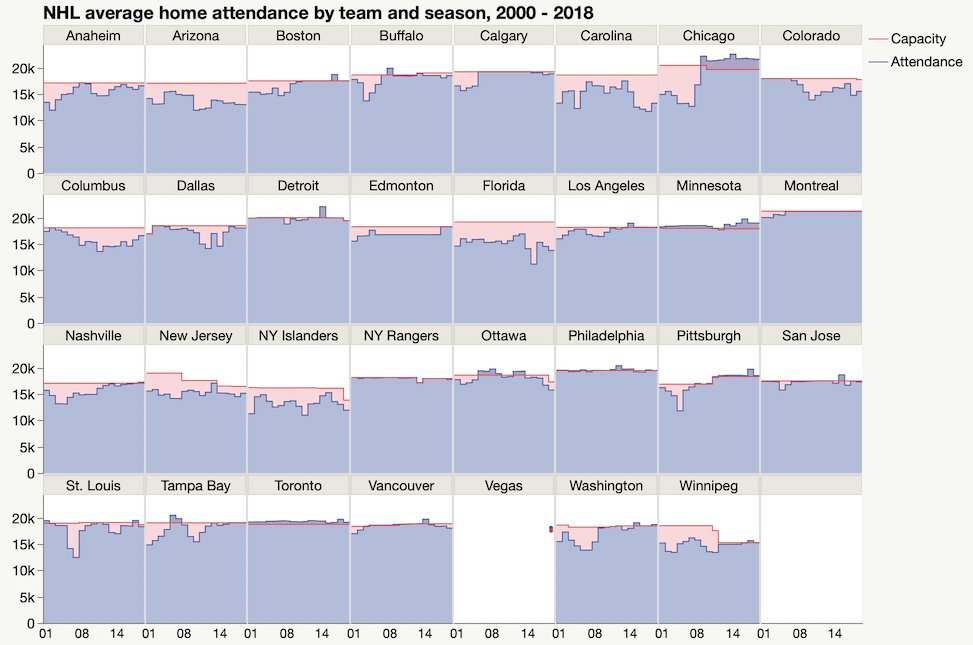
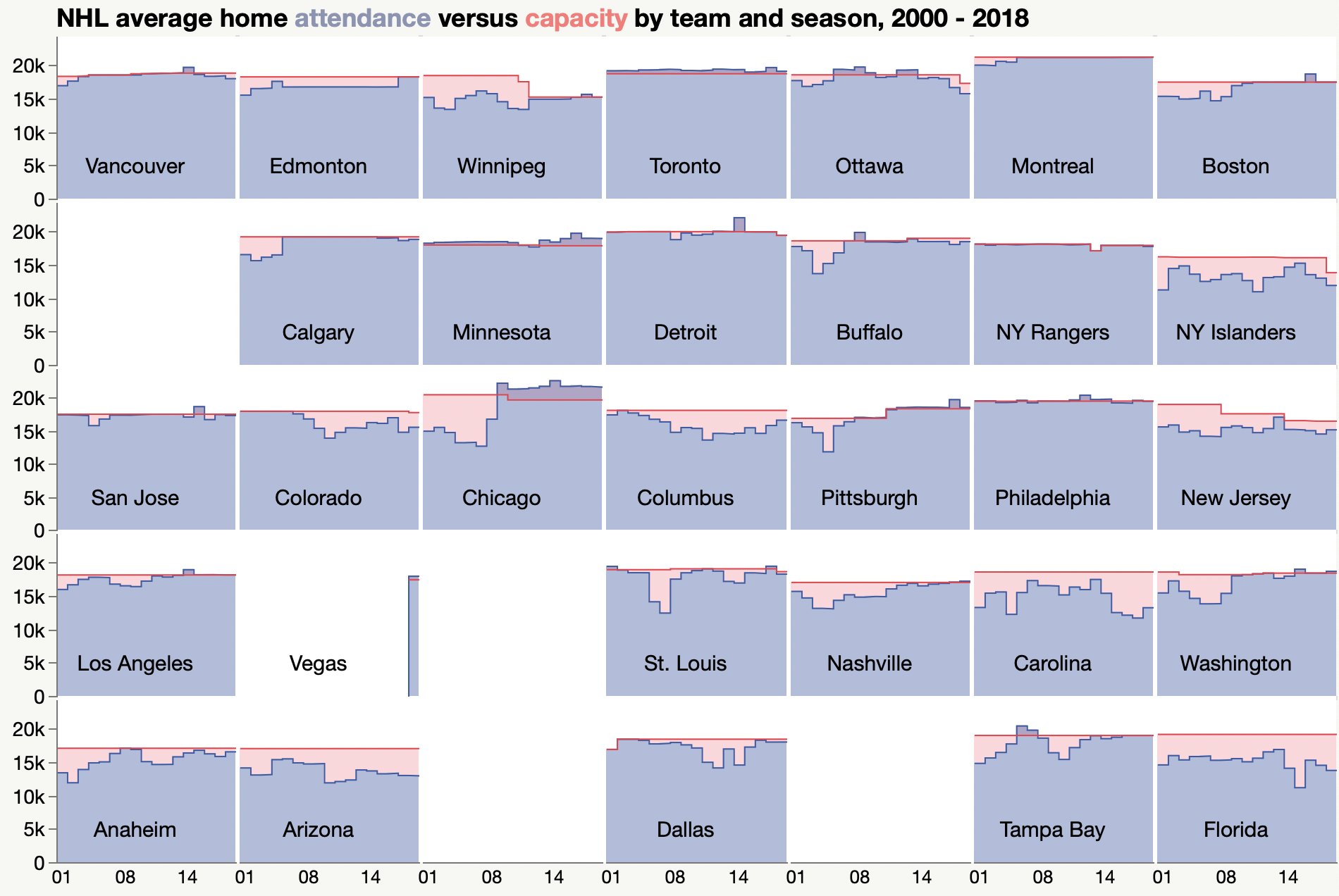
I tried a couple variations on hockey attendance data for #MakeoverMonday. I still haven’t figured out the right way to participate there.
More Radio Paradise data.
Trying a few alternative ways to compare two small distributions.
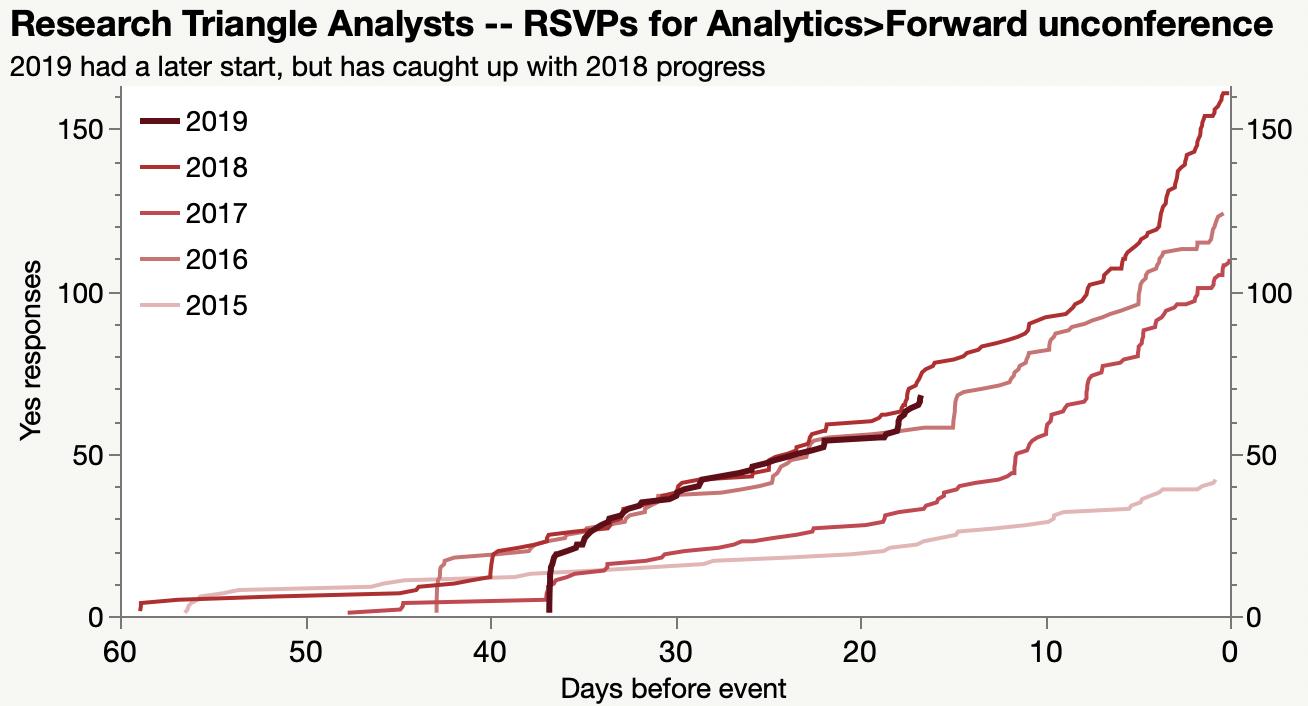
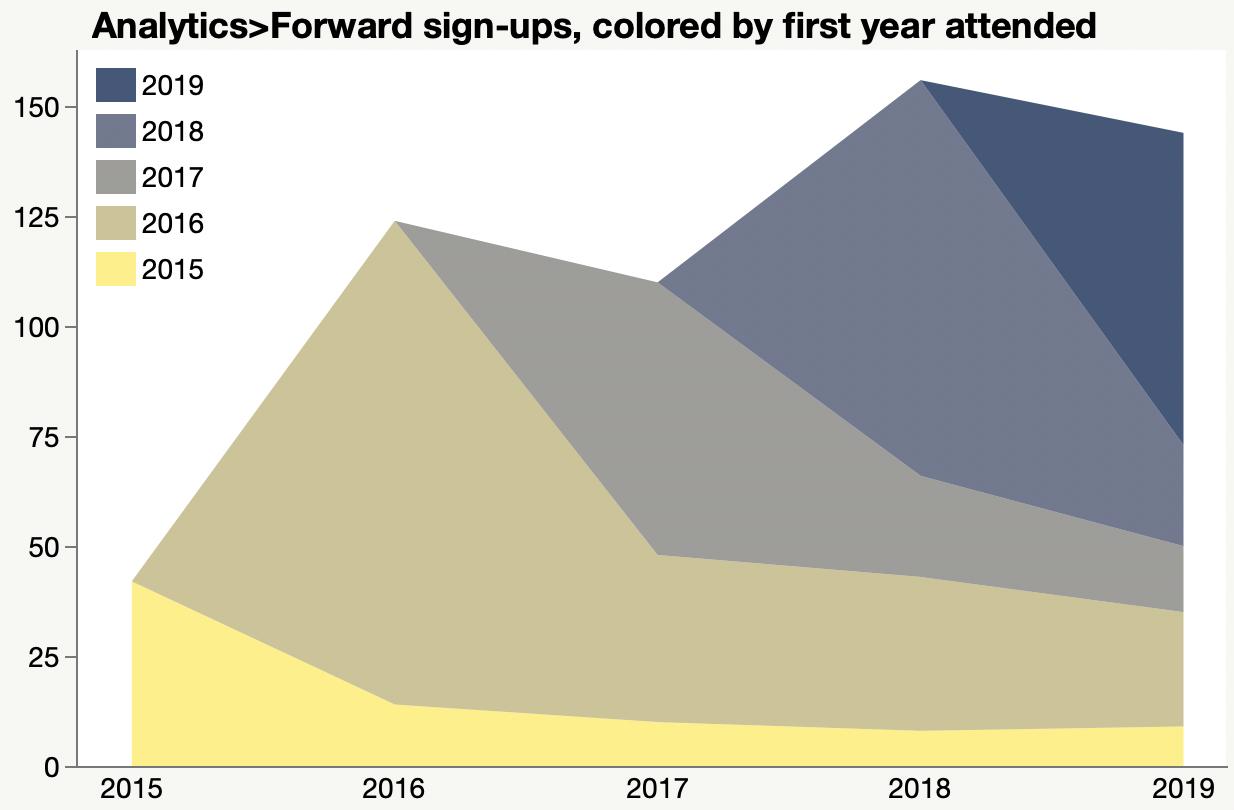
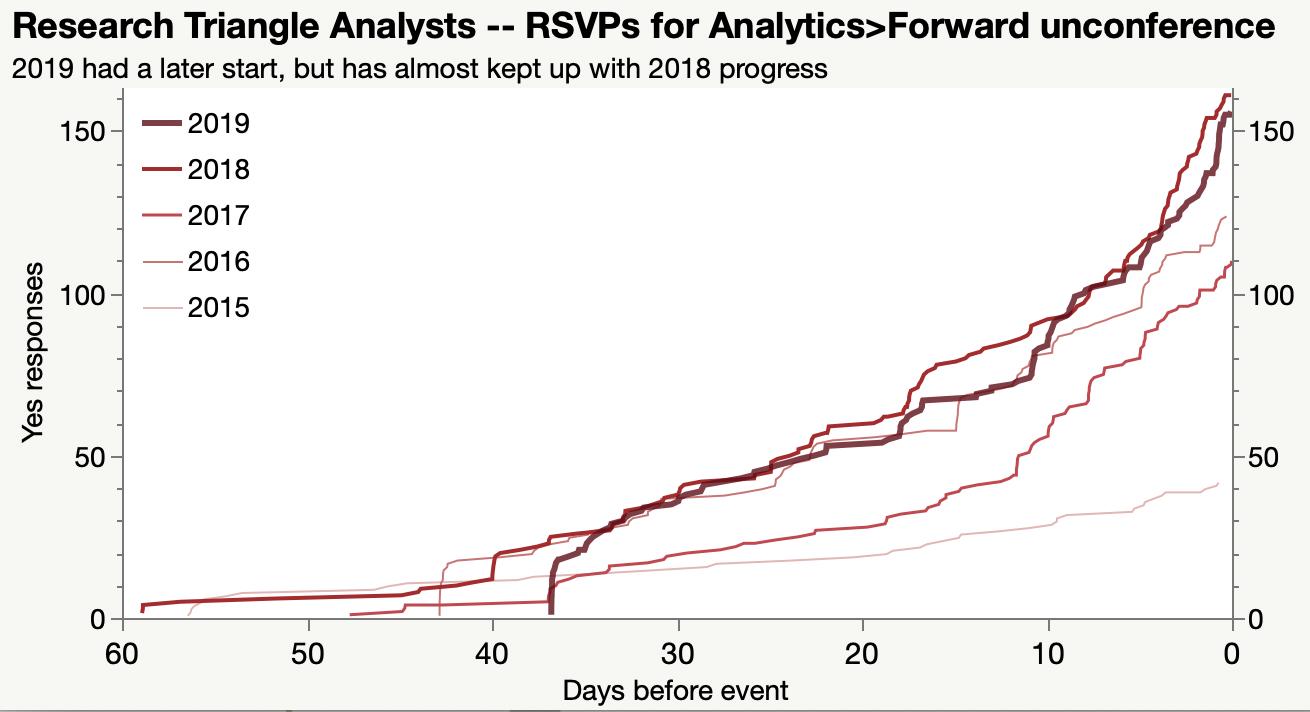
A couple final Analytics>Forward attendance charts.
My full submission for the #SWDchallenge.
Remade a pie chart grid as a heatmap.
Trying a static view of one of the bar chart race data sets.
April
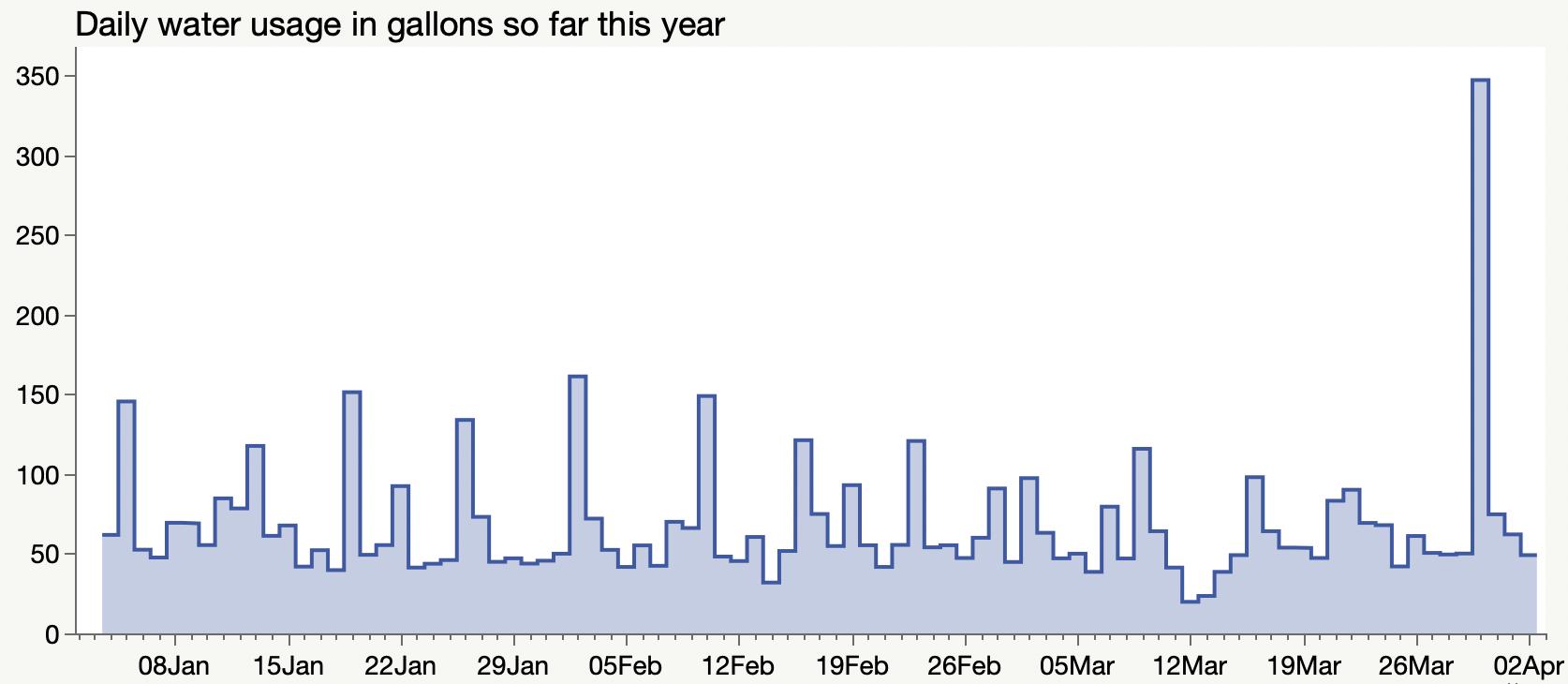
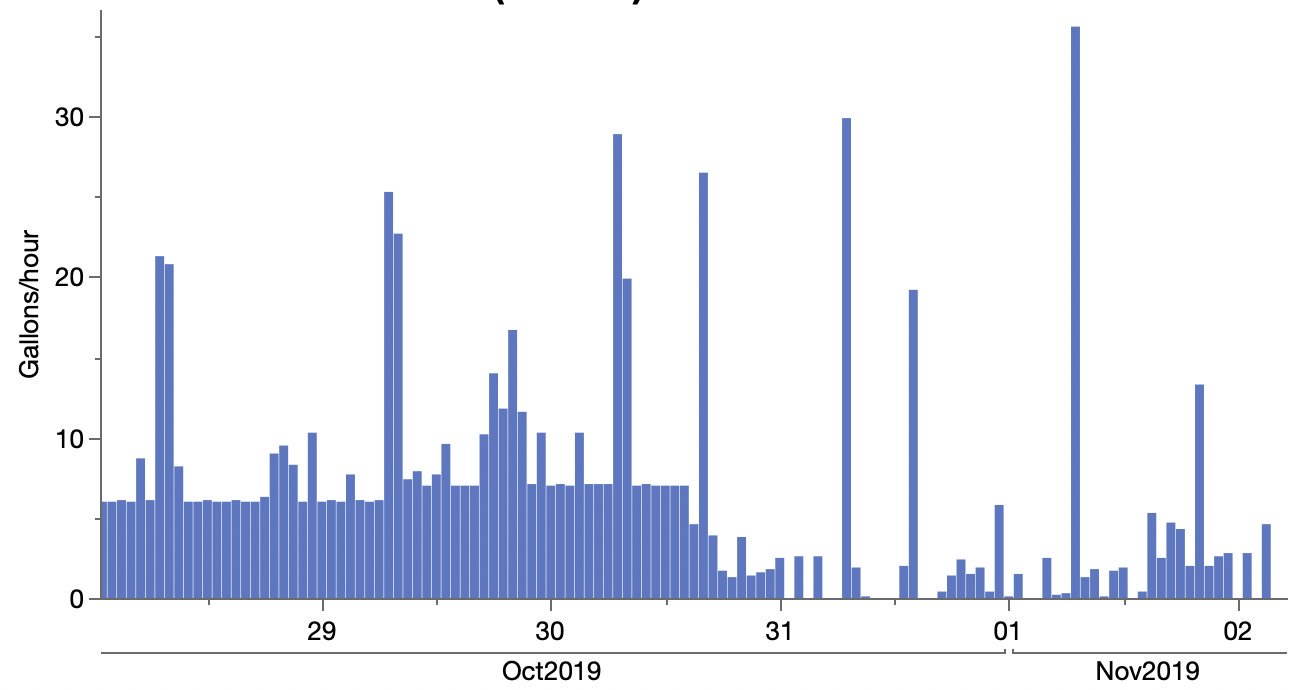
I discovered I could download my water usage data.
I made an Observable notebook for making packed bar charts.
Trying to reproduce a strange regression line in a NYT graphic. This proved to be a rich data set and would later become the example data for my JSM interactivity presentation.
May
Another radar makeover.
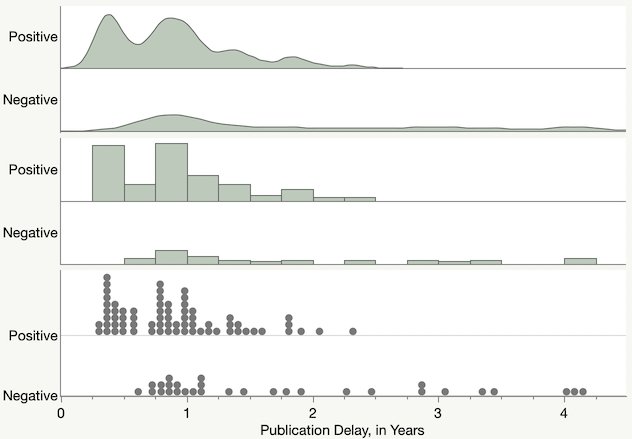
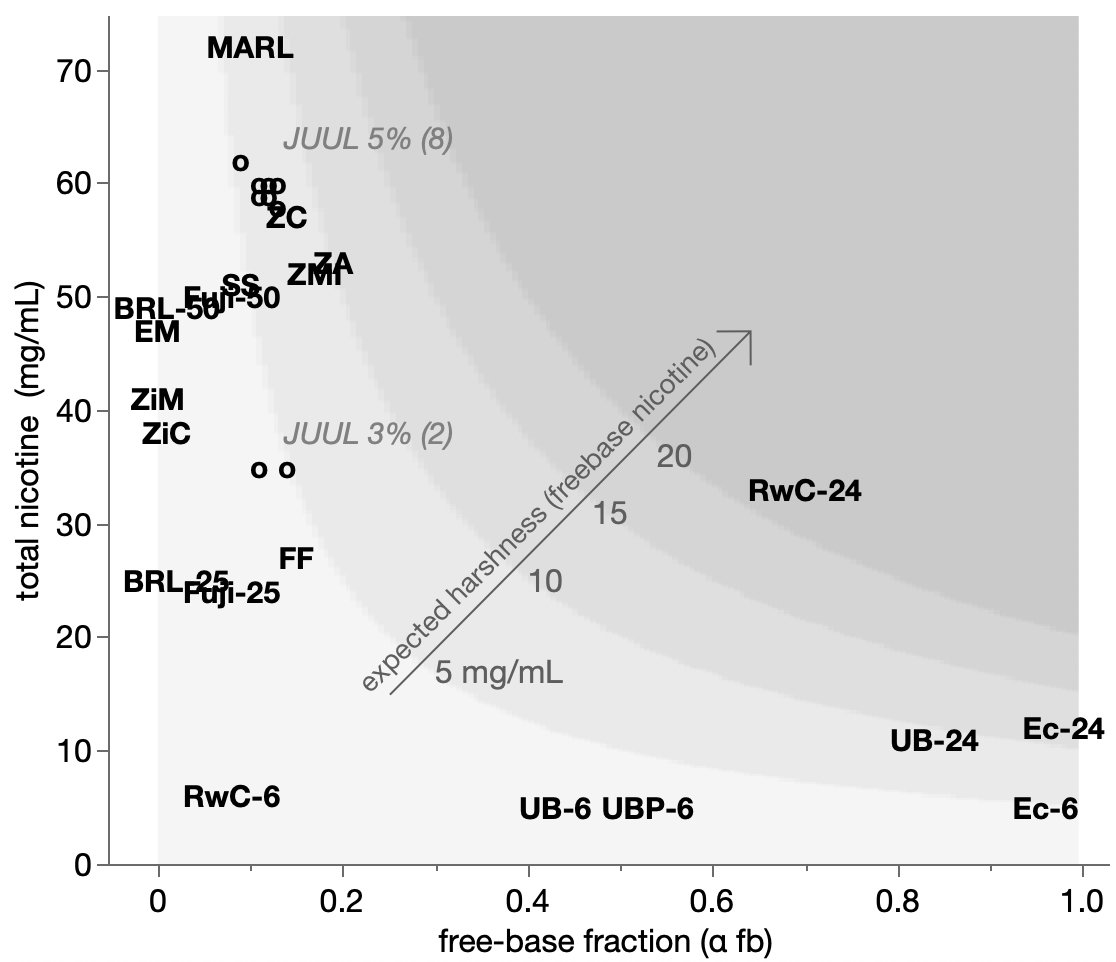
Trying to remake a suspicious journal plot.
Makeover of some soccer league rankings.
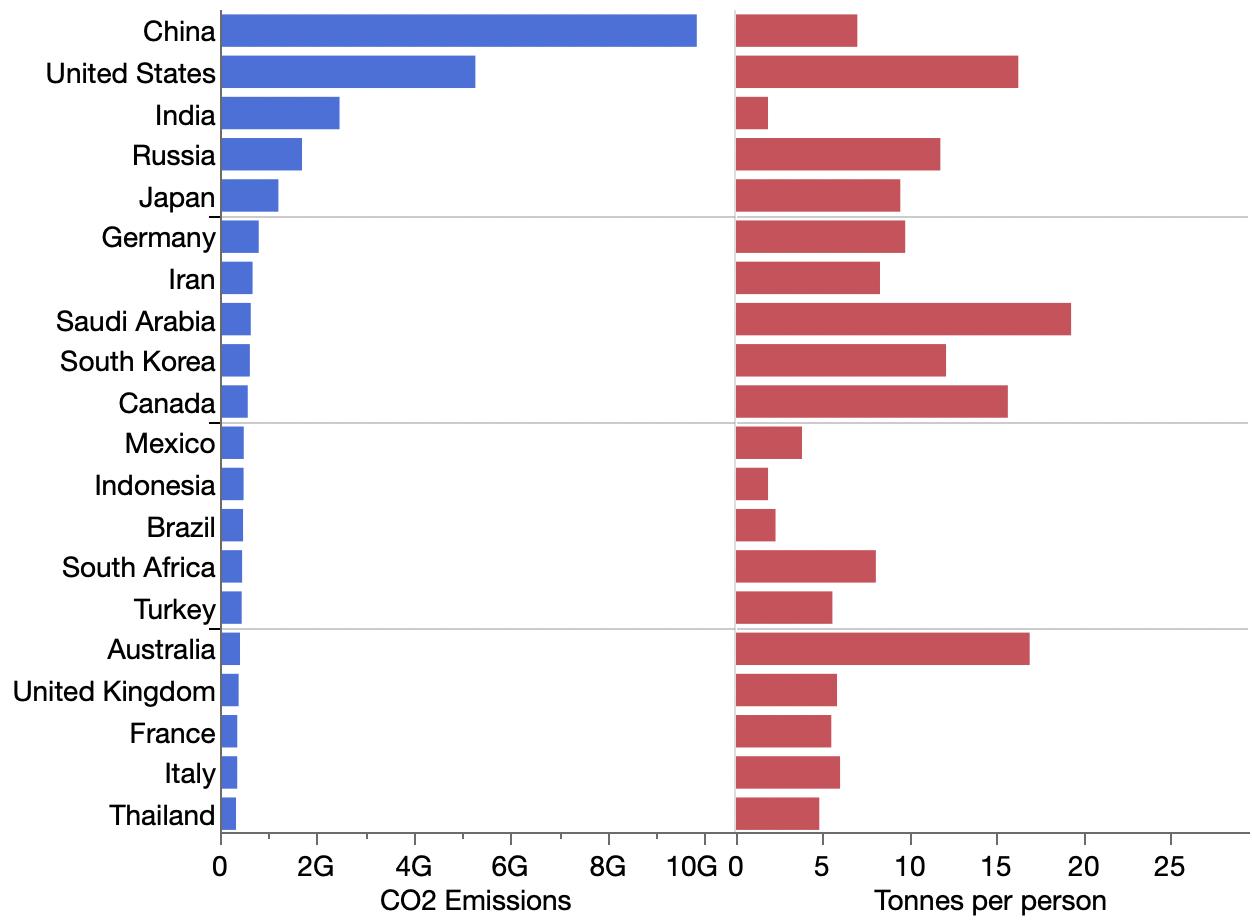
Carbon-dioxide emissions are so skewed you can see the top five and all the other countries packed in the same graph.
With some effort, I was able to collect my crossword puzzle solving times. I later made good use of the data in my JMP 15 keynote segments in Tucson and Tokyo.
June
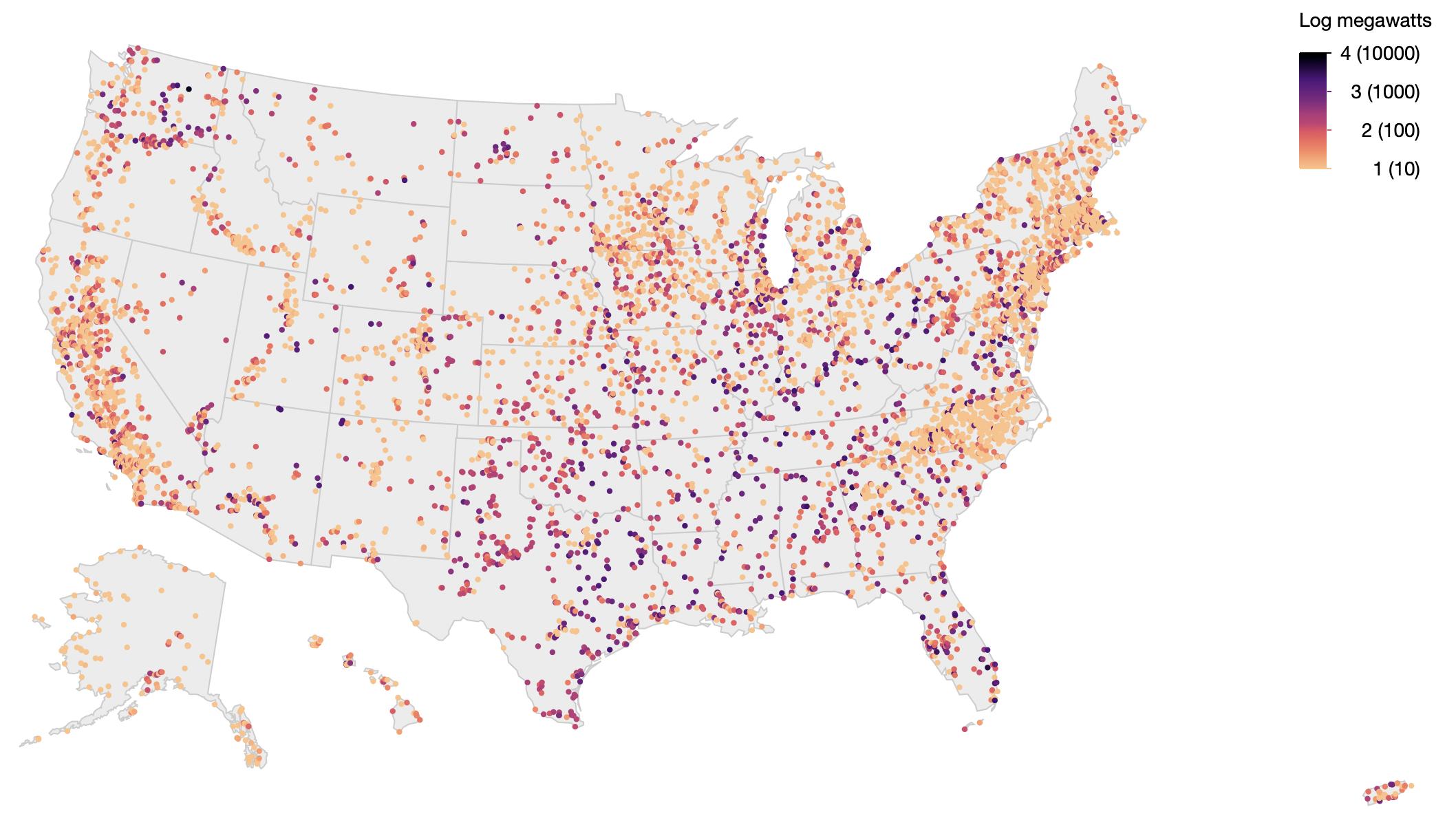
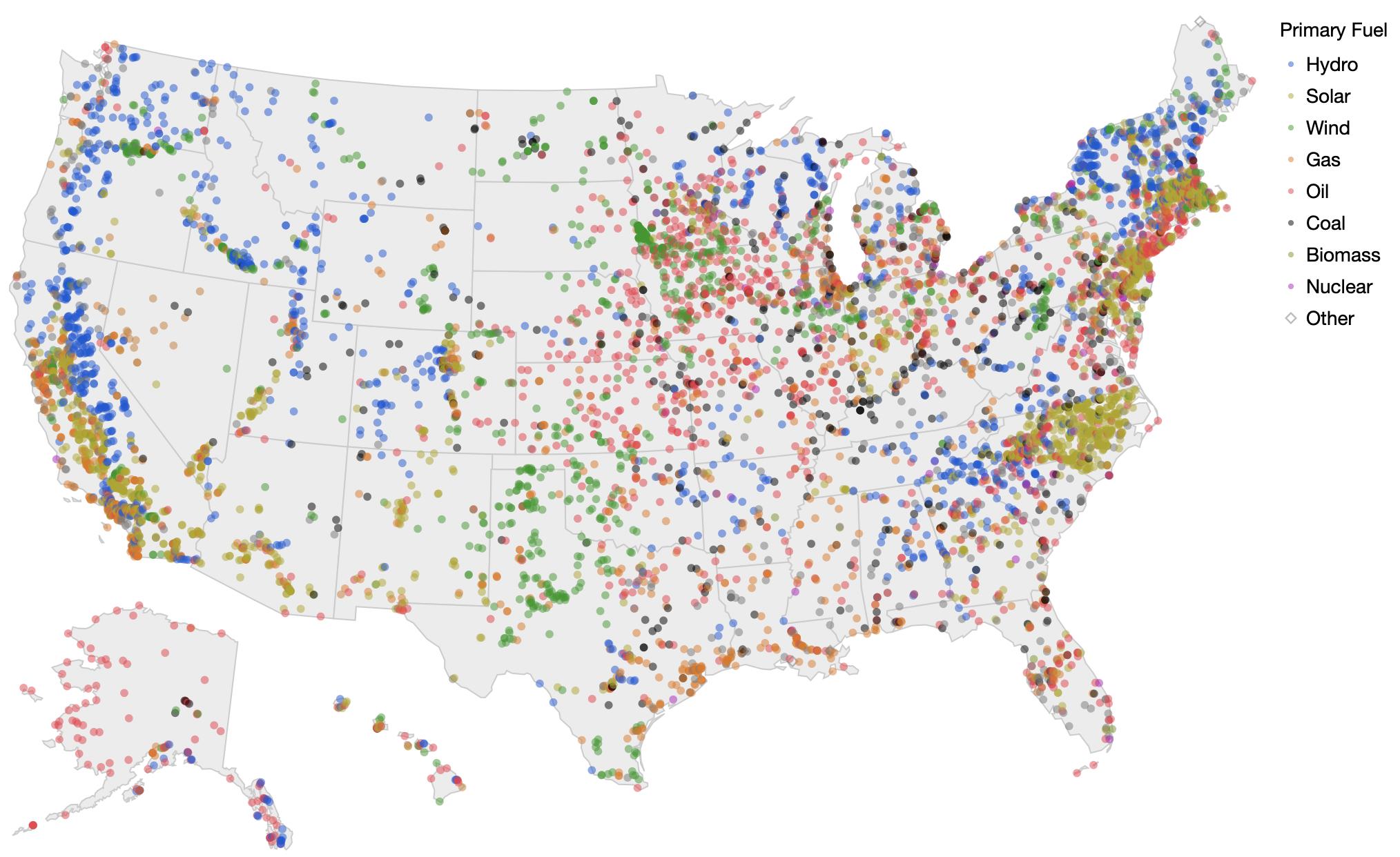
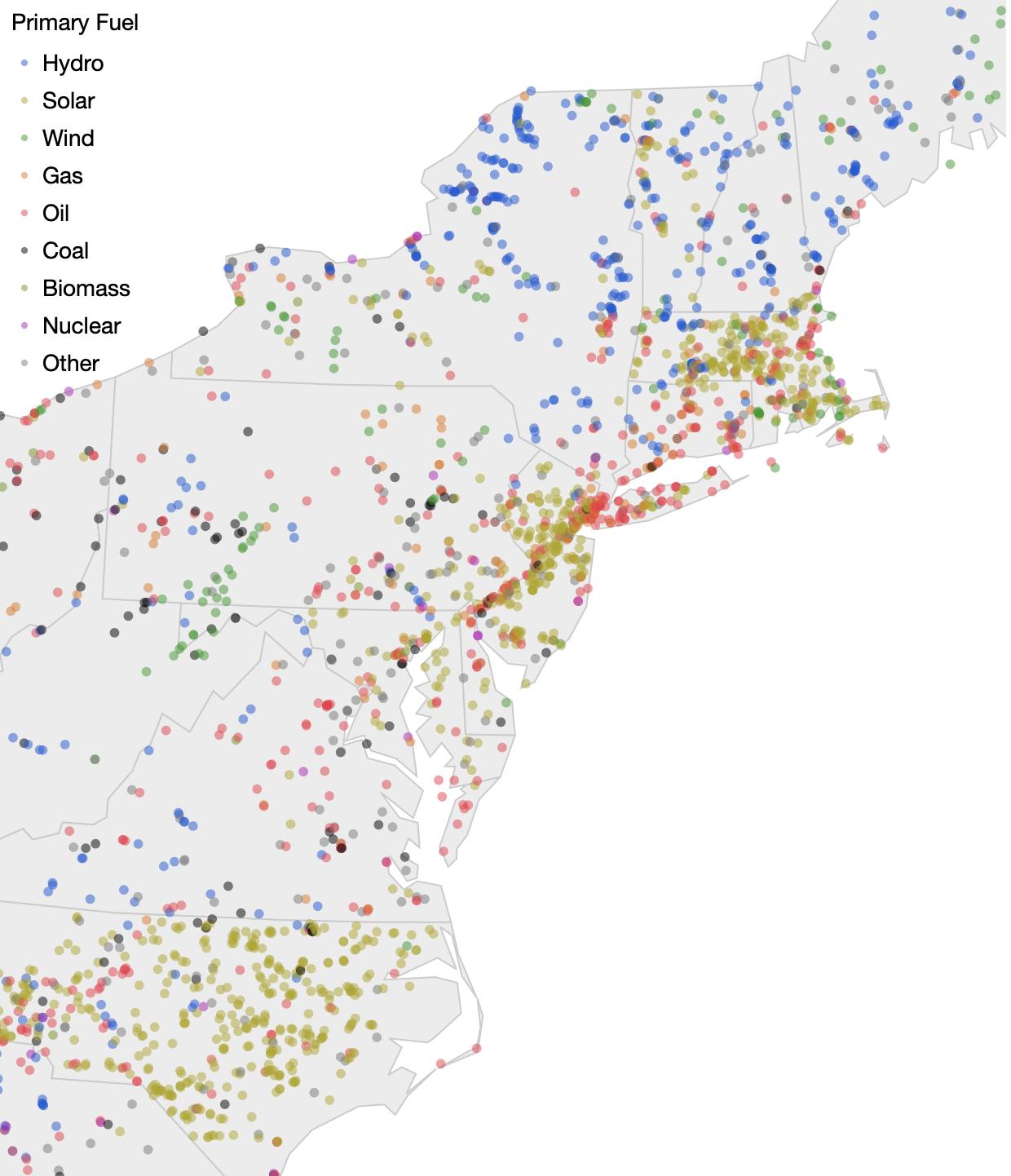
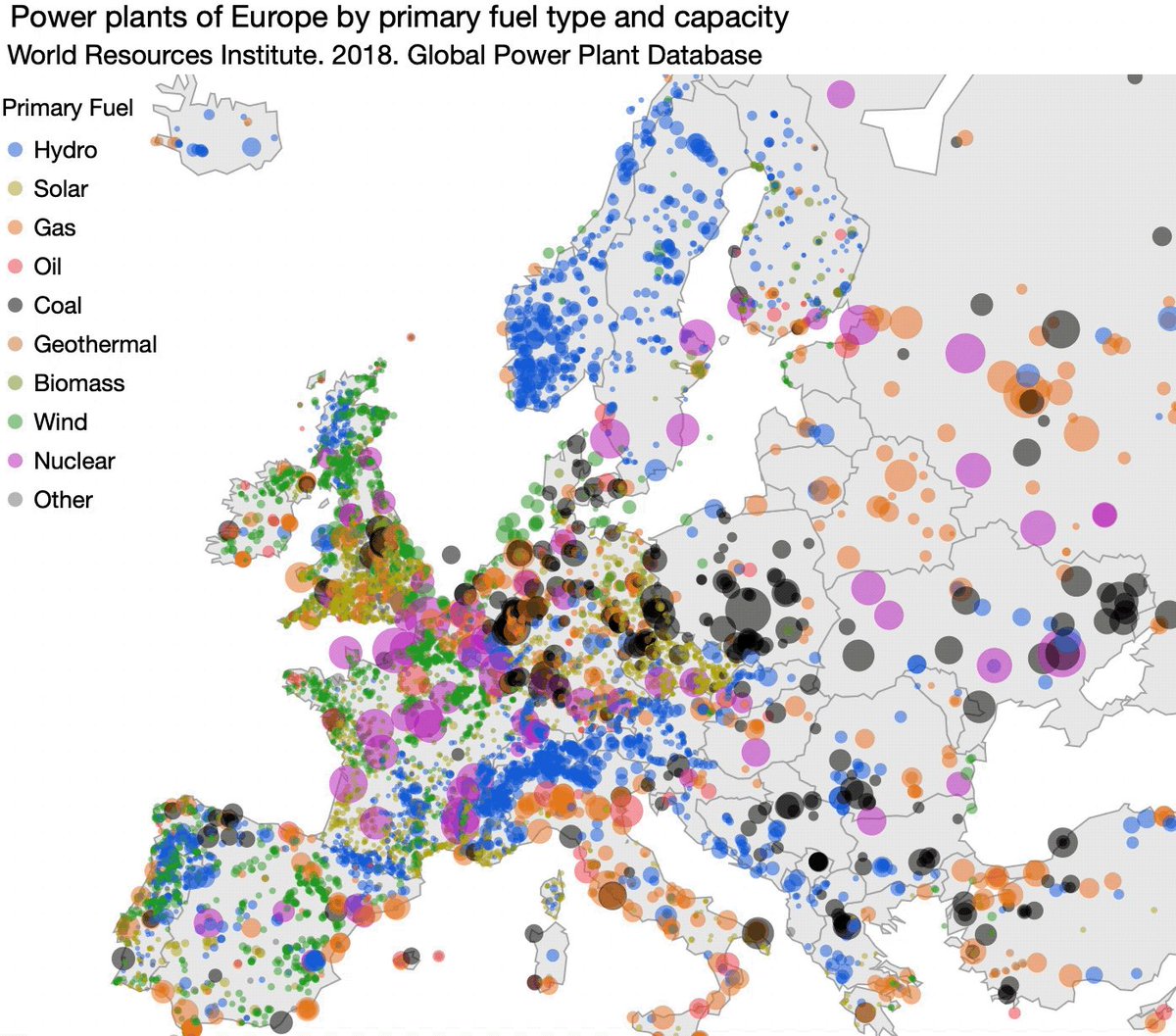
Found the Global Power Plant Database.
More crossword graphs. This time comparing ways of comparing distributions.
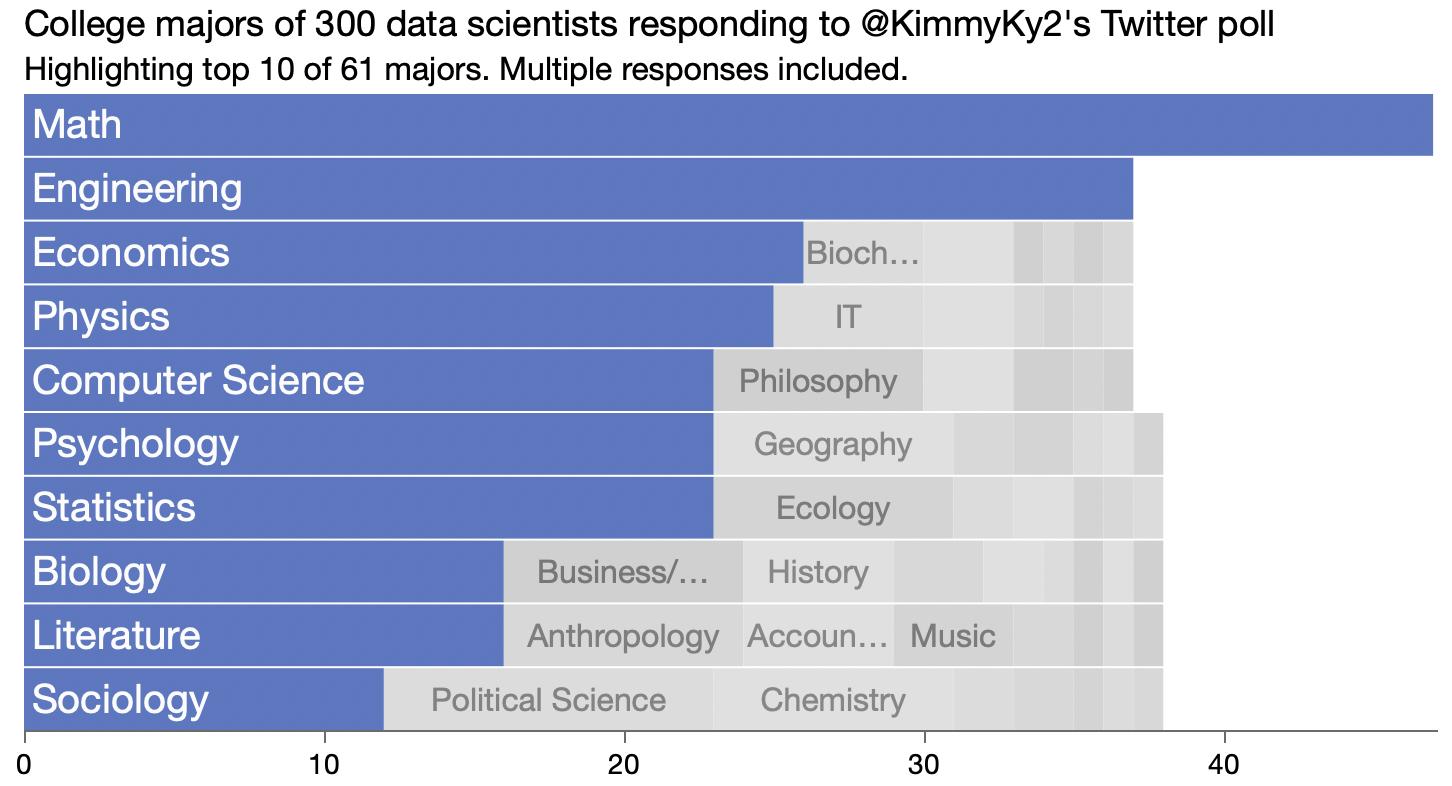
College majors for data scientists from a Twitter poll.
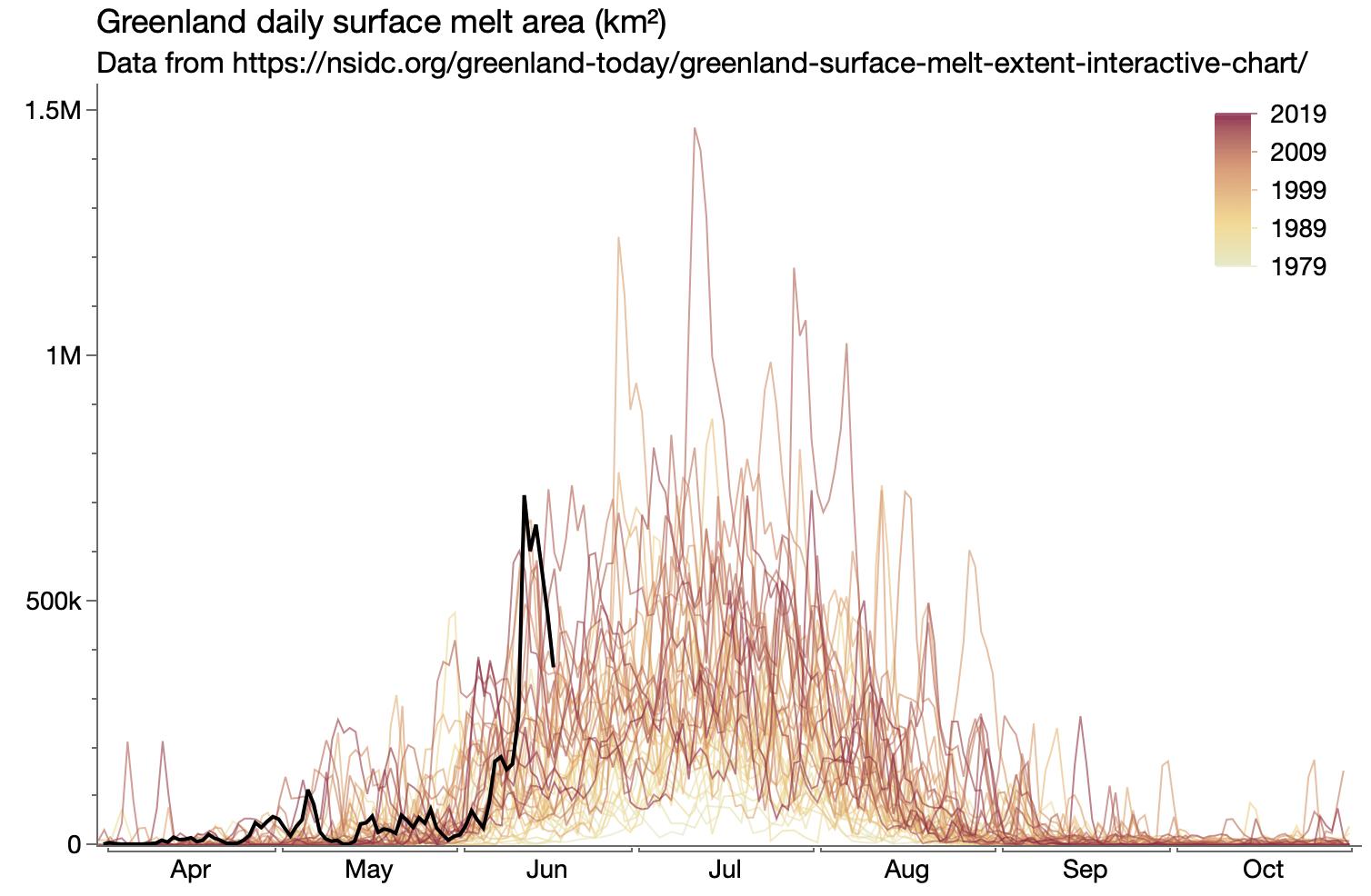
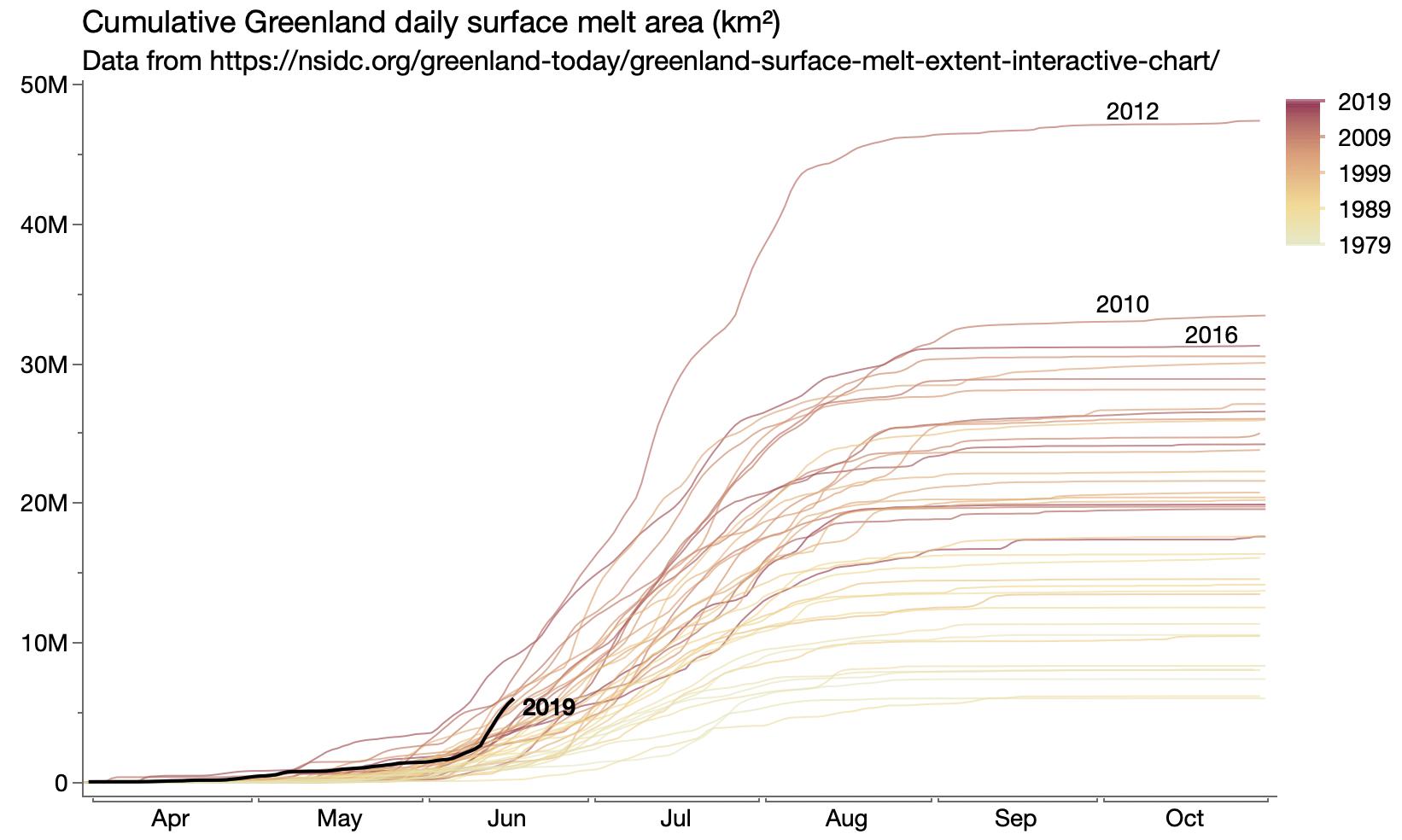
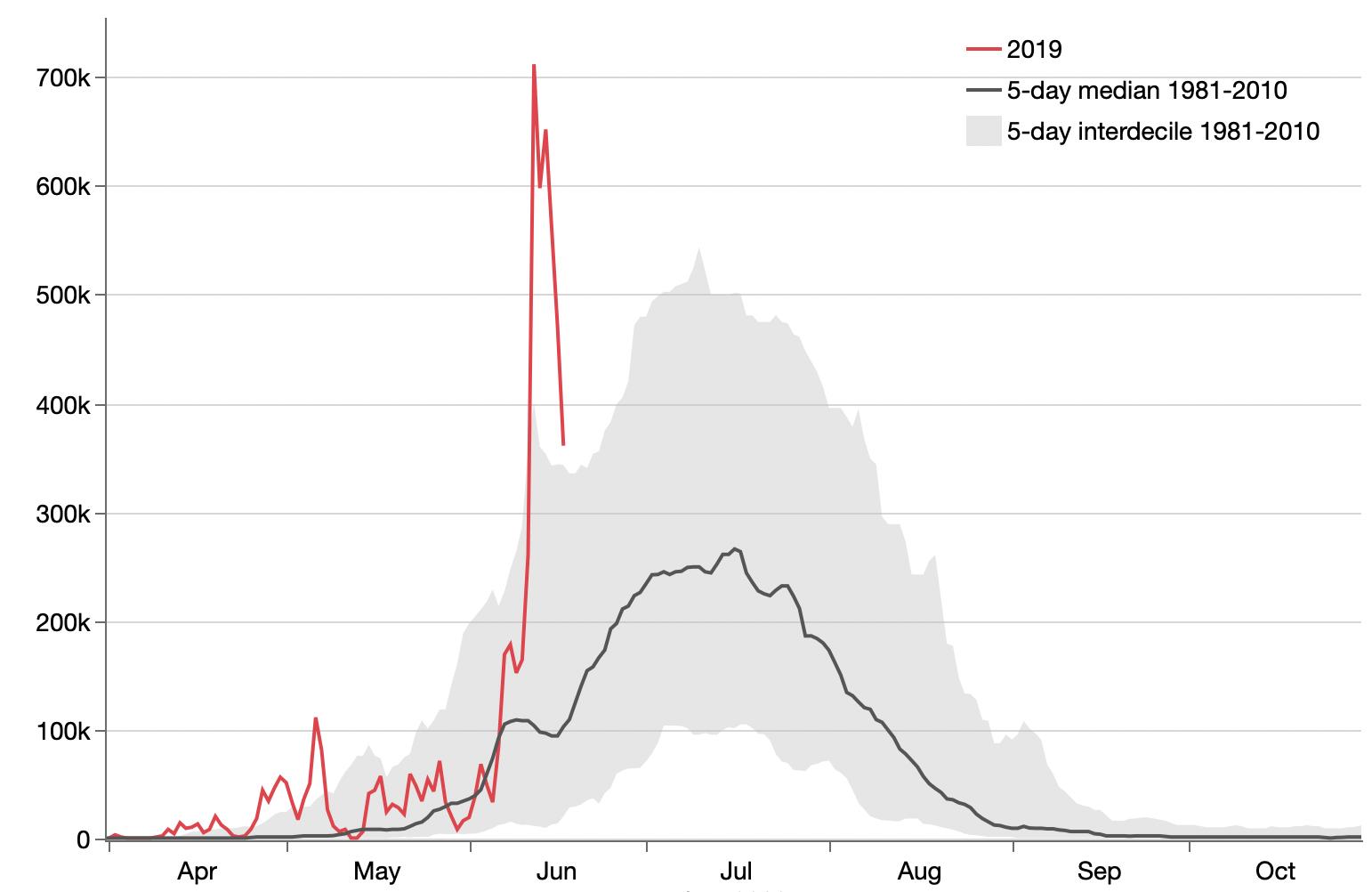
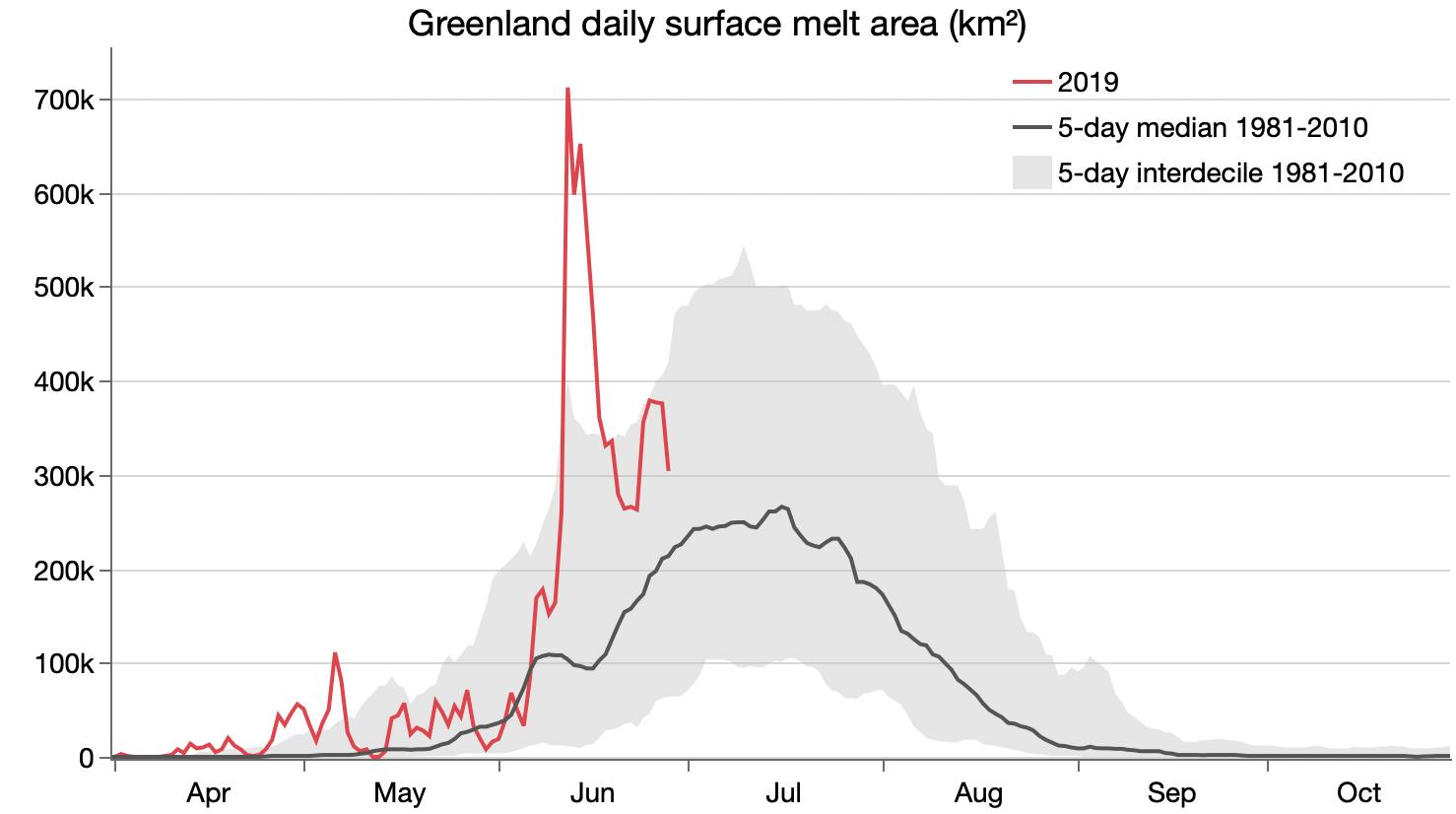
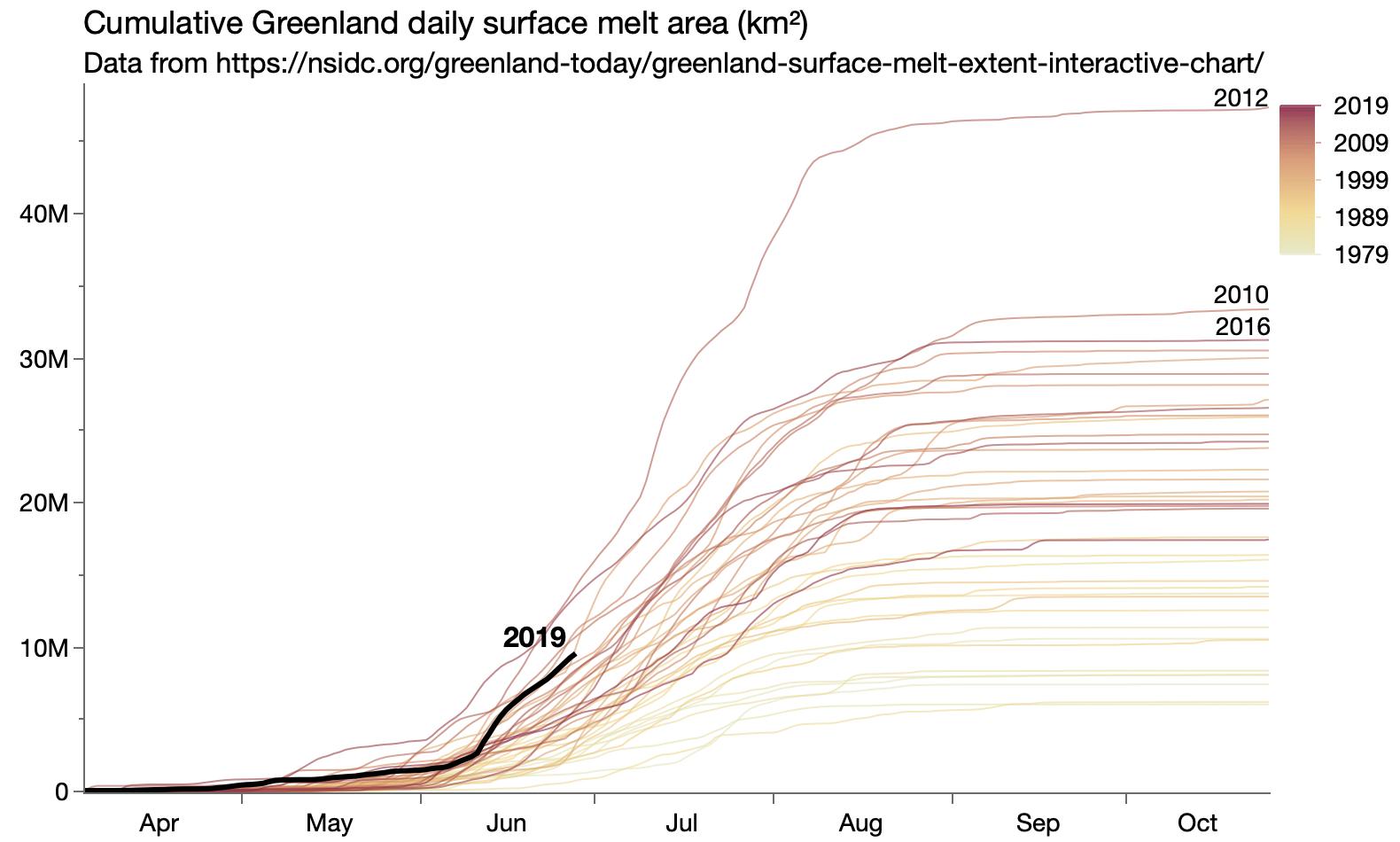
Started looking at Greenland ice melt data. The first graph just verifies that I was reading the gridded data values correctly, but I ended up switching to a different source with summary values for each day.
A word cloud from Apple keynote transcripts.
Another journal chart makeover.
July
Testing the limits of packed bars on audiobook counts. Is 26 too few items? Is 69,321 too many?
Some results I graphed from a salary survey of statisticians.
I also make and share graphs on Cross Validated Q&A site. Here’s one I also tweeted, simulating overlapping bars.
A makeover of a bar-mekko chart.
Demonstrating bars with labels inside the bars.
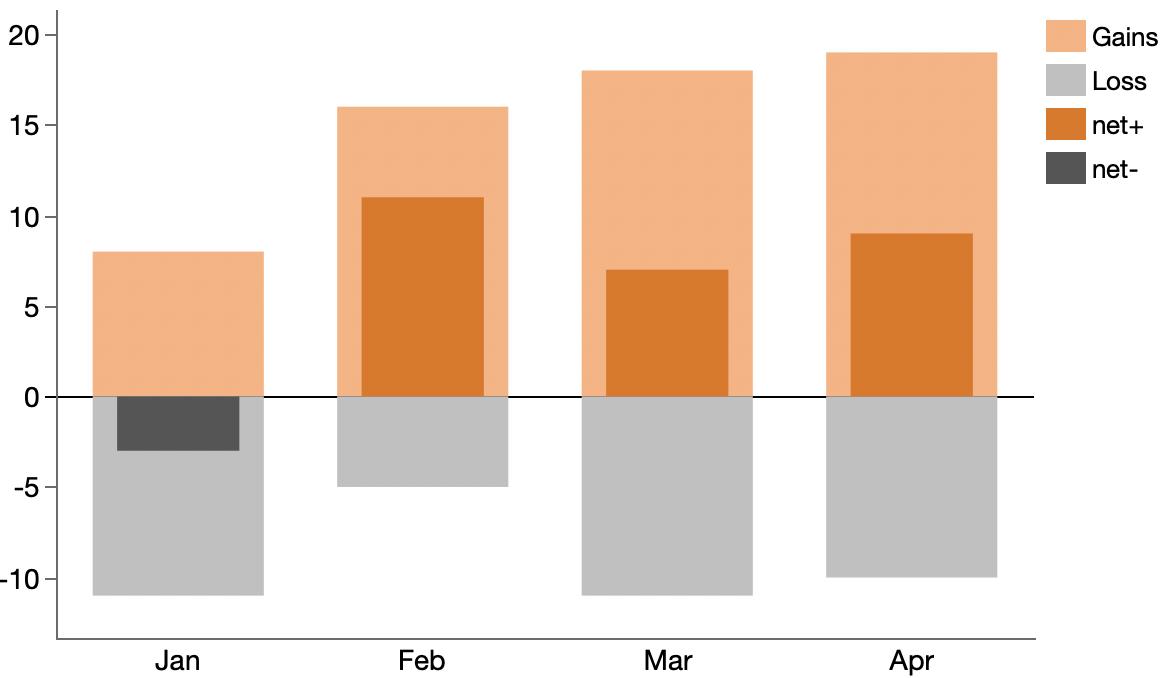
A way to show gains and losses along with the net result.
A makeover of a questionable ISOTYPE graph from UNC.
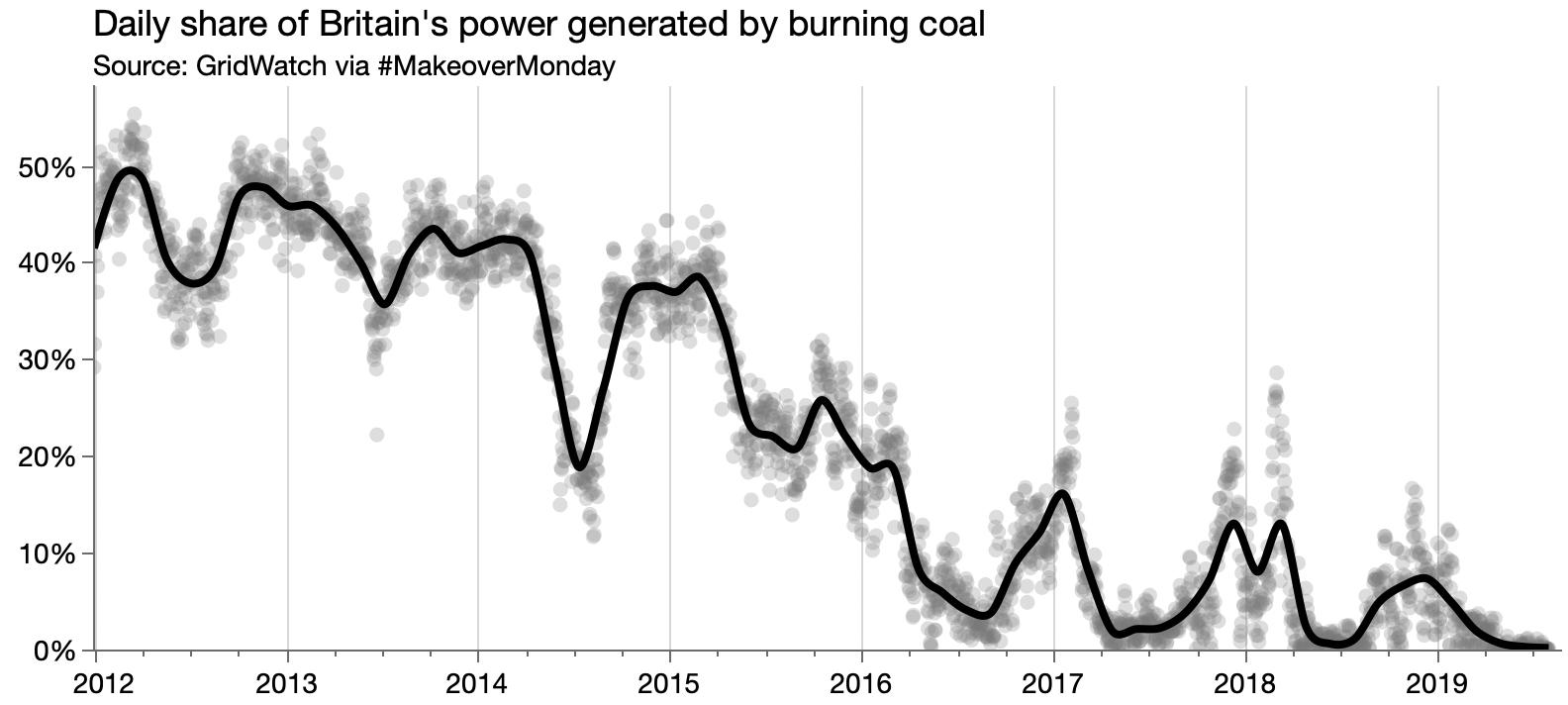
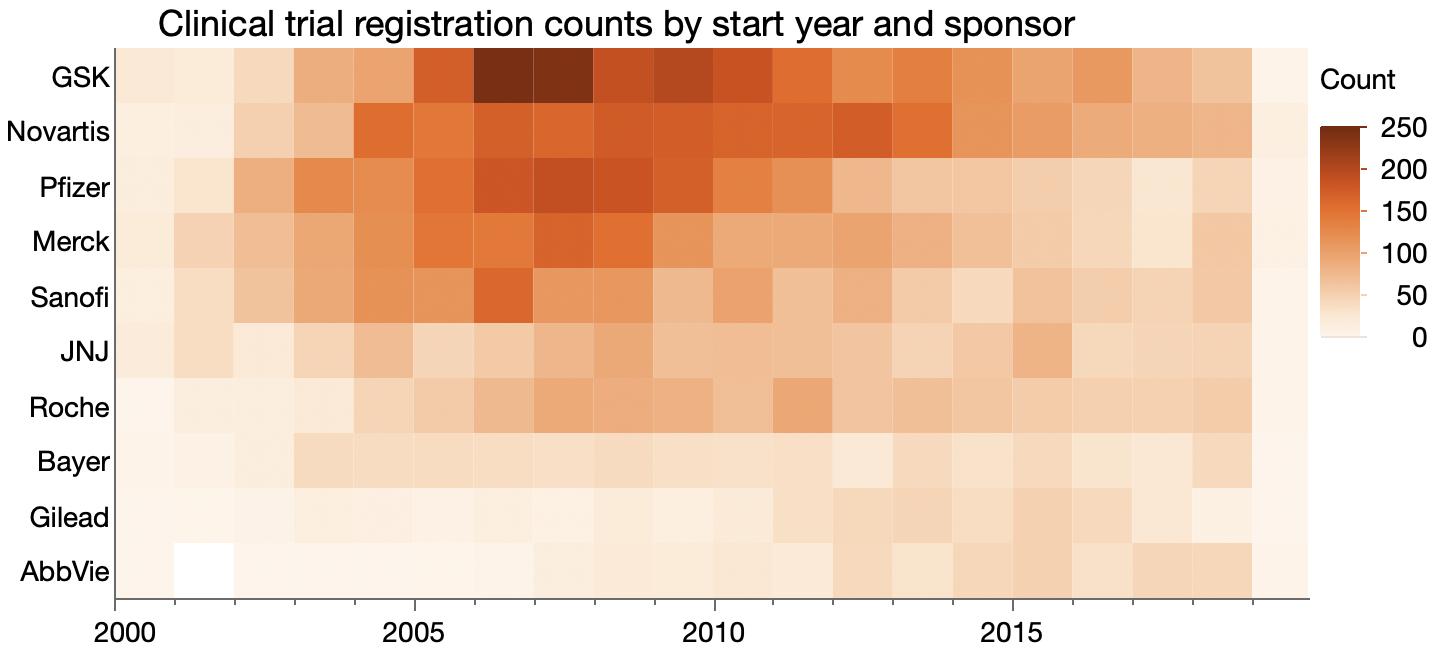
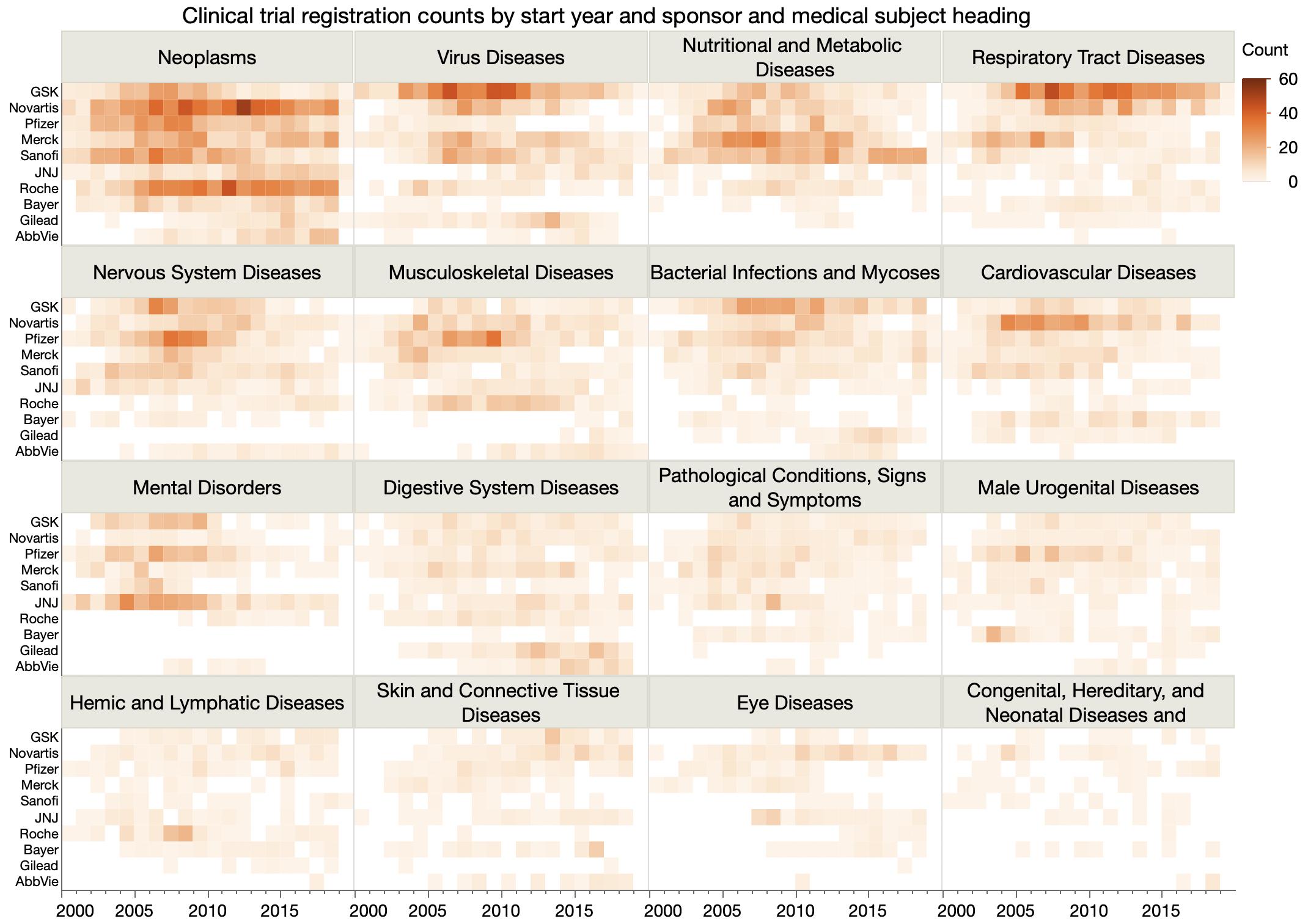
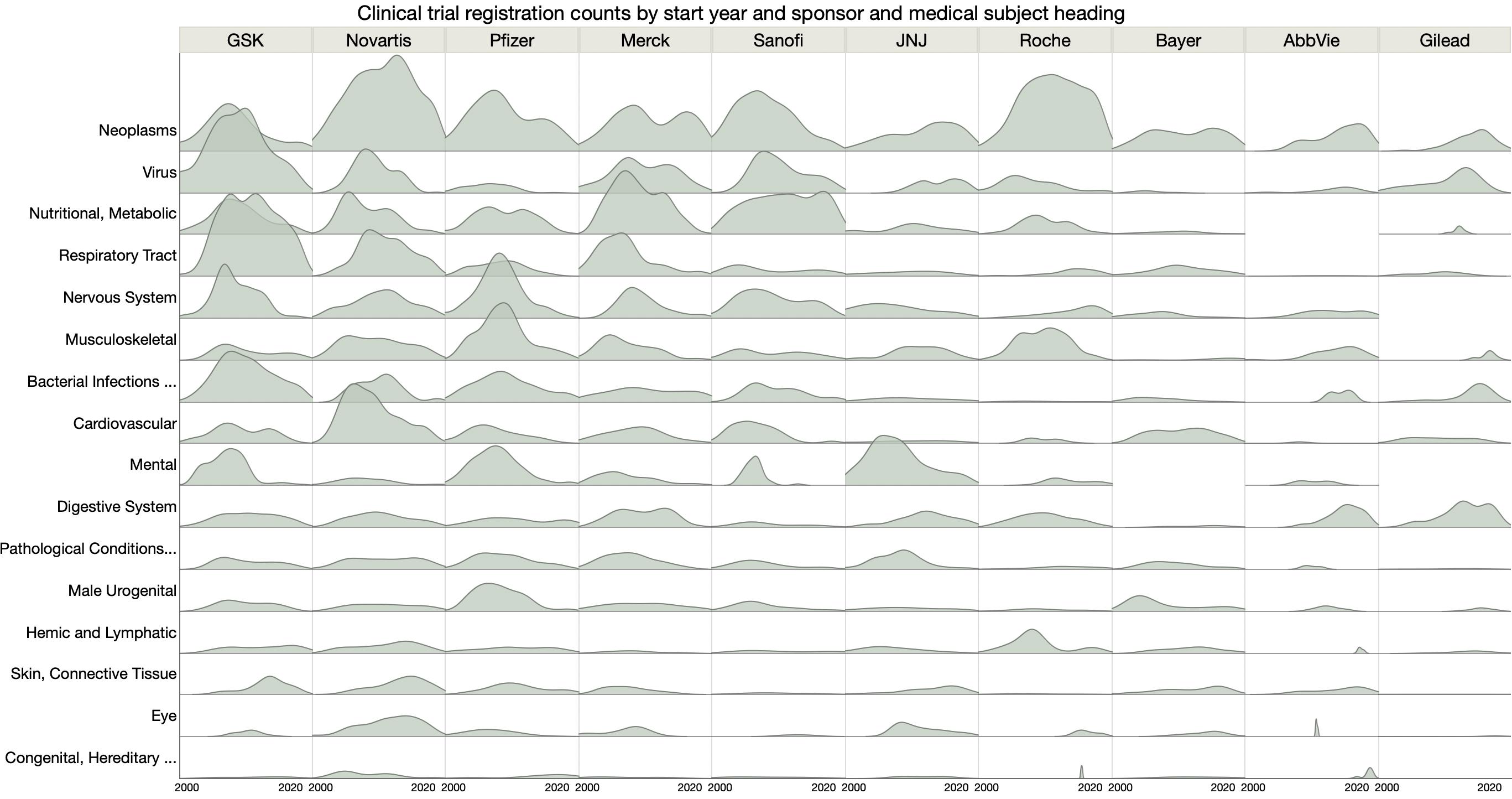
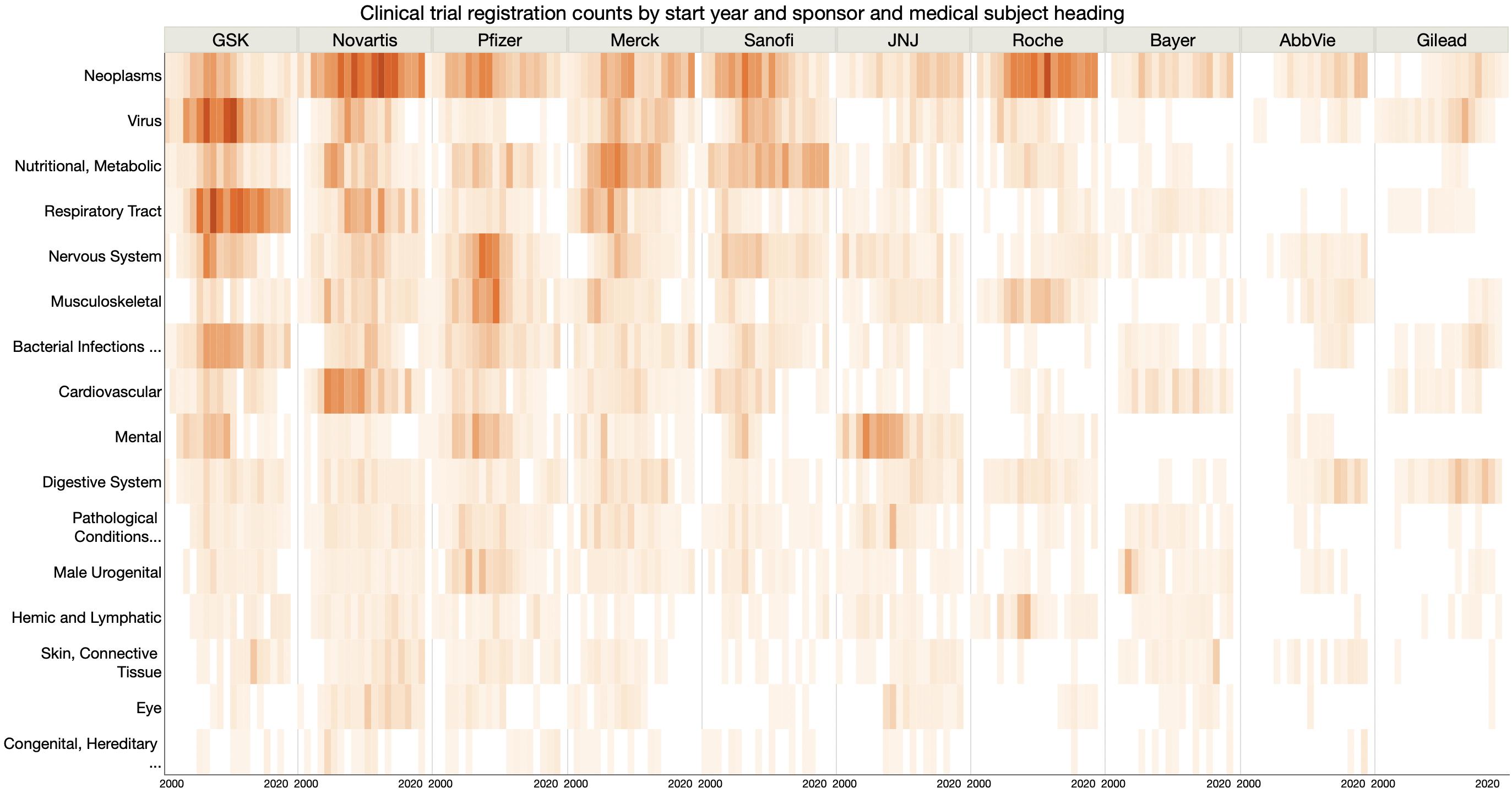
Another #MakeoverMonday data set: clinical trials counts.
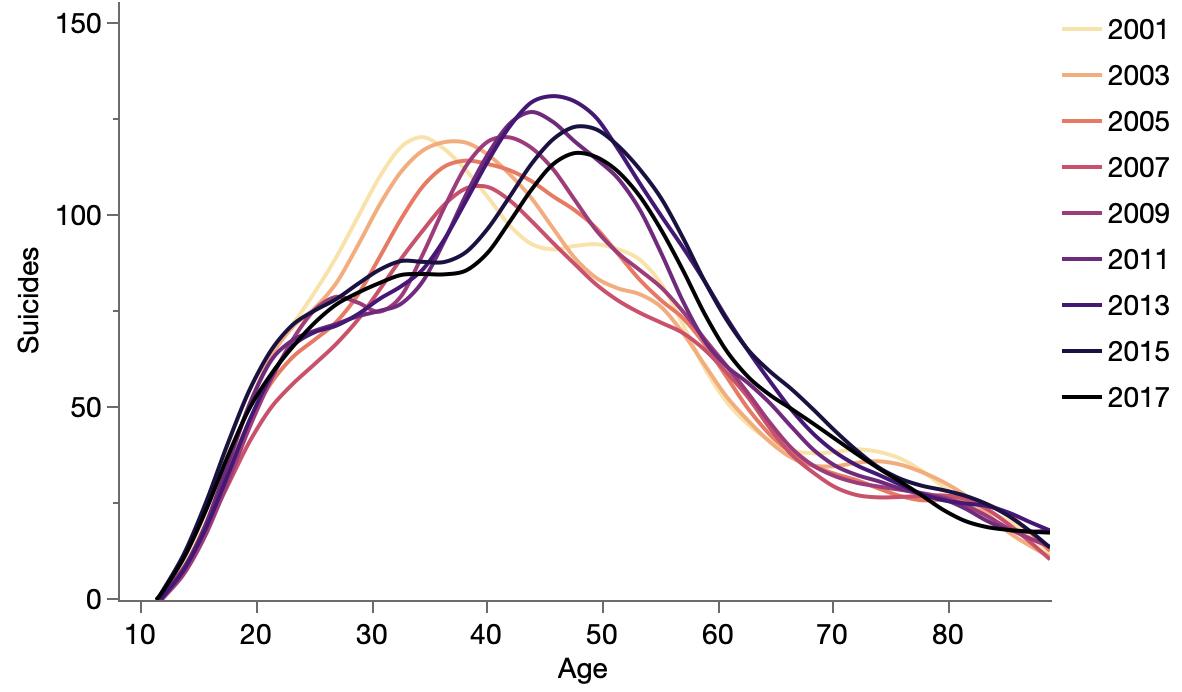
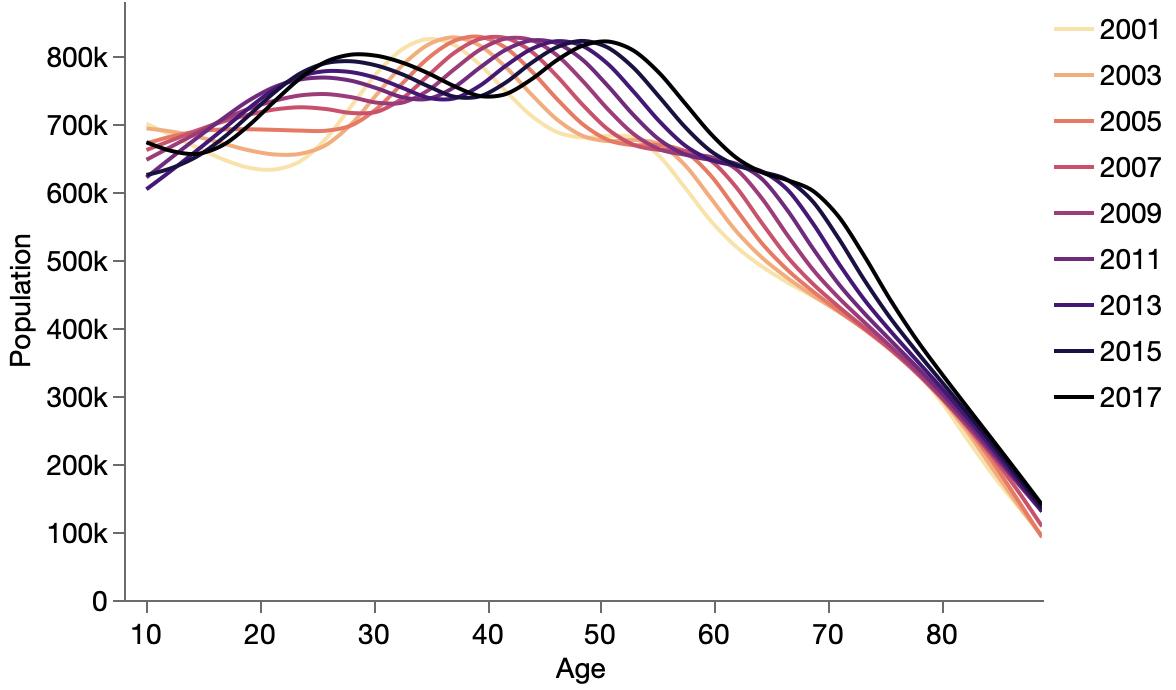
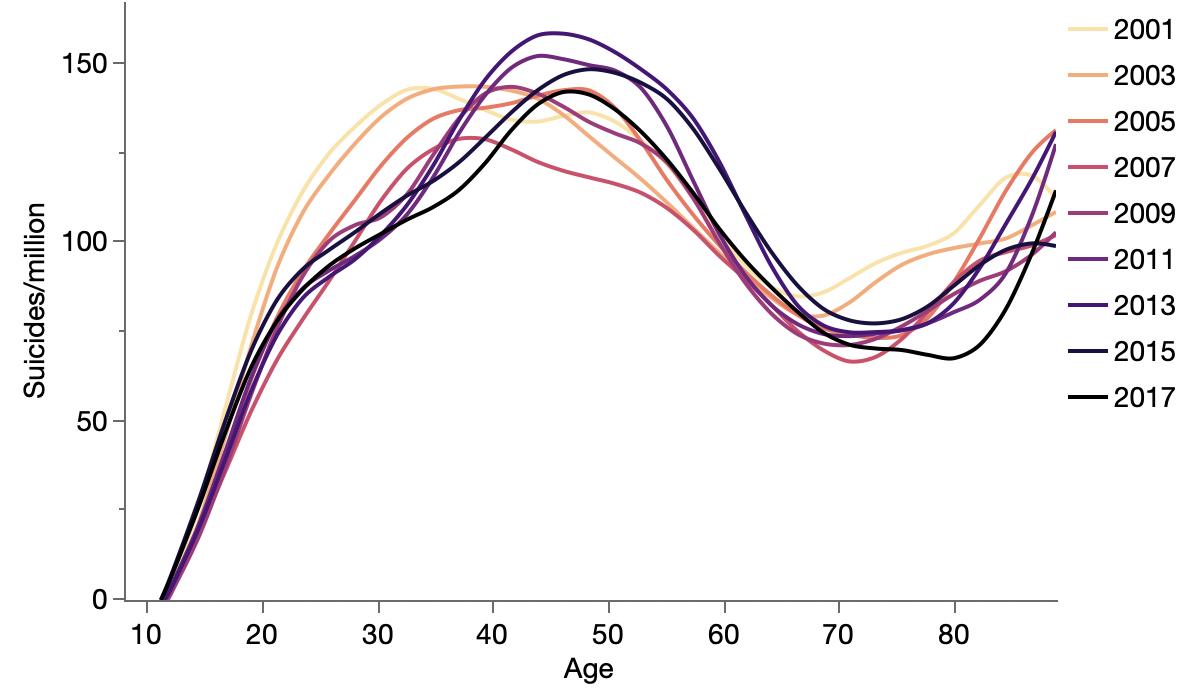
Trying to breakdown UK suicides data. Thought it might be a baby boom effect, but there seems to have been less of a baby boom in the UK.
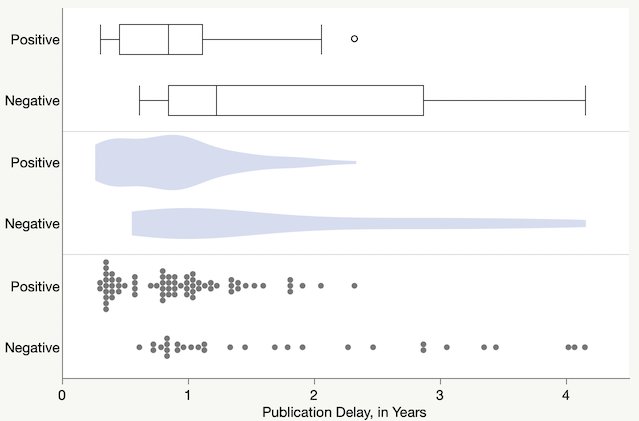
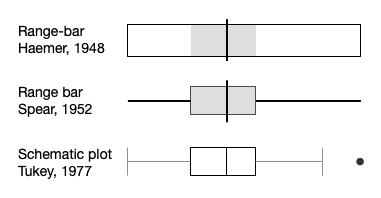
I made this comparison of early box plot forms.
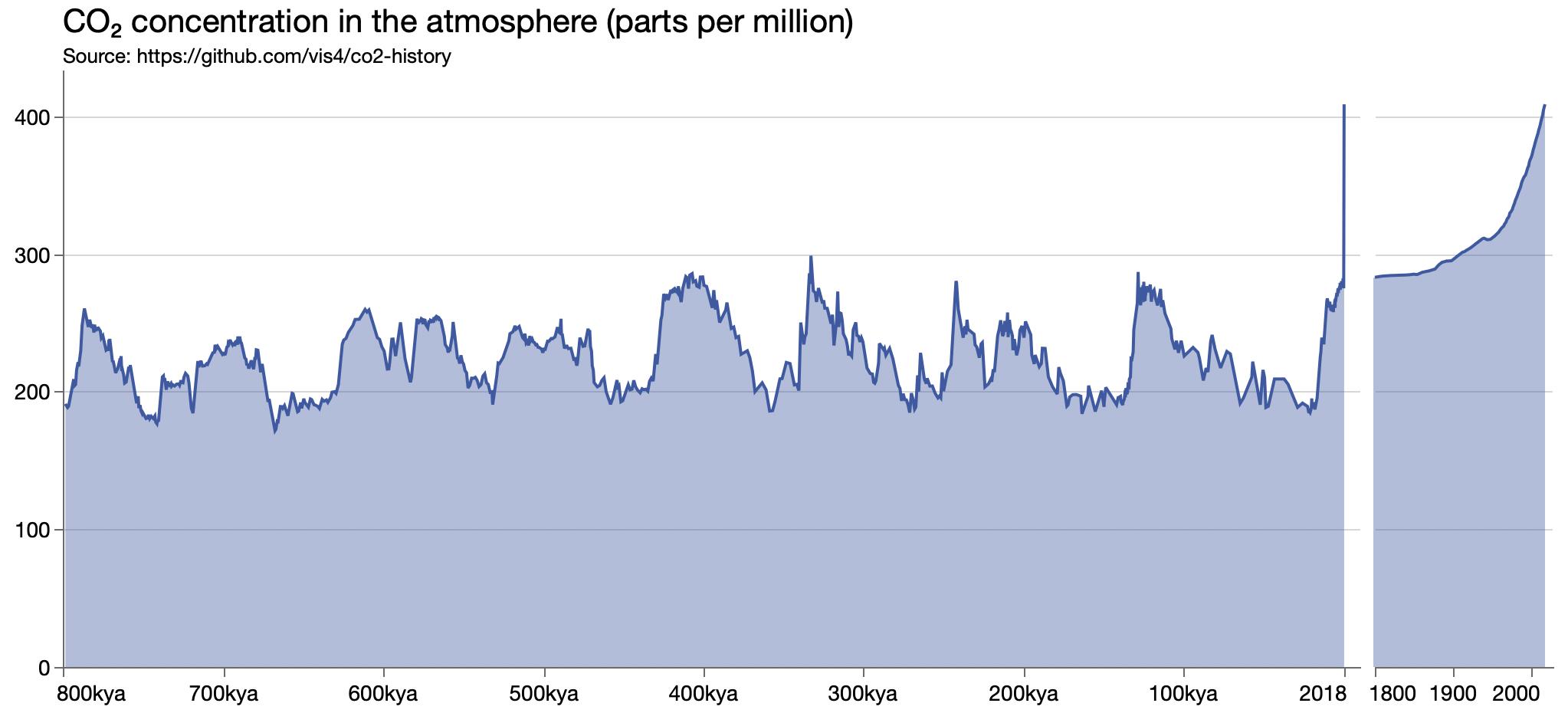
A zoomed-in axis inset to explore showing both long and short time scales.
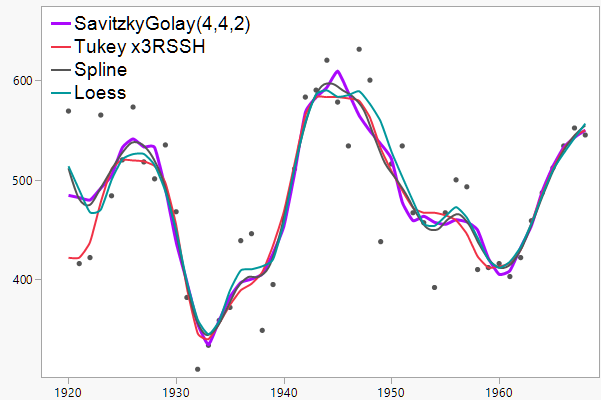
I took the coal production data Tukey used for the smoothers in his book and tried a few other smoothers.
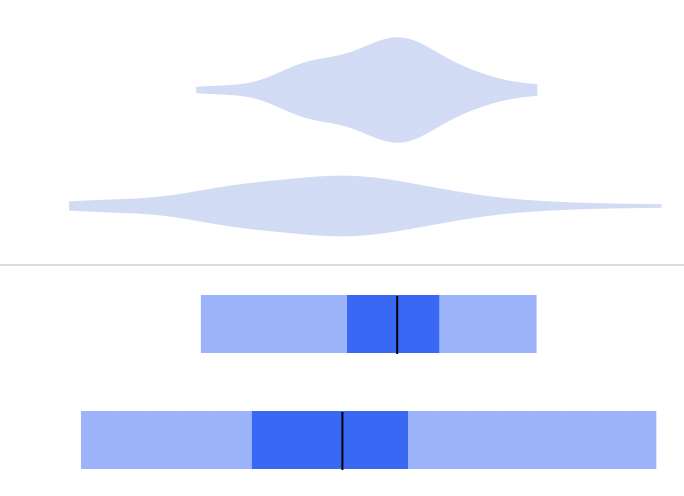
Violins versus Highest Density Region plots:
September
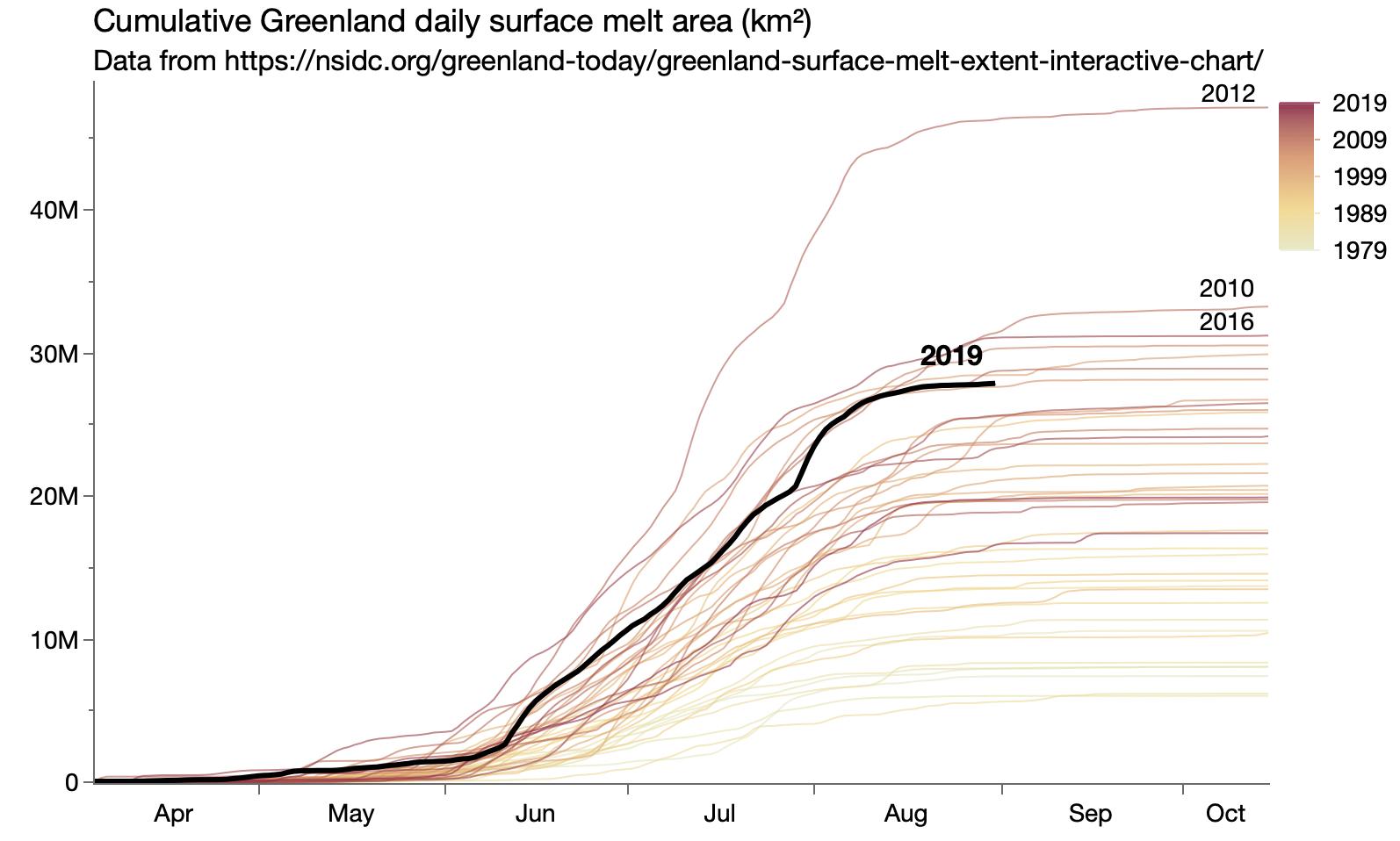
Updated Greenland ice melt cumulative view.
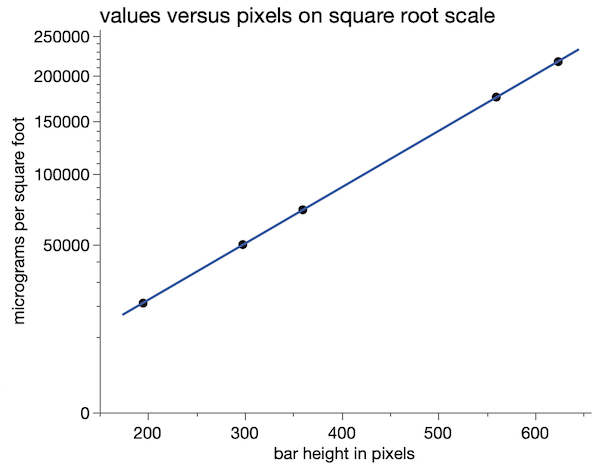
Verifying that the bars in a NYT Notre Dame graphic were sized on a square root scale instead of linear.
Checking default Y axis scaling for a line plot in JMP.
Exploring how packing affects aggregate size.
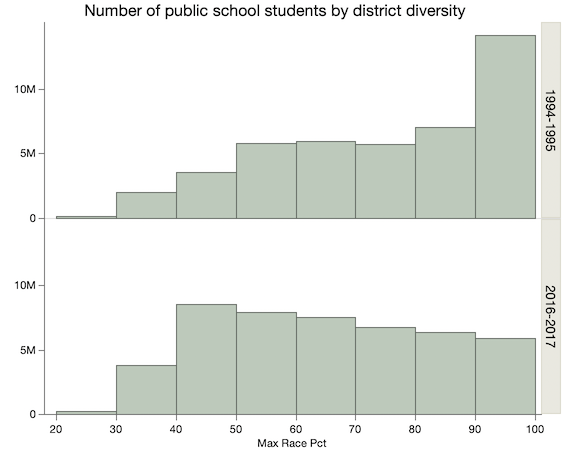
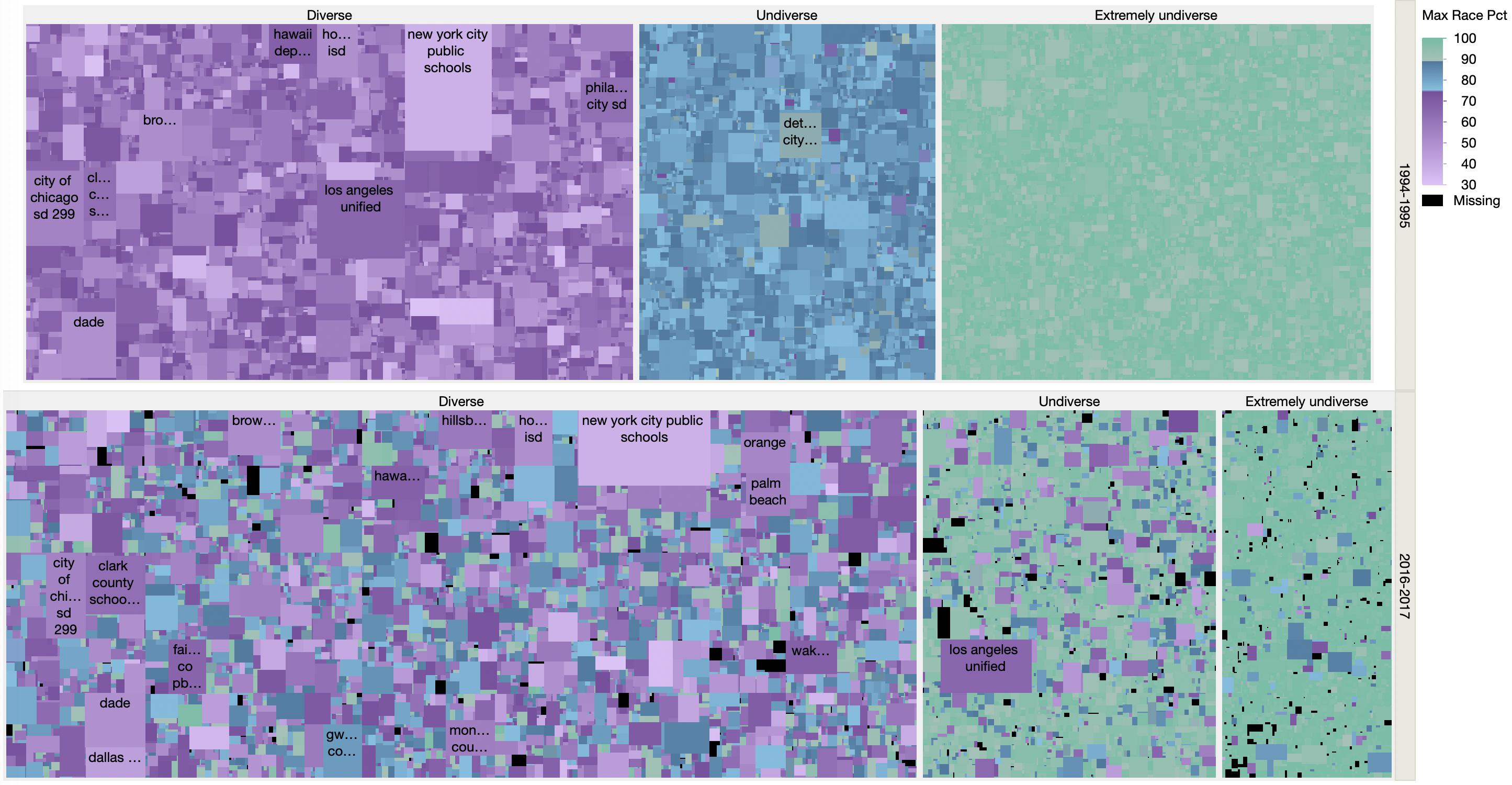
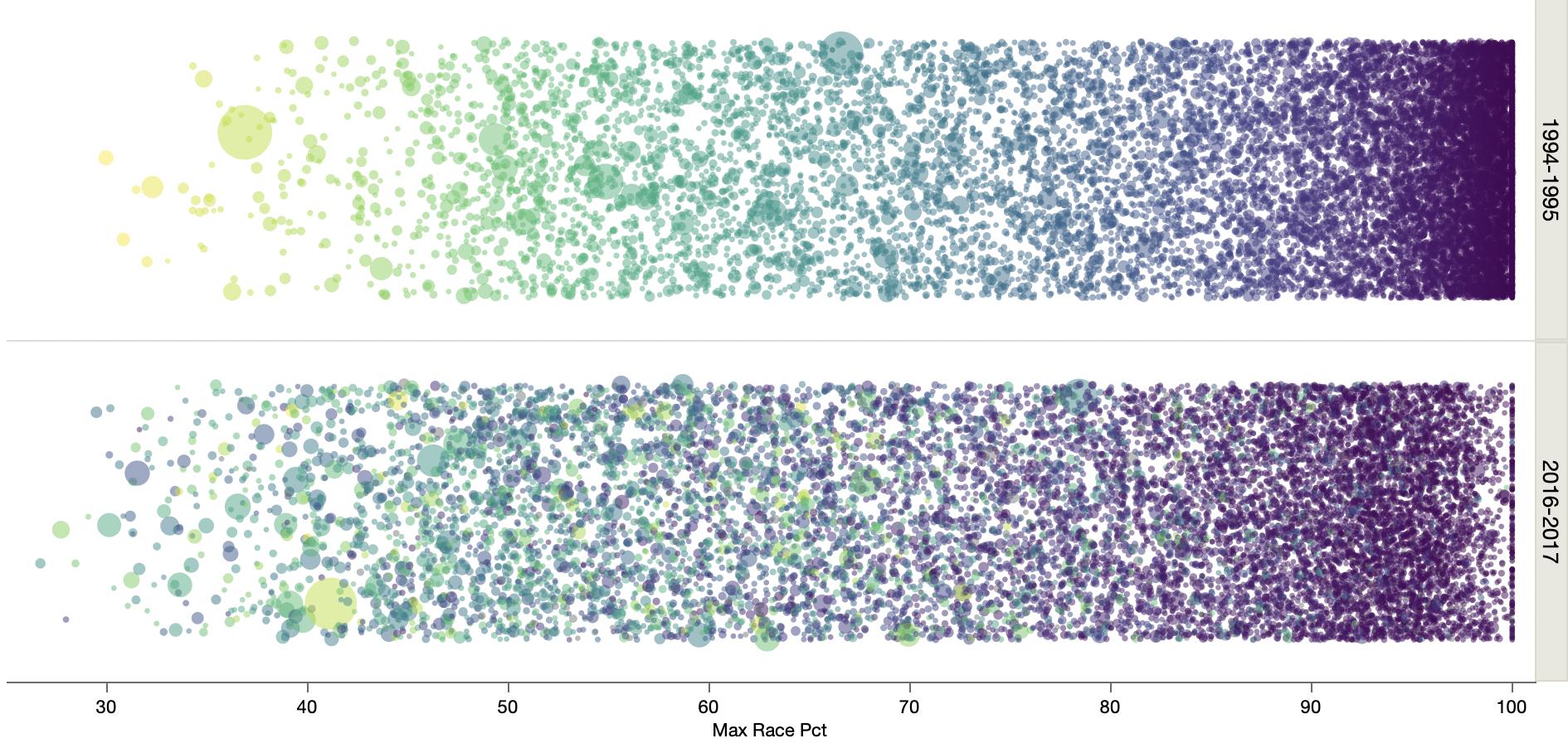
Looking at school district diversity data from a Washington Post graphic.
October
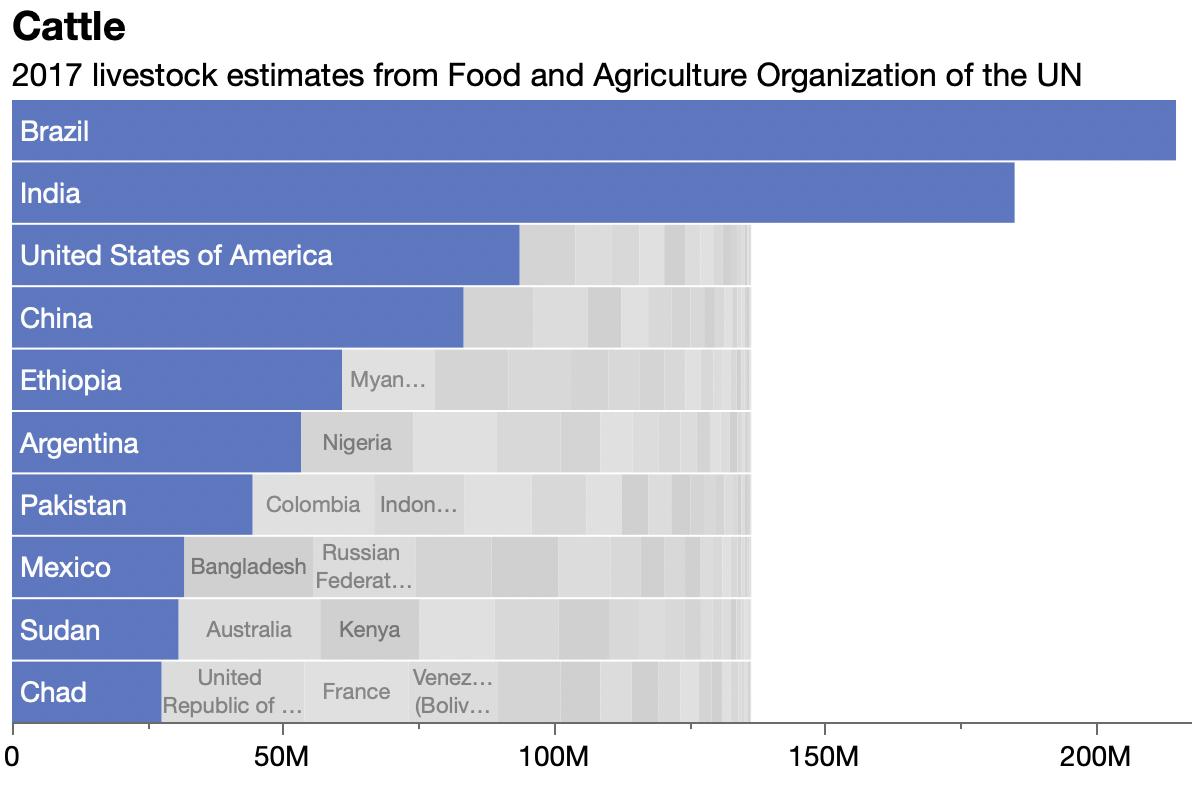
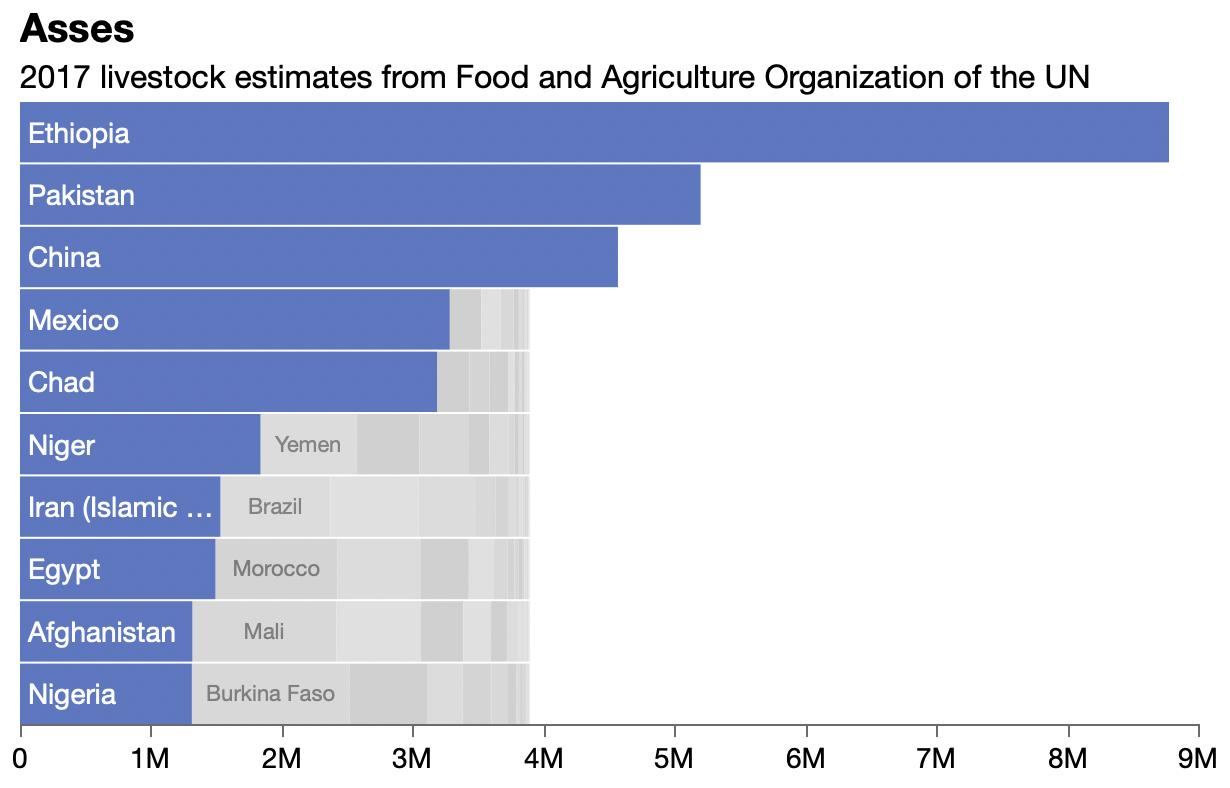
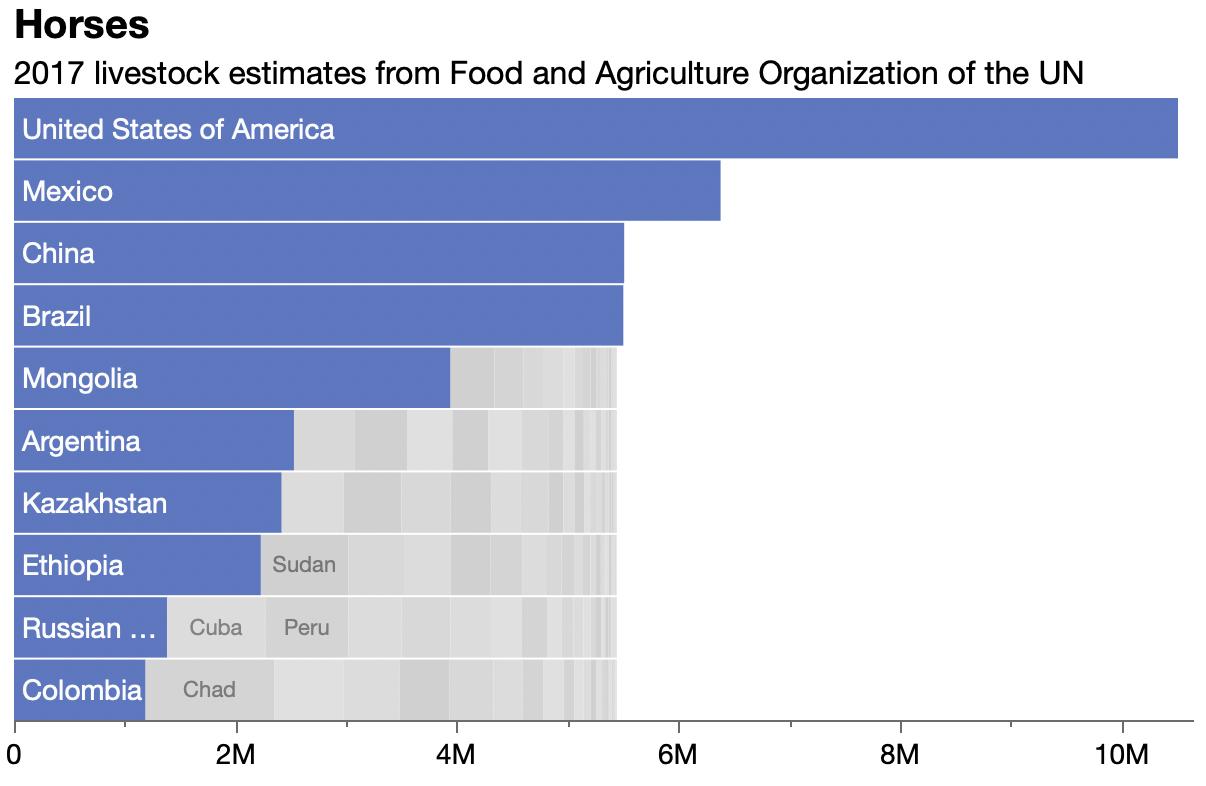
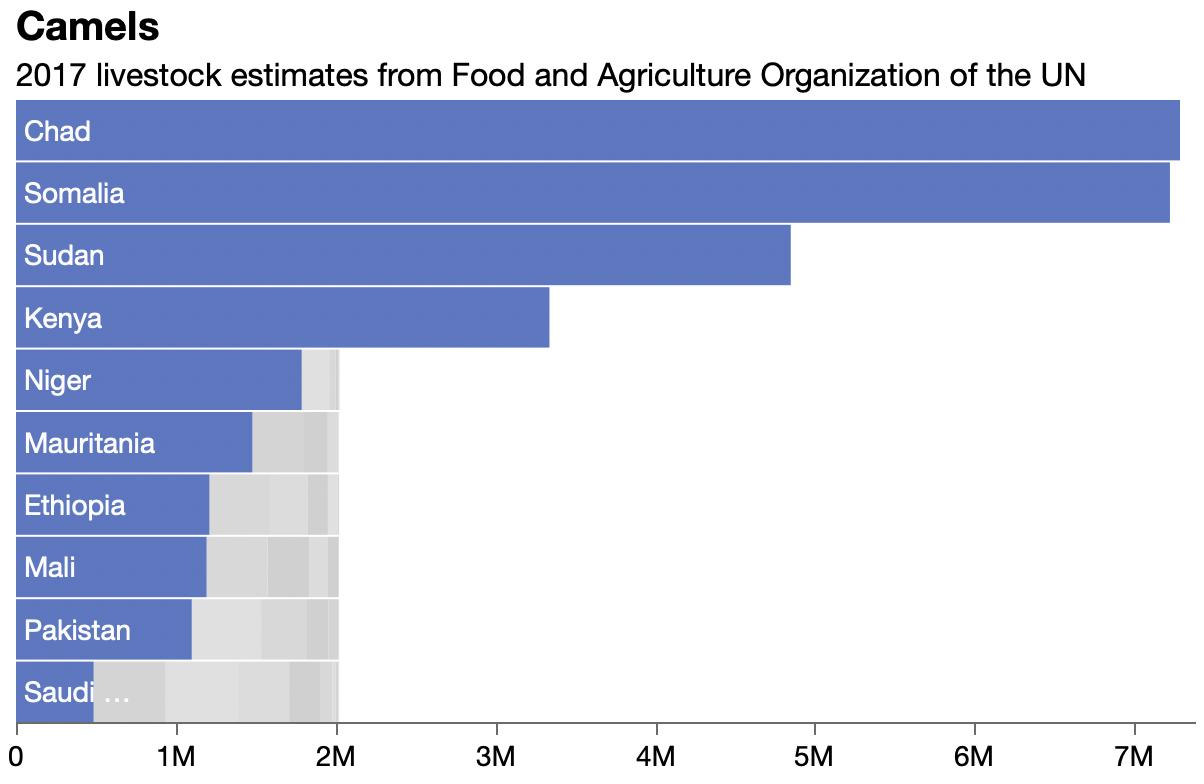
Discovered livestock data at UN’s Food and Agriculture Organization site. Showing 4 of 11 packed bar charts here.
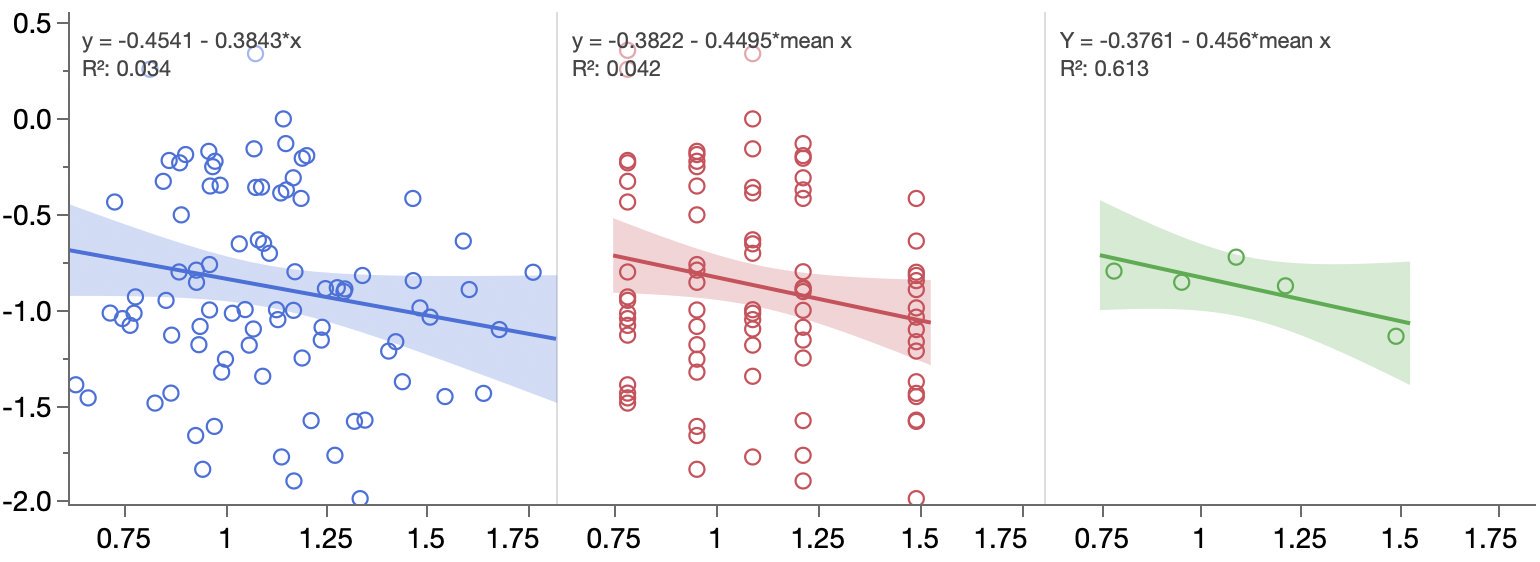
Comparing the effects of aggregation on regression after seeing an odd analysis in Significance magazine. They later published this graph in their correspondence section.
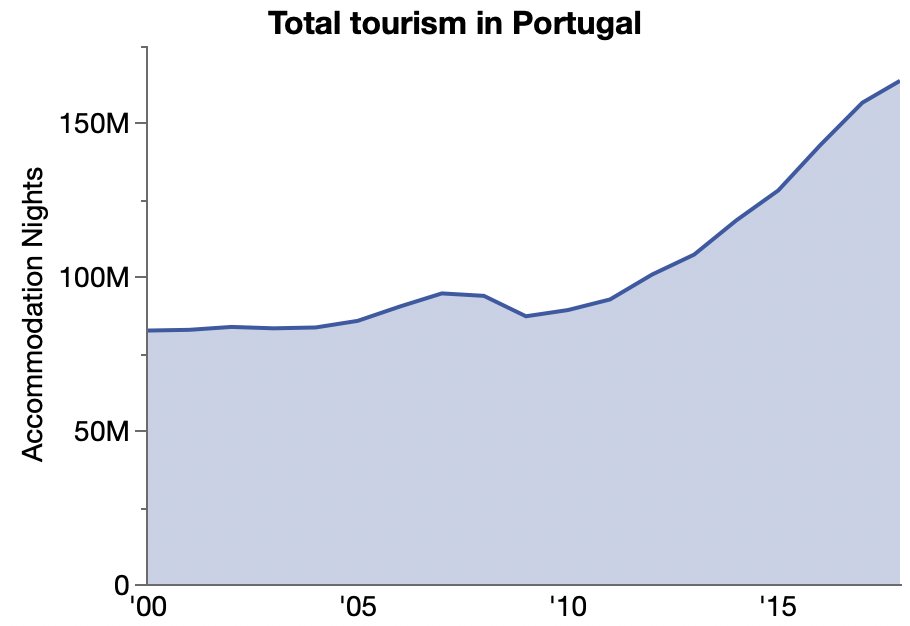
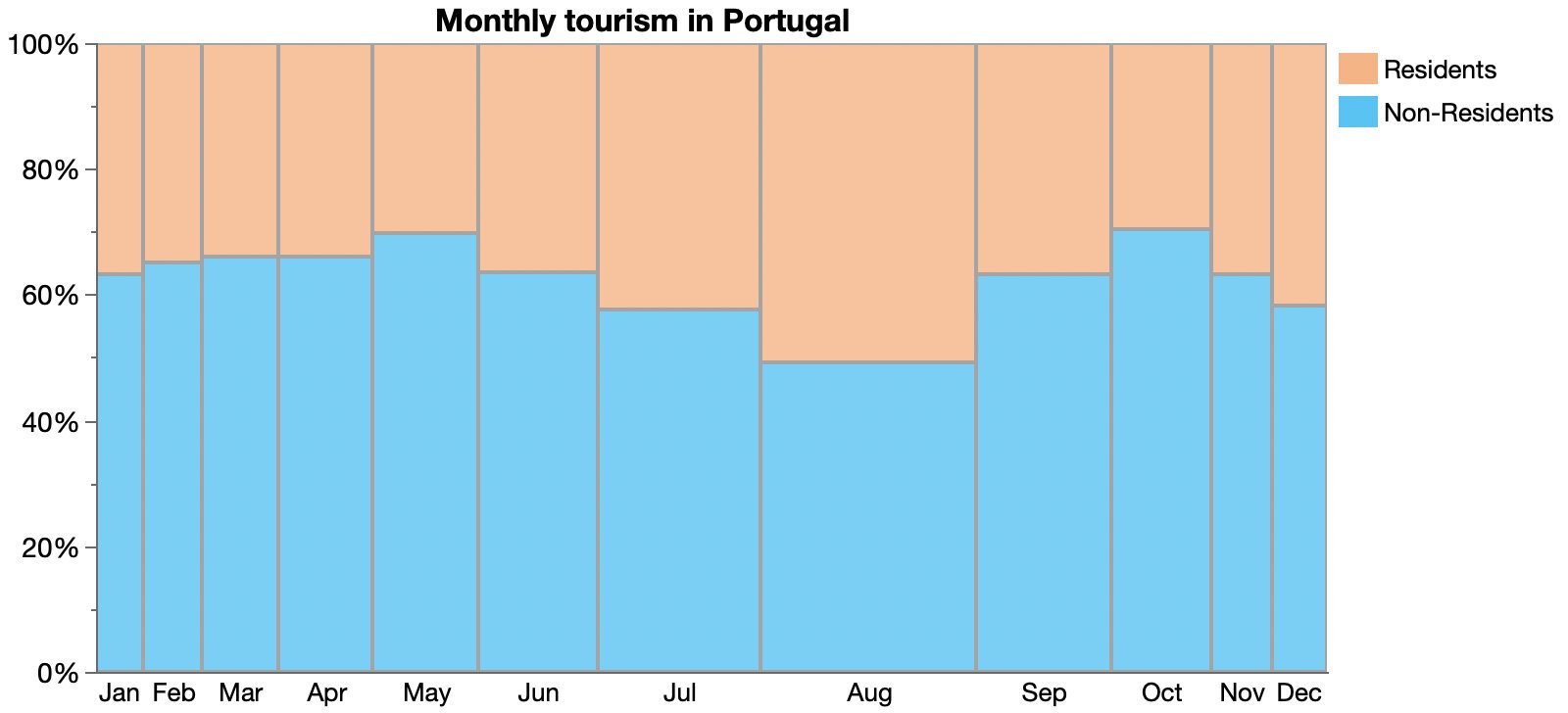
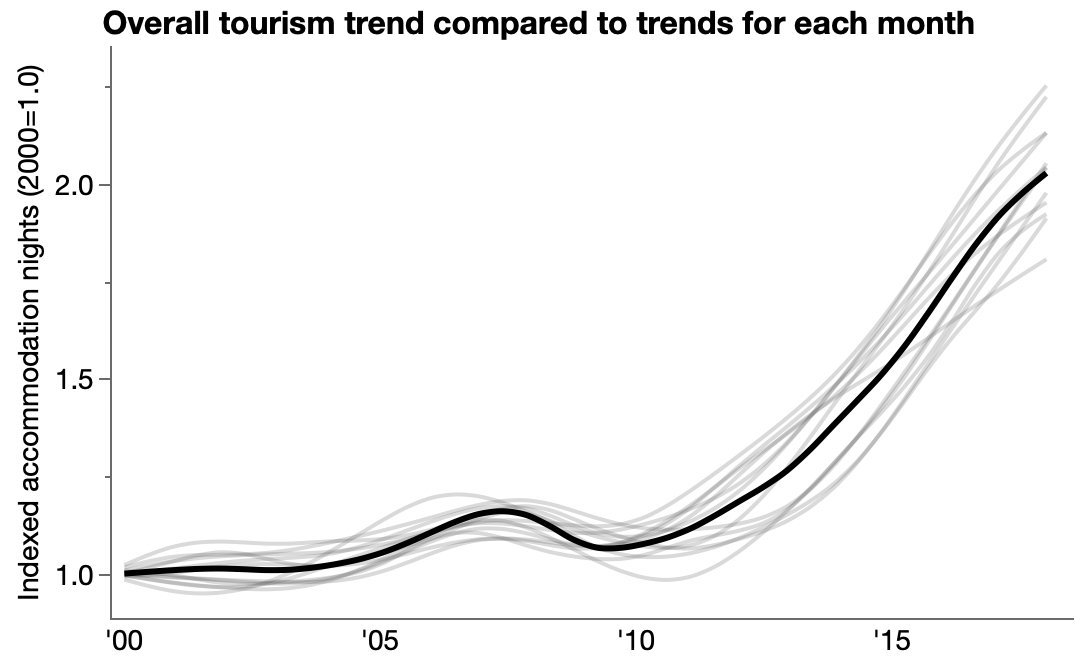
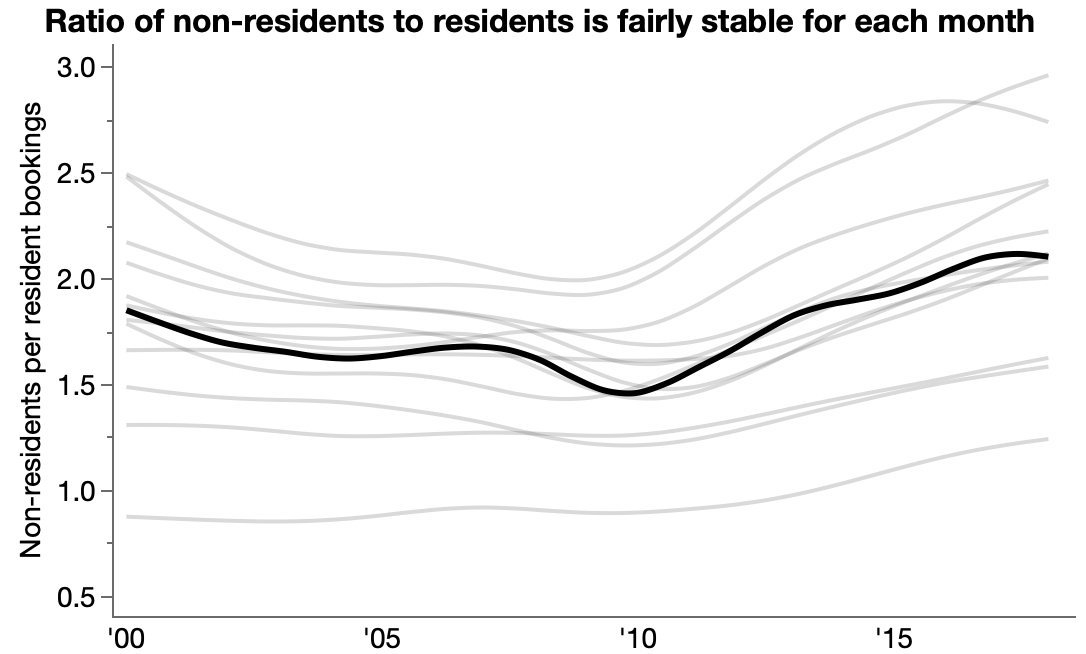
Tourism in Portugal
Some alternatives to a truncated bar chart I saw in a paper.
A mini-gallery I made to show some new JMP 15 features.
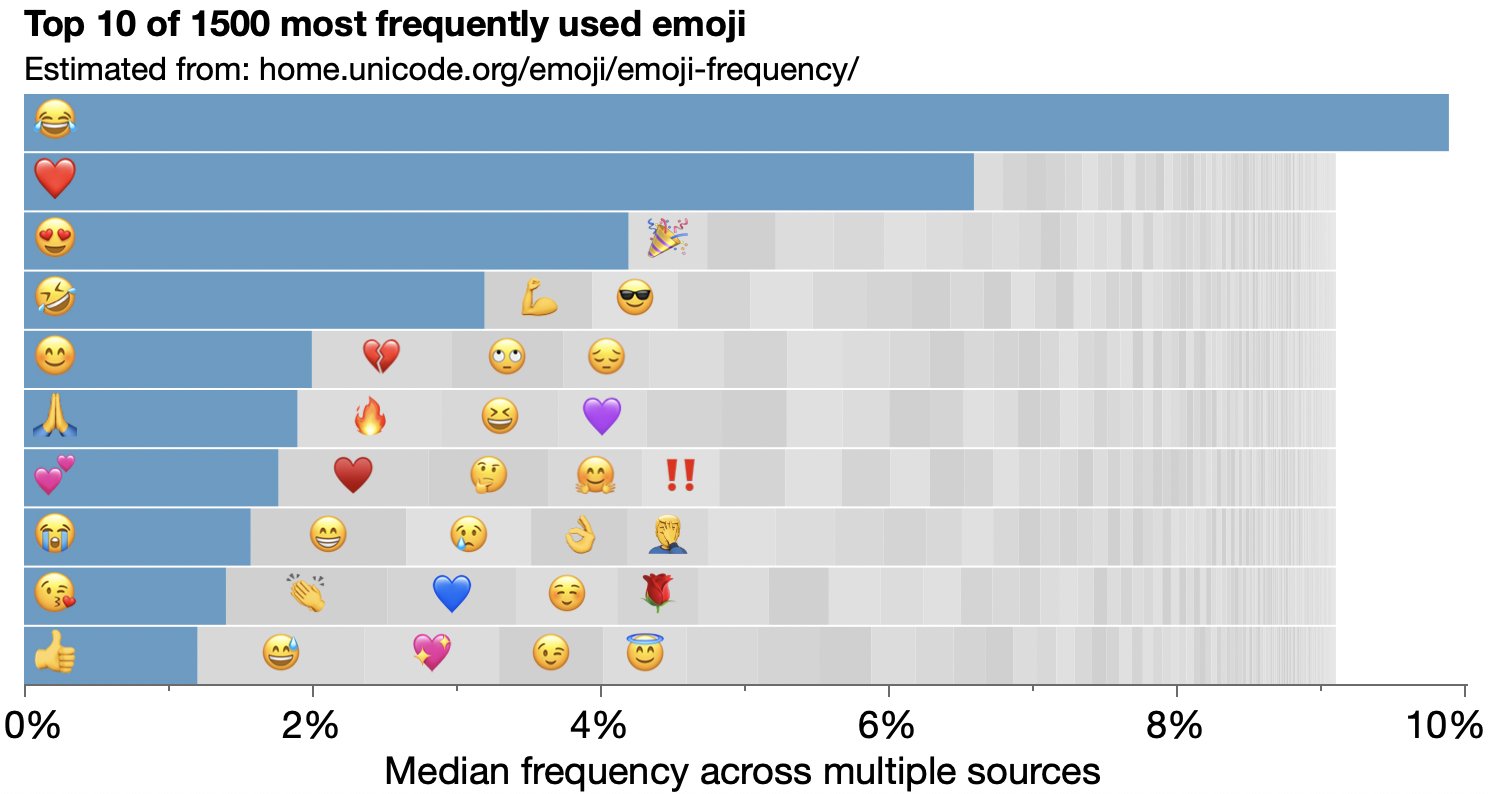
I remade an emoji pie chart as packed bars and then someone suggested packed circles, so I tried that, too.
November
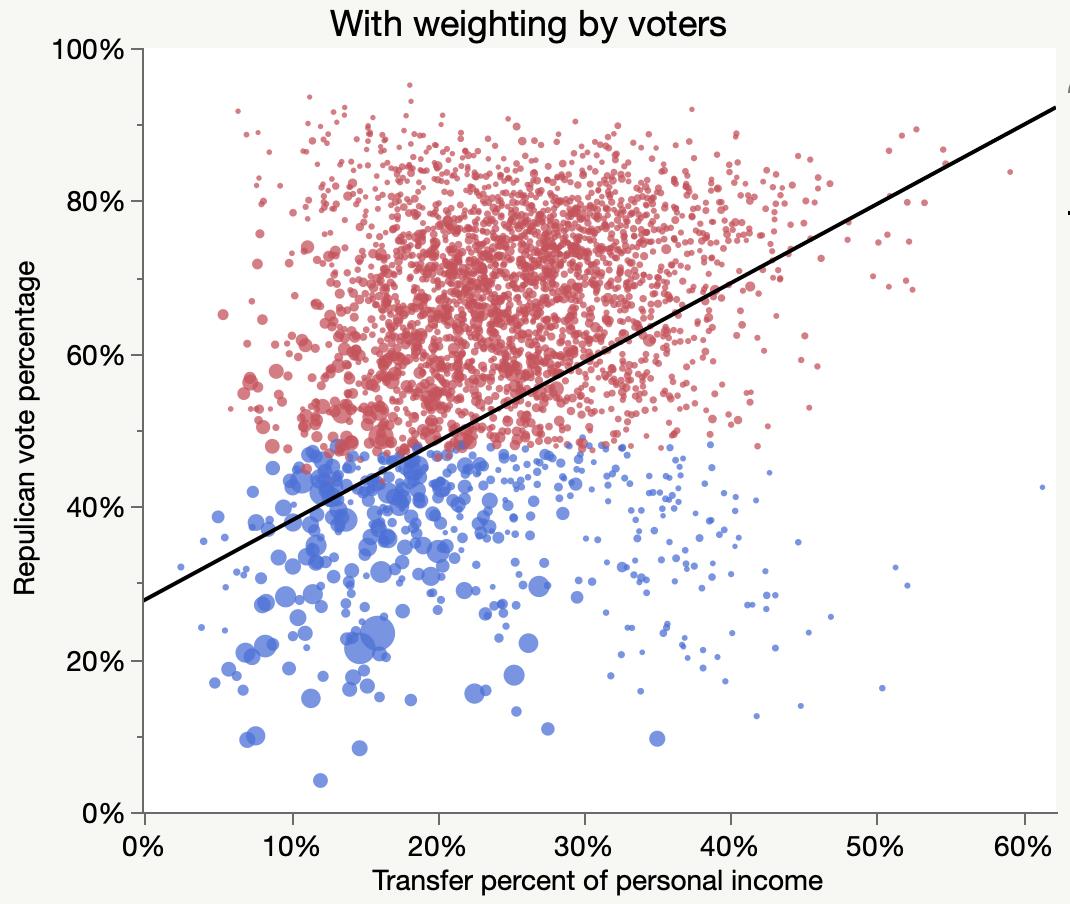
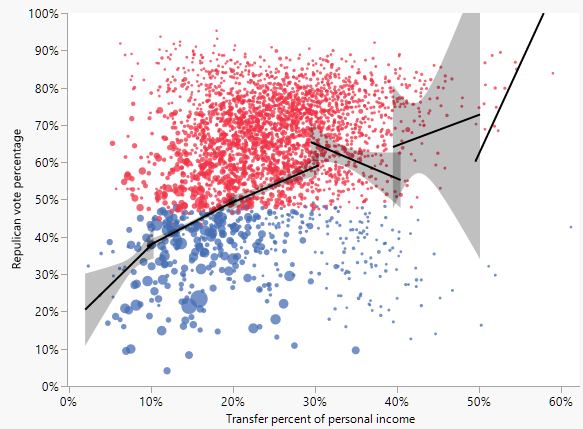
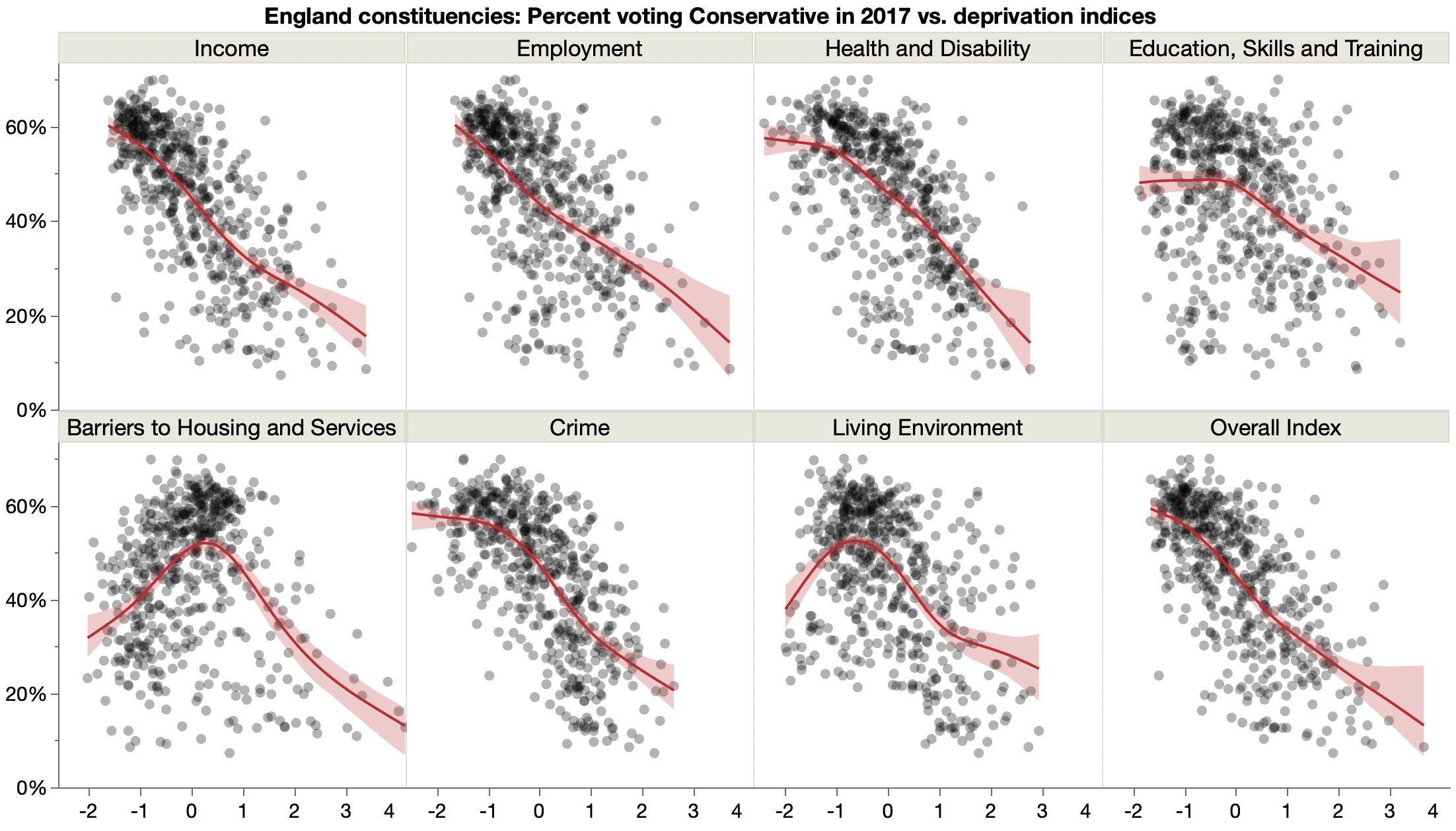
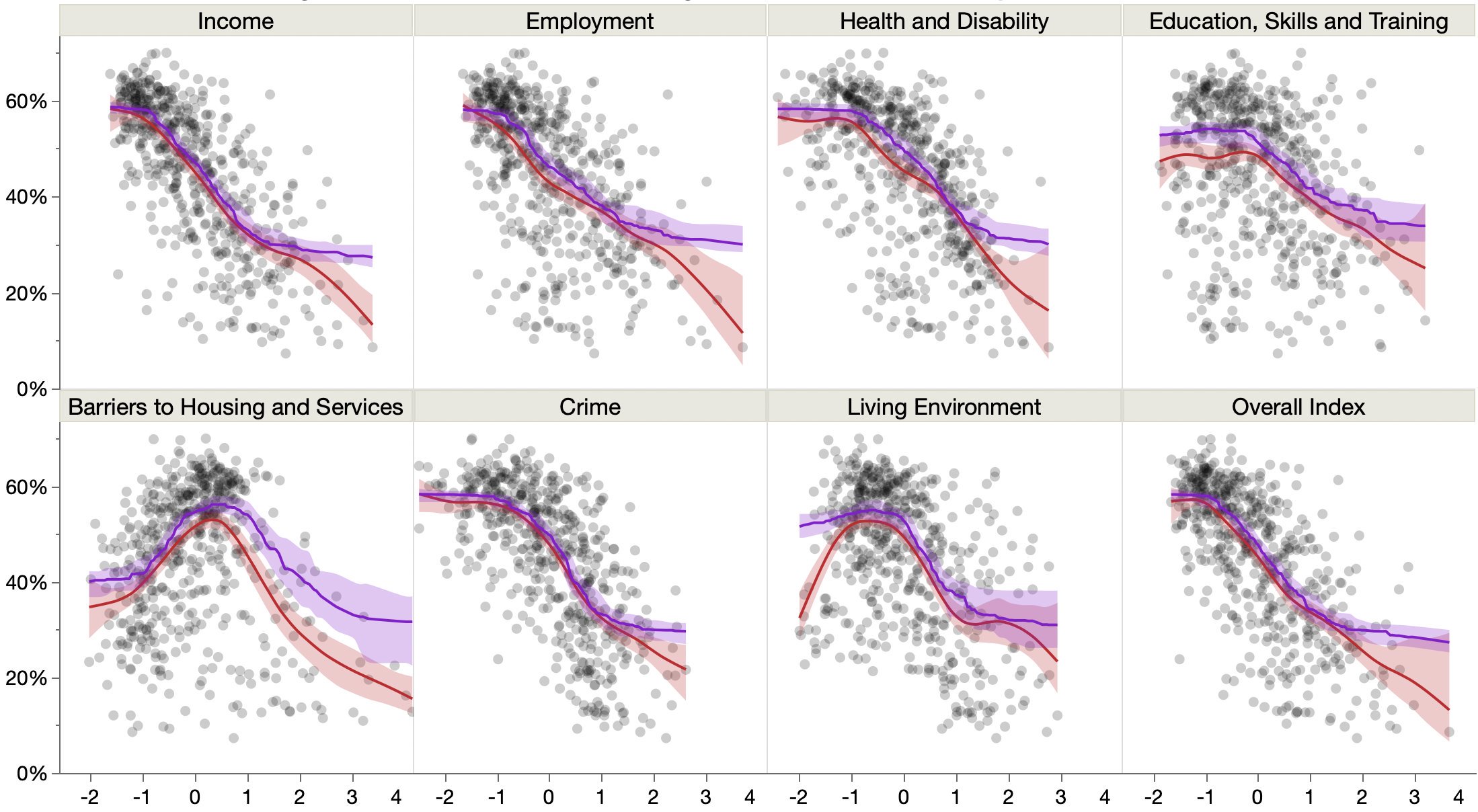
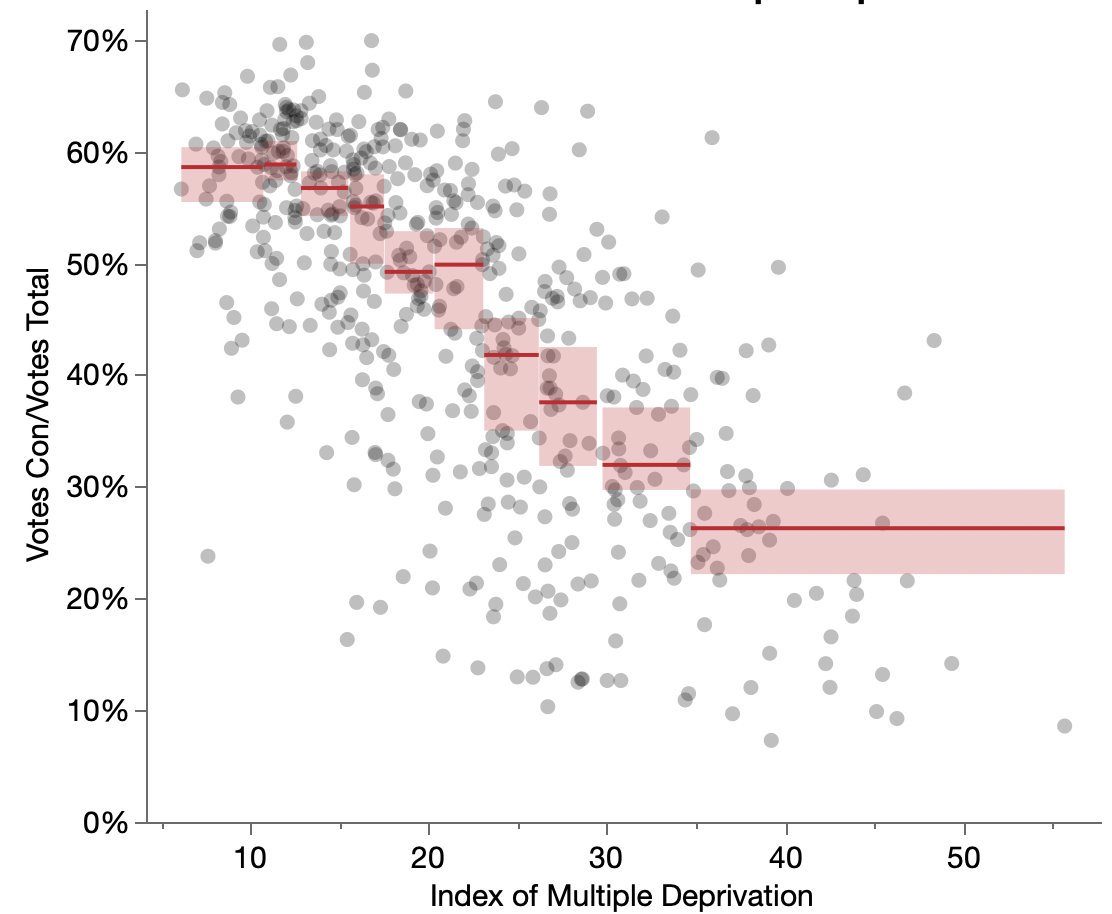
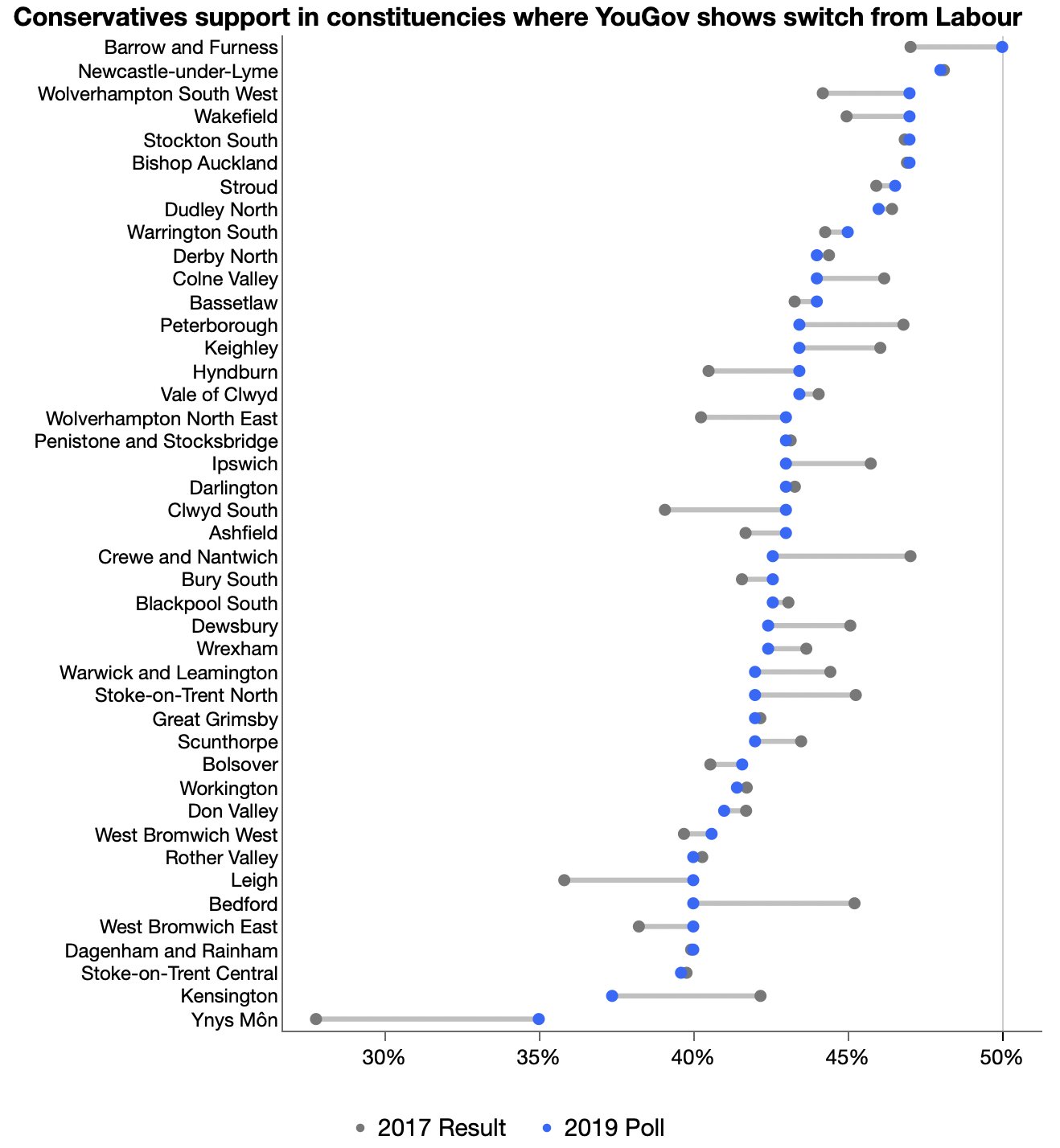
Looking at UK Conservative votes versus deprivation measures.
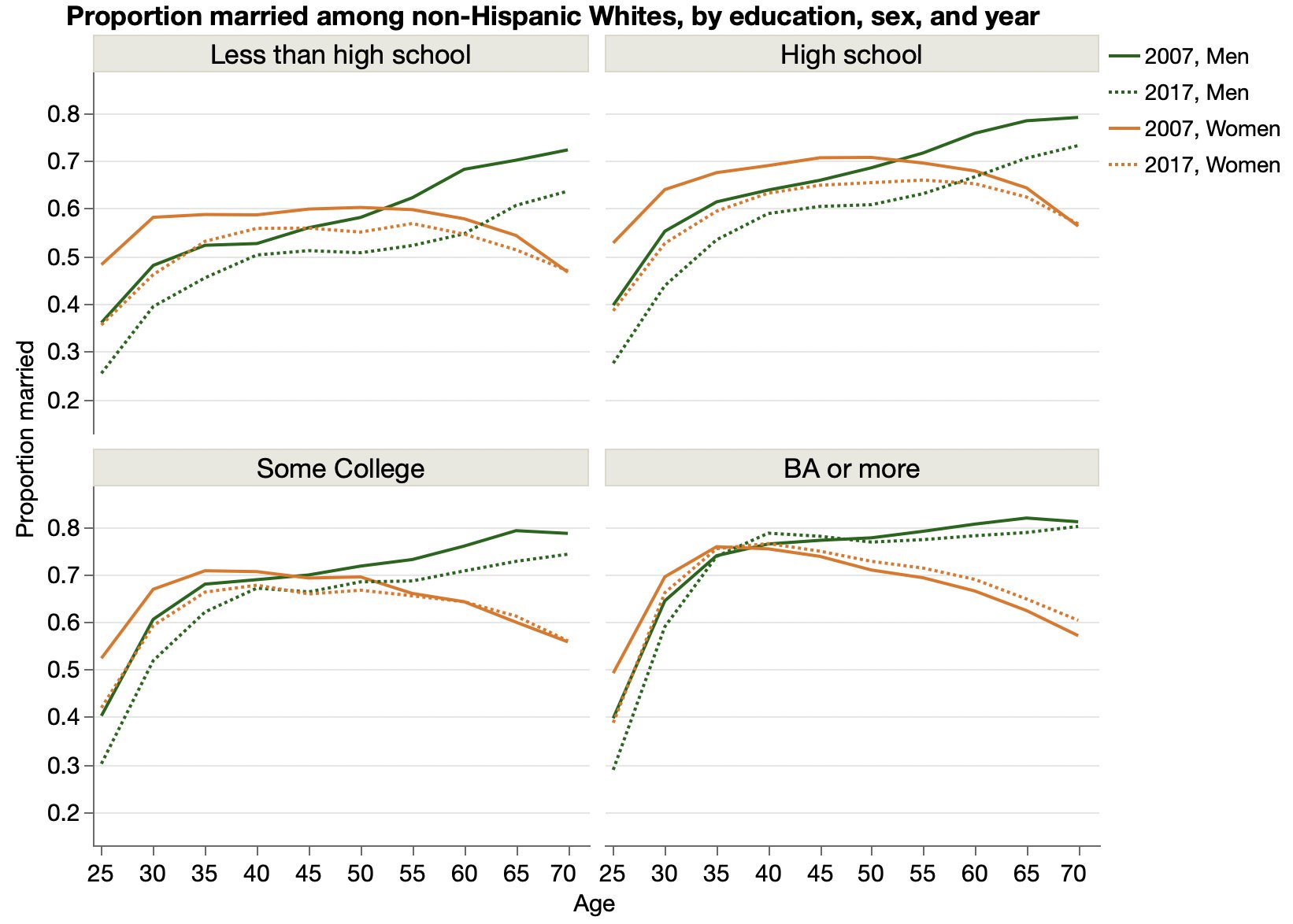
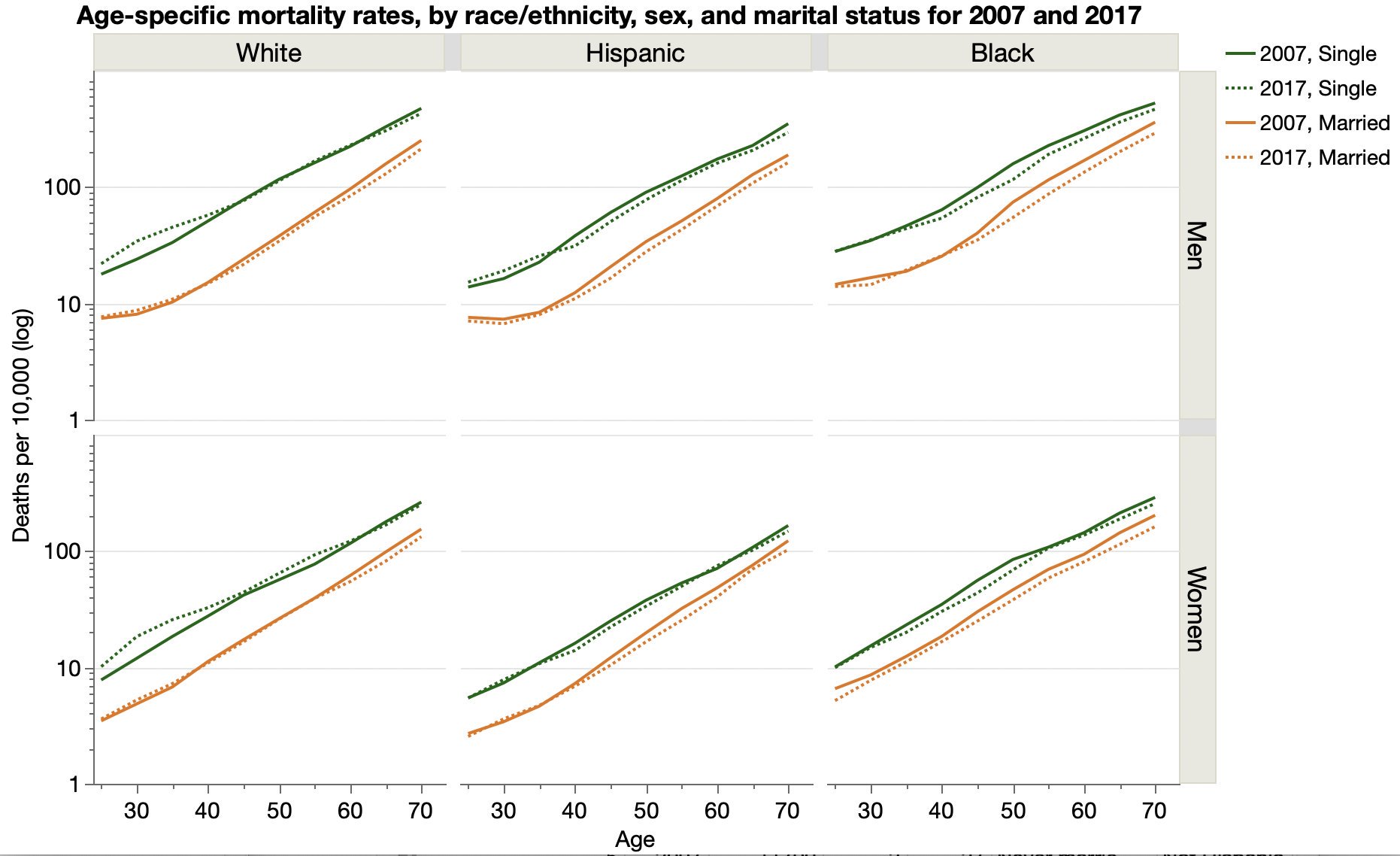
After a marriage statistics paper shared their data and details, I was able to reproduce the results.
Here’s a sampling of several graphs I posted in a study of a chord diagram (see also my previous blog post).
Makeover of a study paper, removing a dubious log scale.
Answering a question about histogram binning.
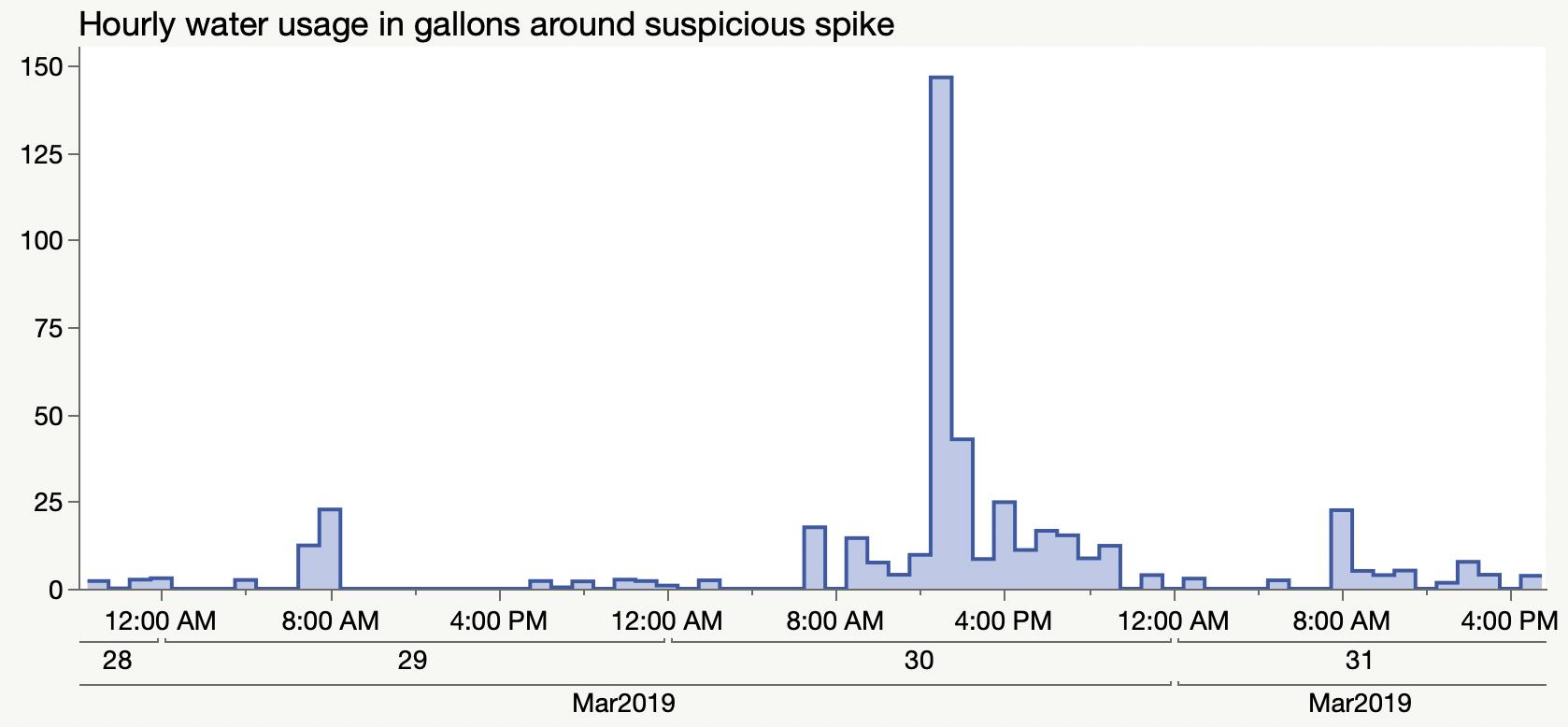
This underground water leak took a while to find and fix, but it was nice to see the data, at least.
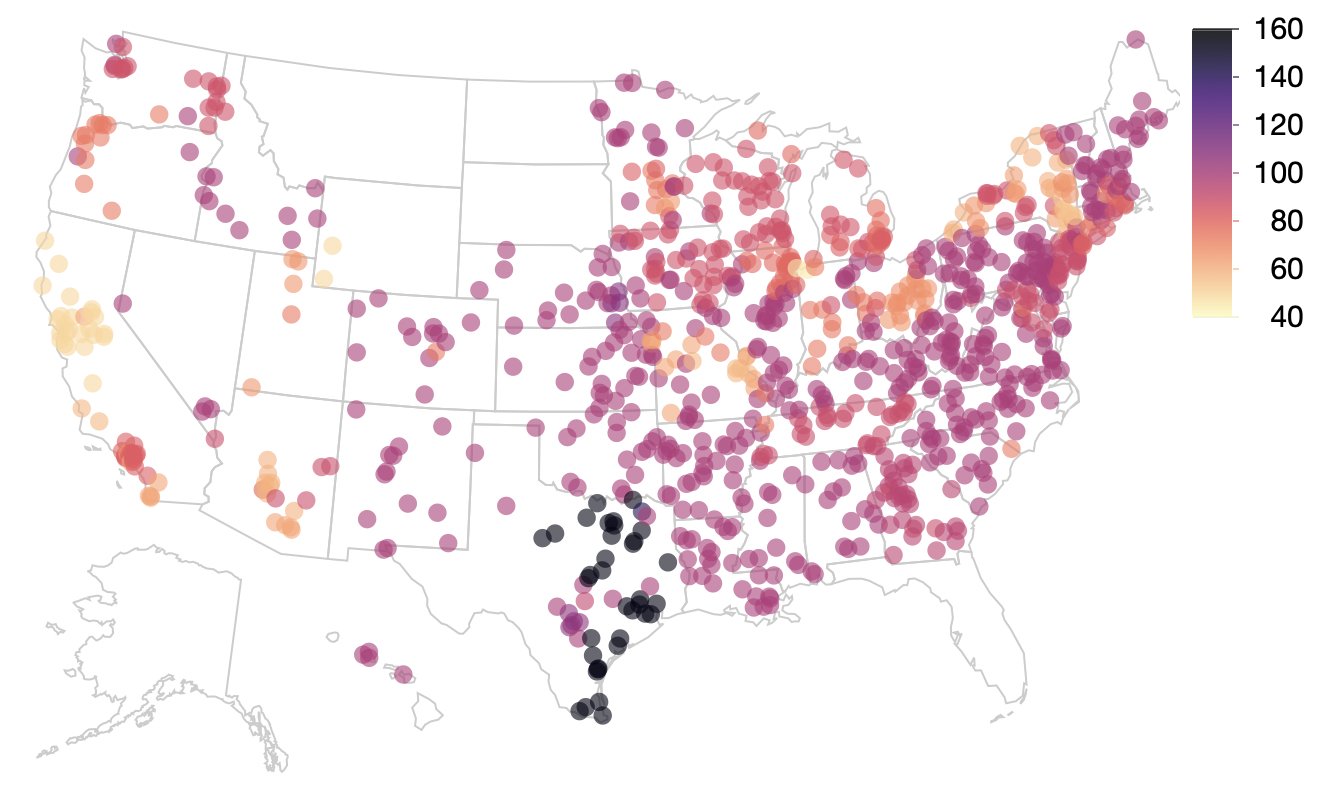
Making an example geographic scatter plot.
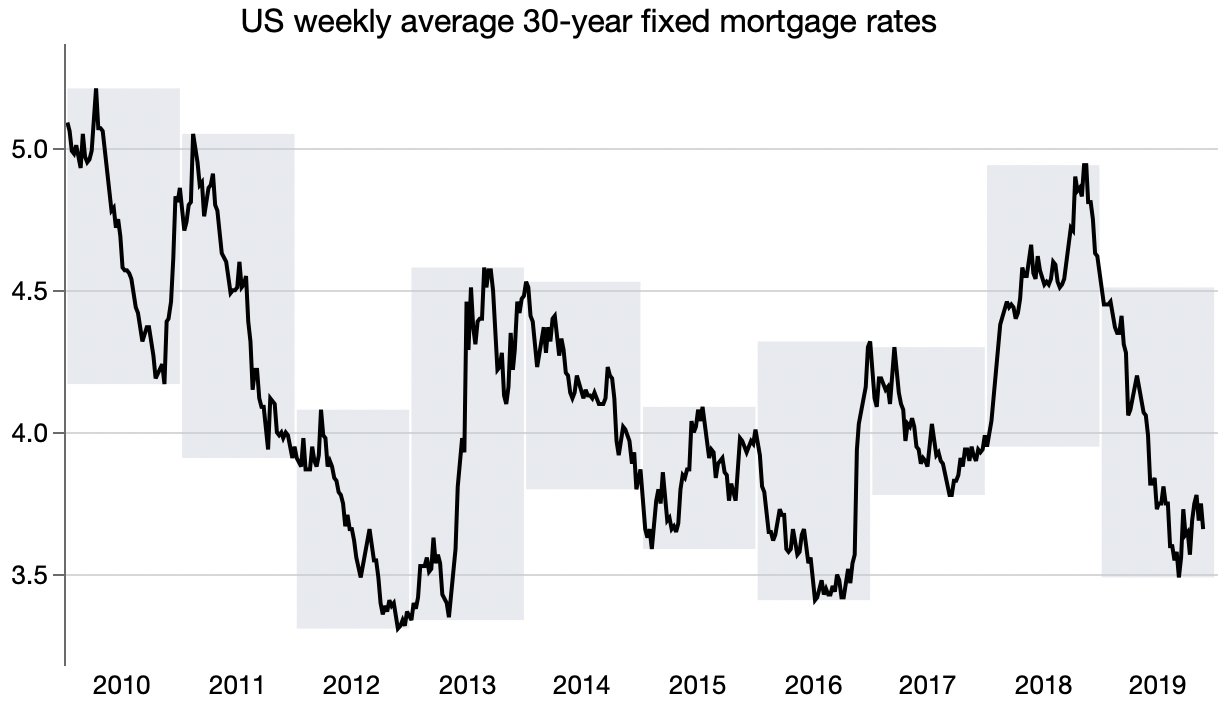
Trying out a shading idea from Len Kiefer.
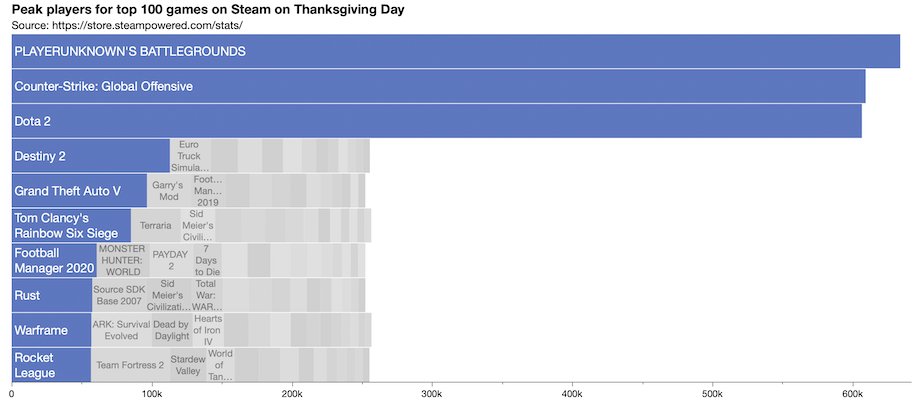
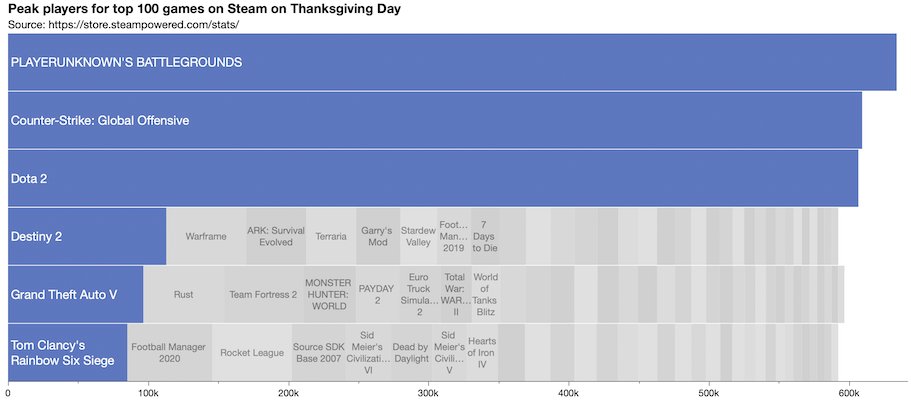
Data from Steam gaming usage.
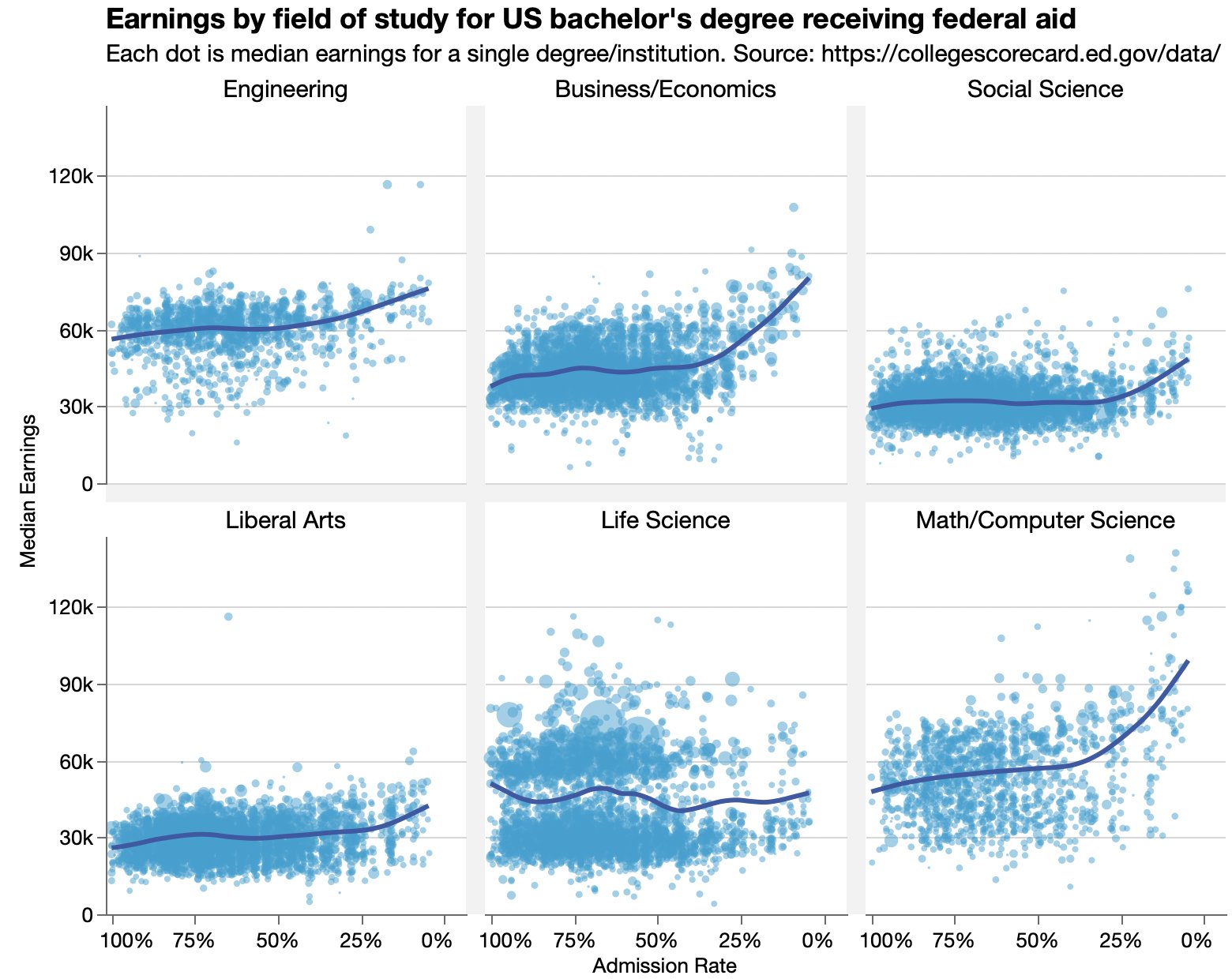
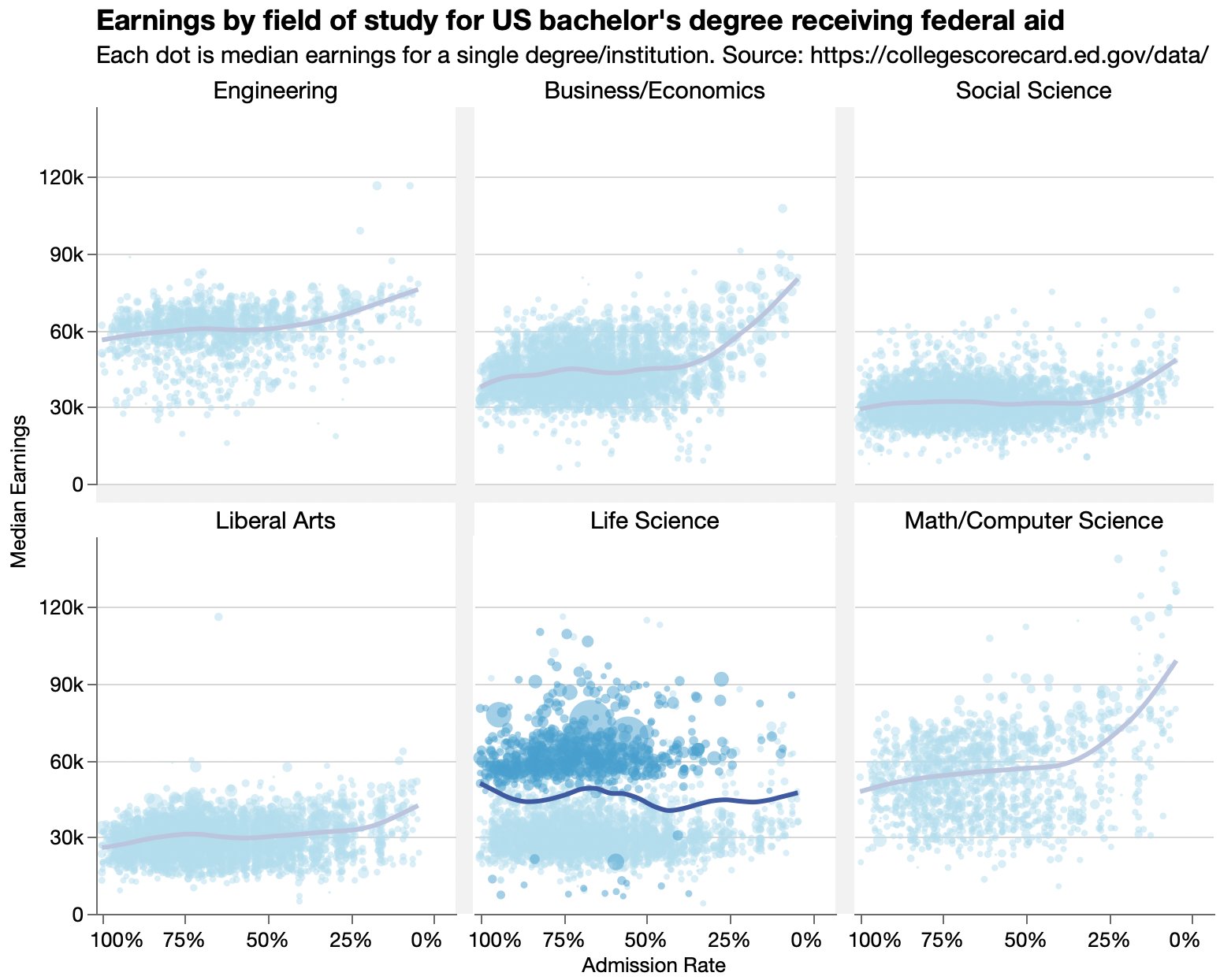
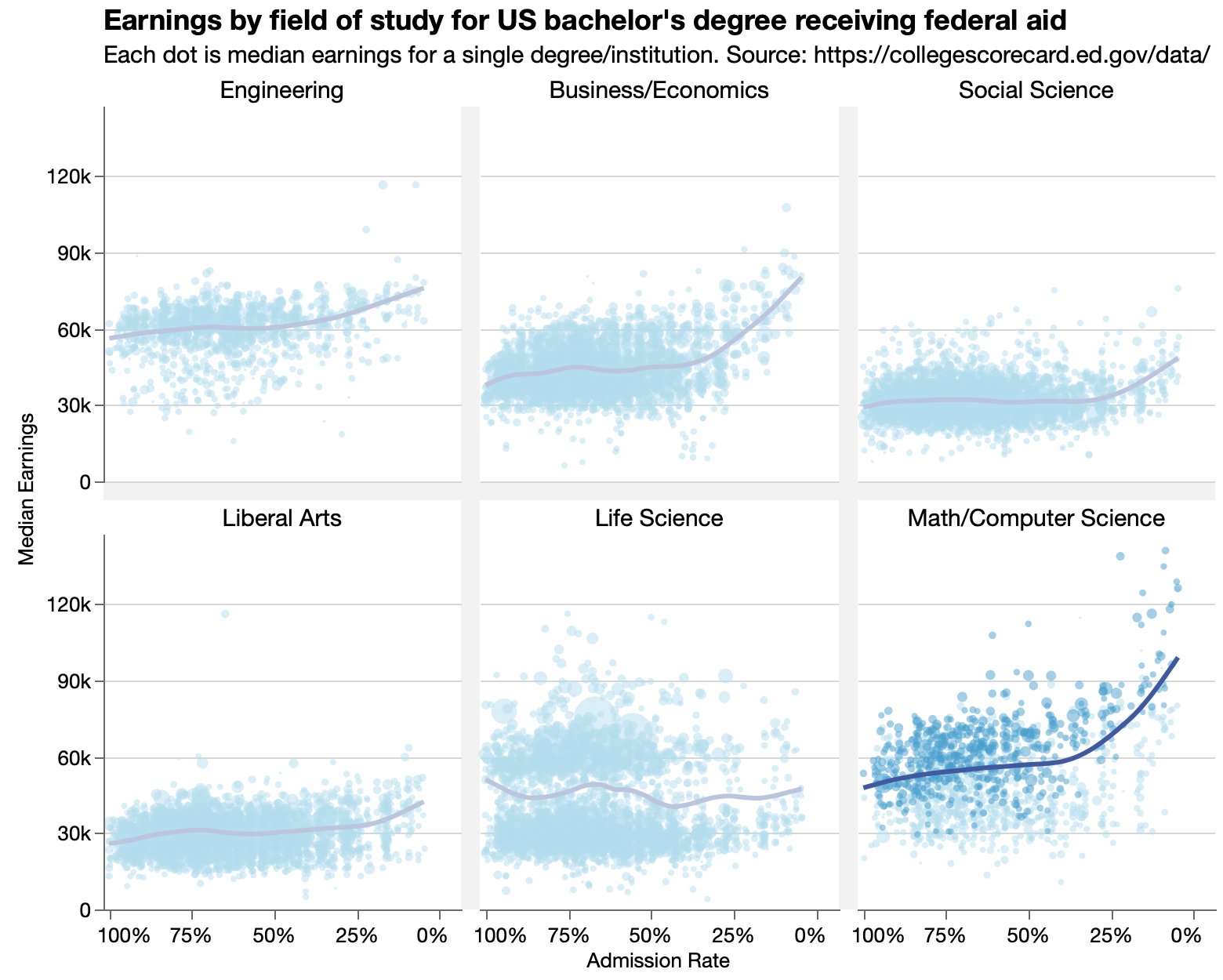
Looking at data from an Economist graphic about earning for college graduates versus the colleges’ admission rates.
December
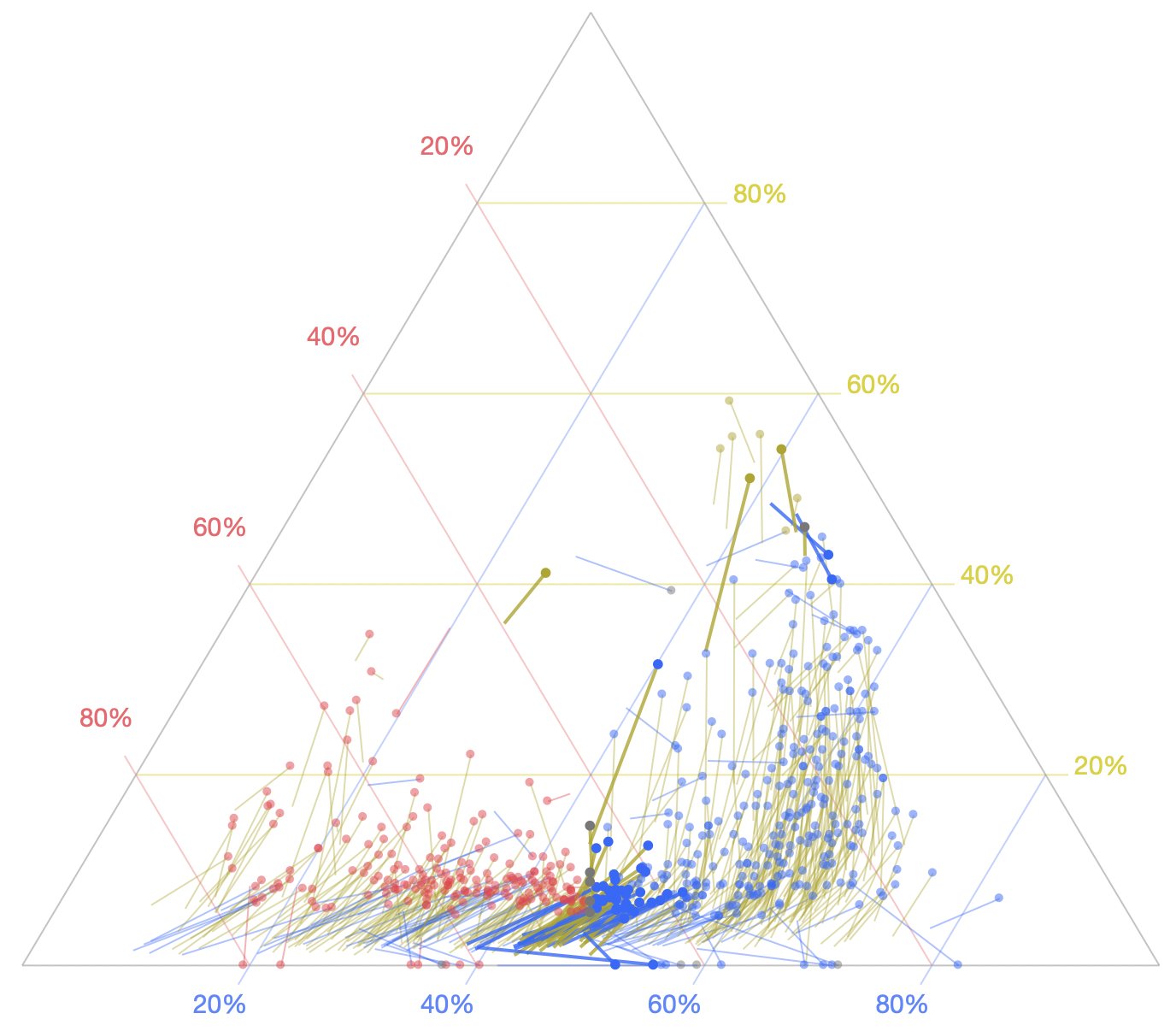
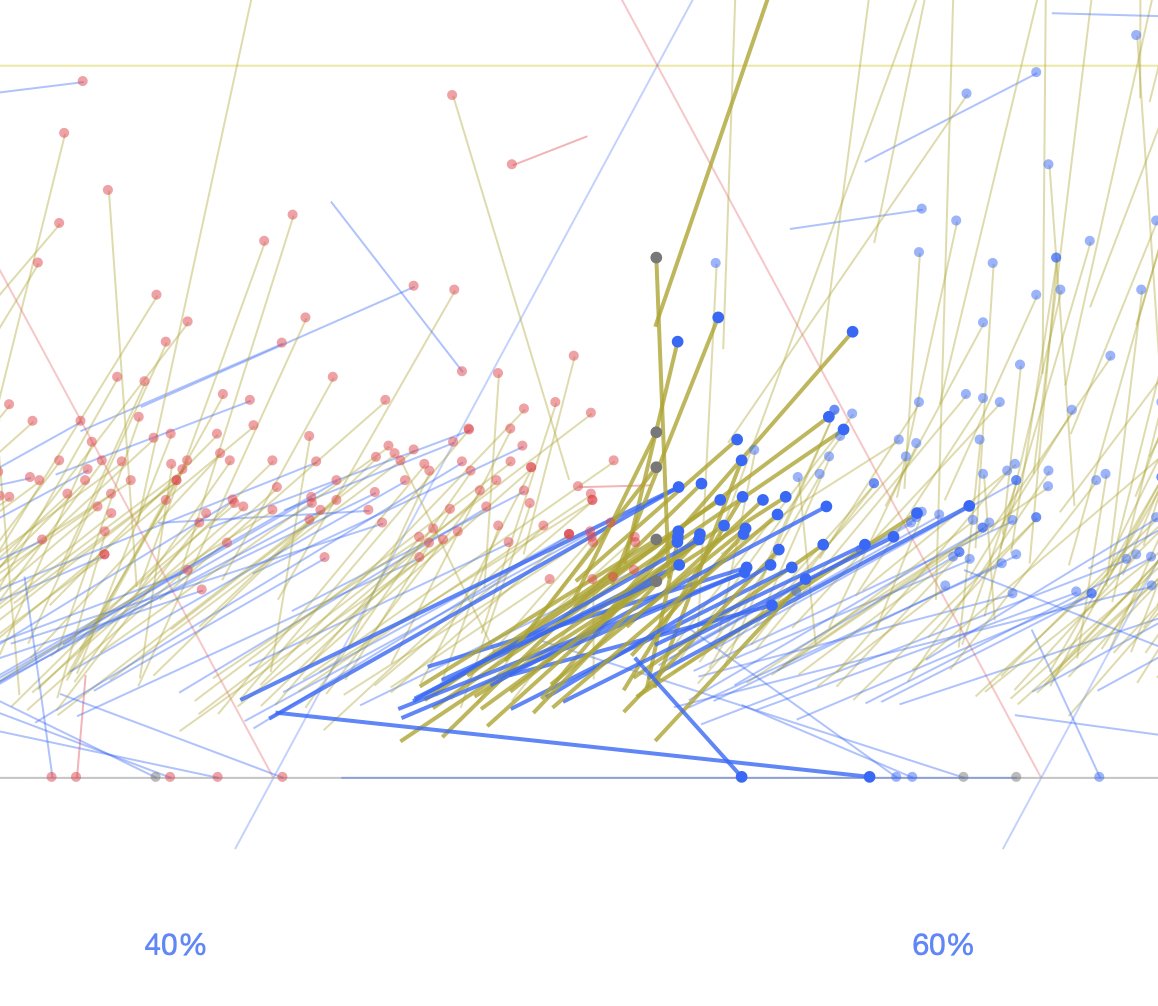
Despite knowing next to nothing about UK politics, I tried some graphical reproductions and explorations based on an Economist ternary chart.
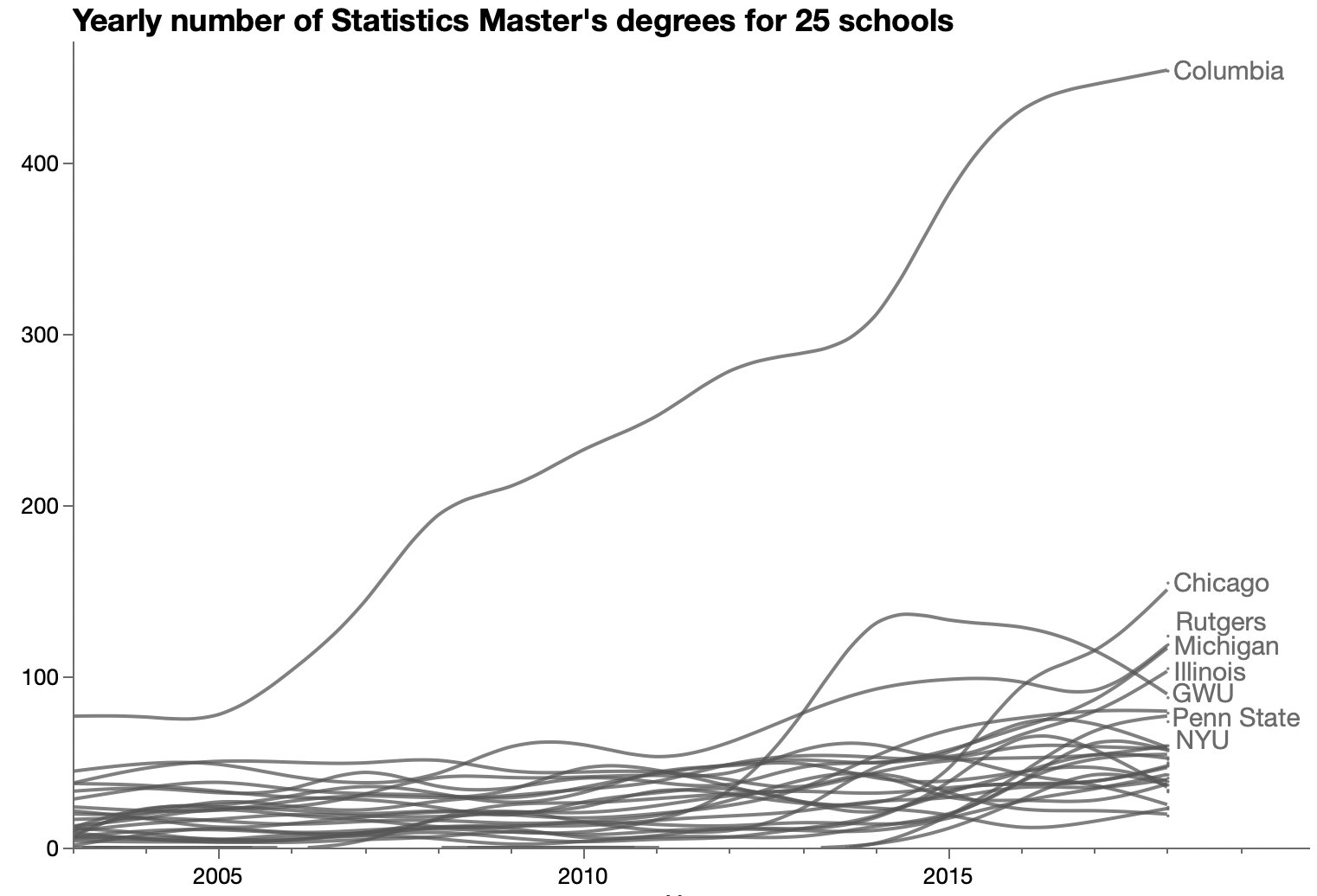
Comparing stats masters programs. I’ve still don’t know why Columbia is so far above the others in number of students.
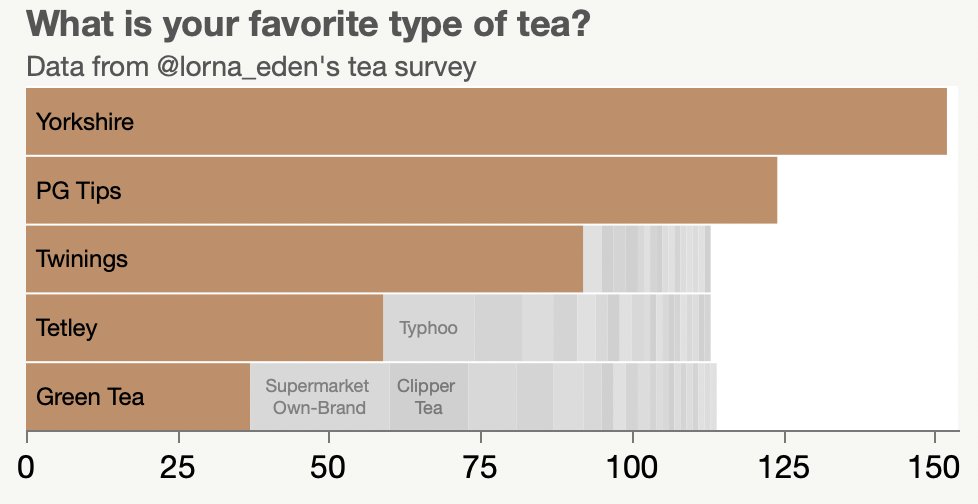
The September edition of Andy Kirk’s Best of the Visualisation Web includes a Reuters Graphics article, India is running out of water, which explores India’s water sources. The main sources are groundwater (from wells) and surface water (from lakes and rivers). The article shows how some regions are using more groundwater than is being replenished. I feel like I learned a lot about the water supply in India, so I consider it a successful article.
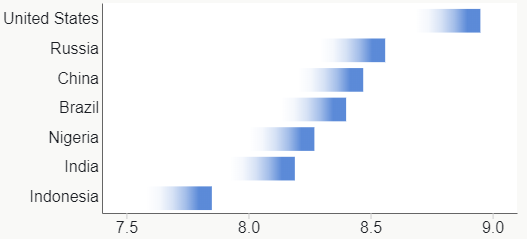
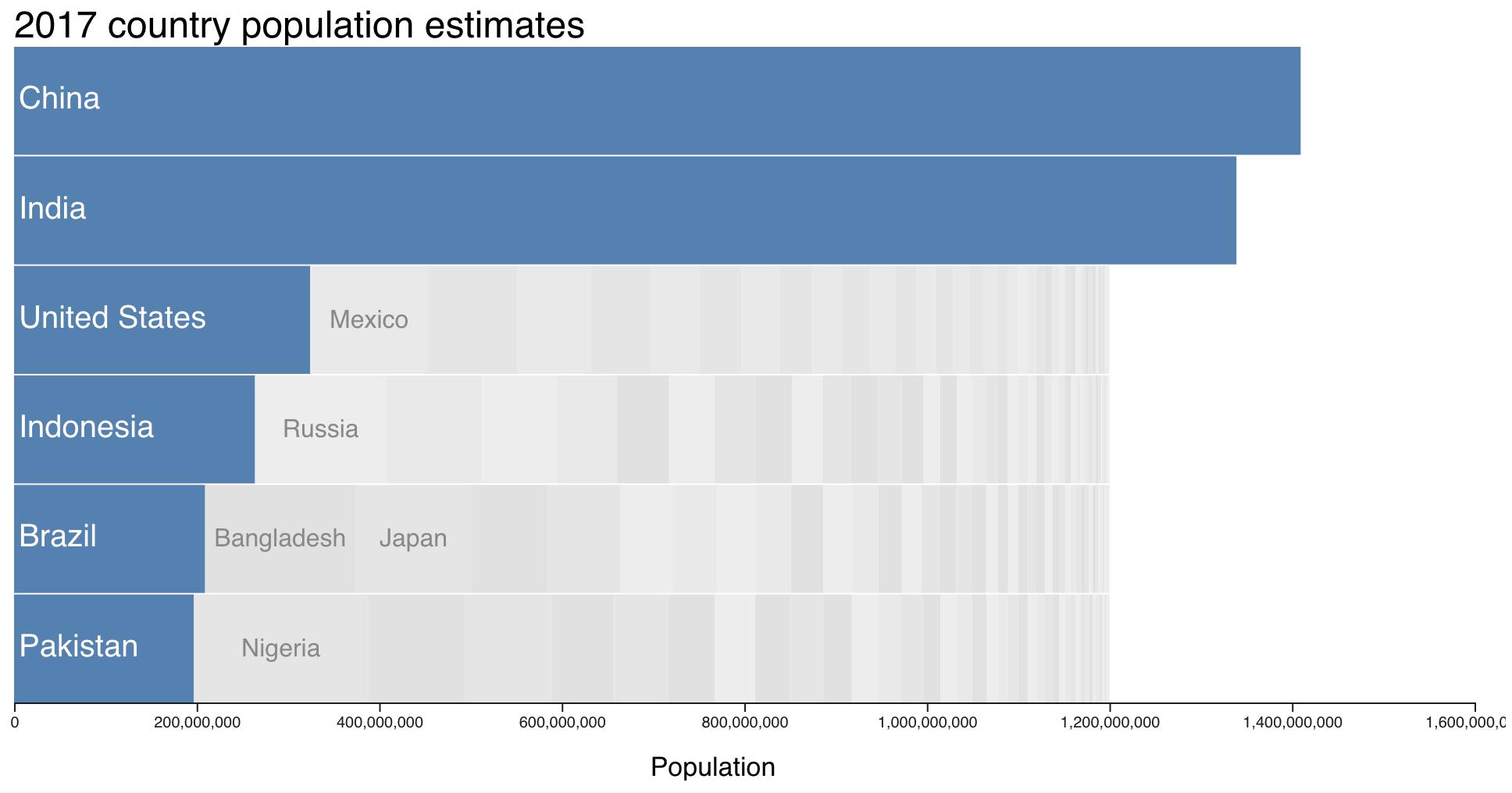
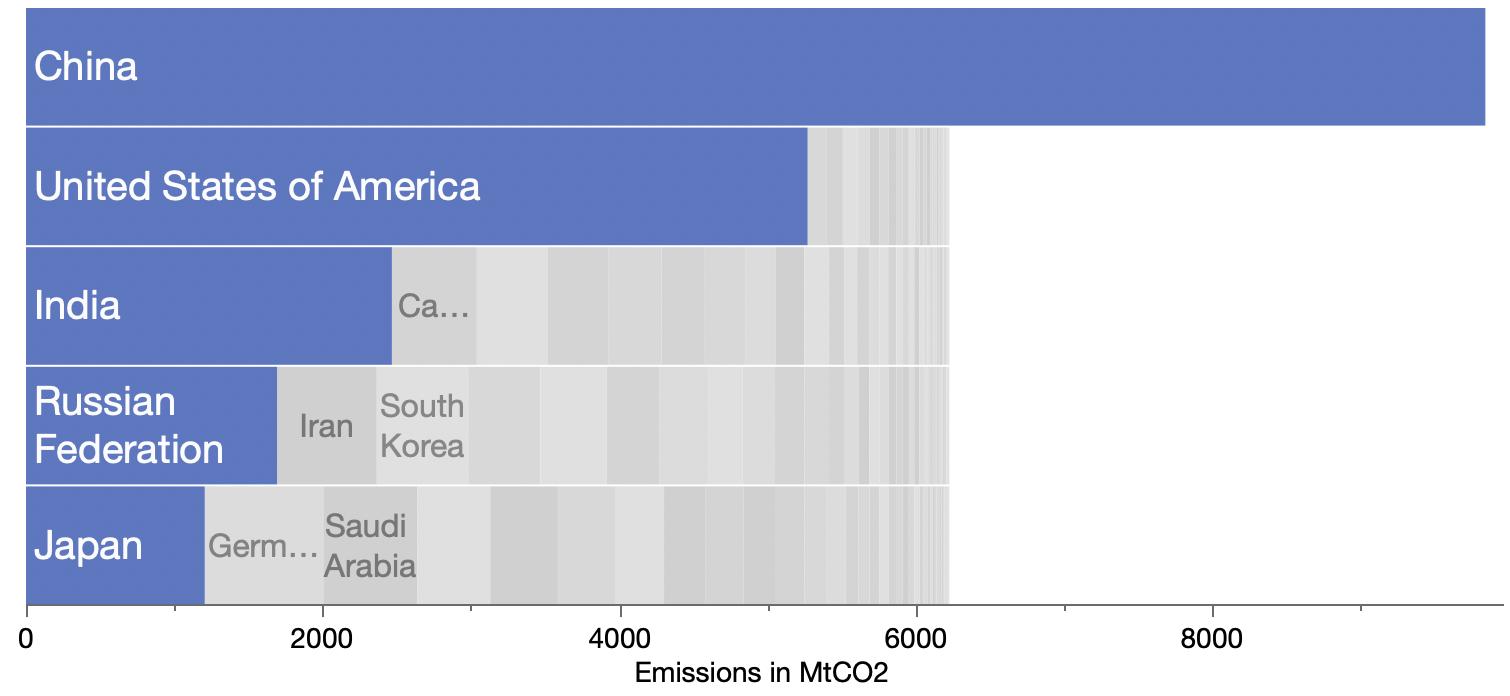
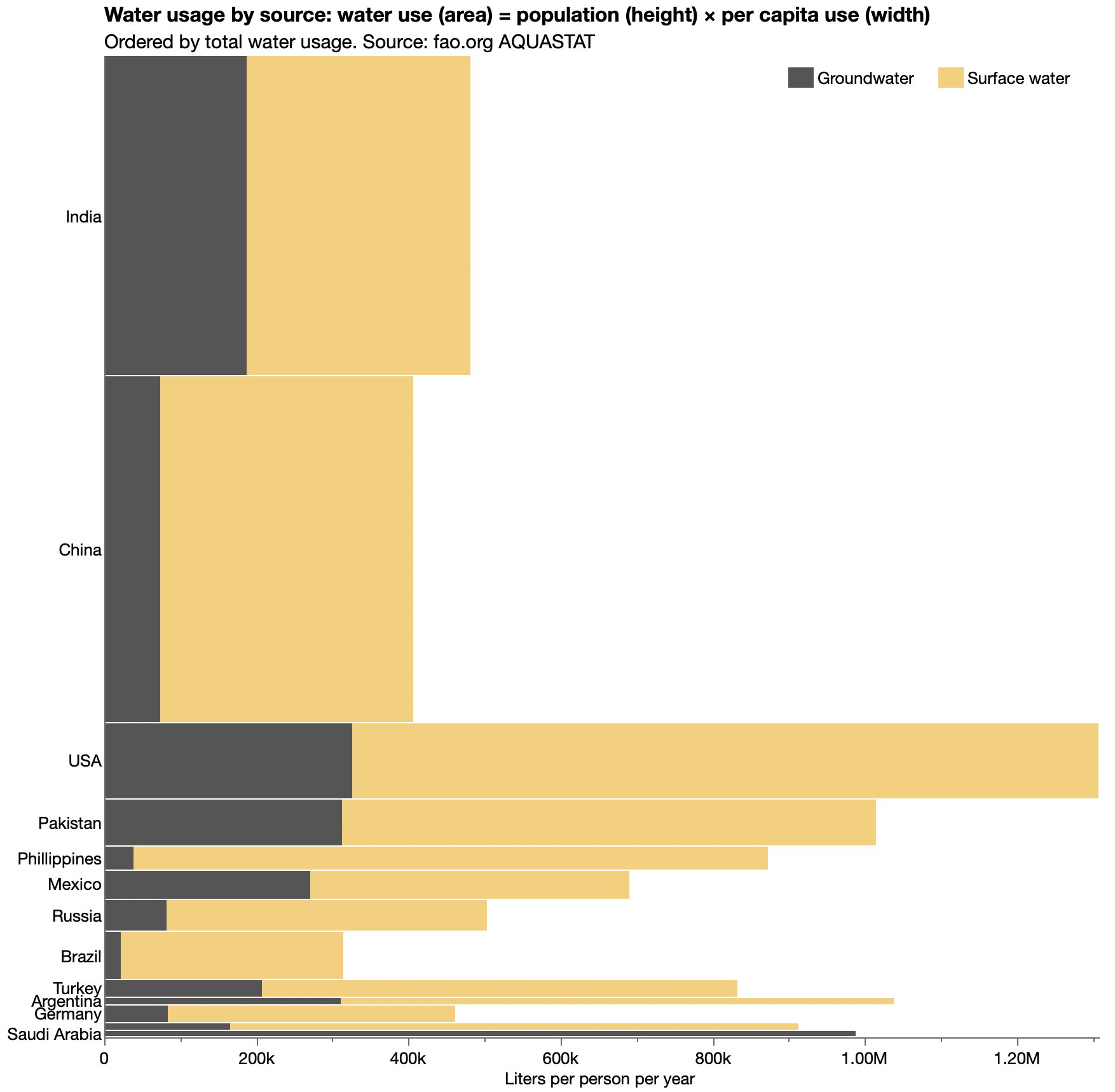
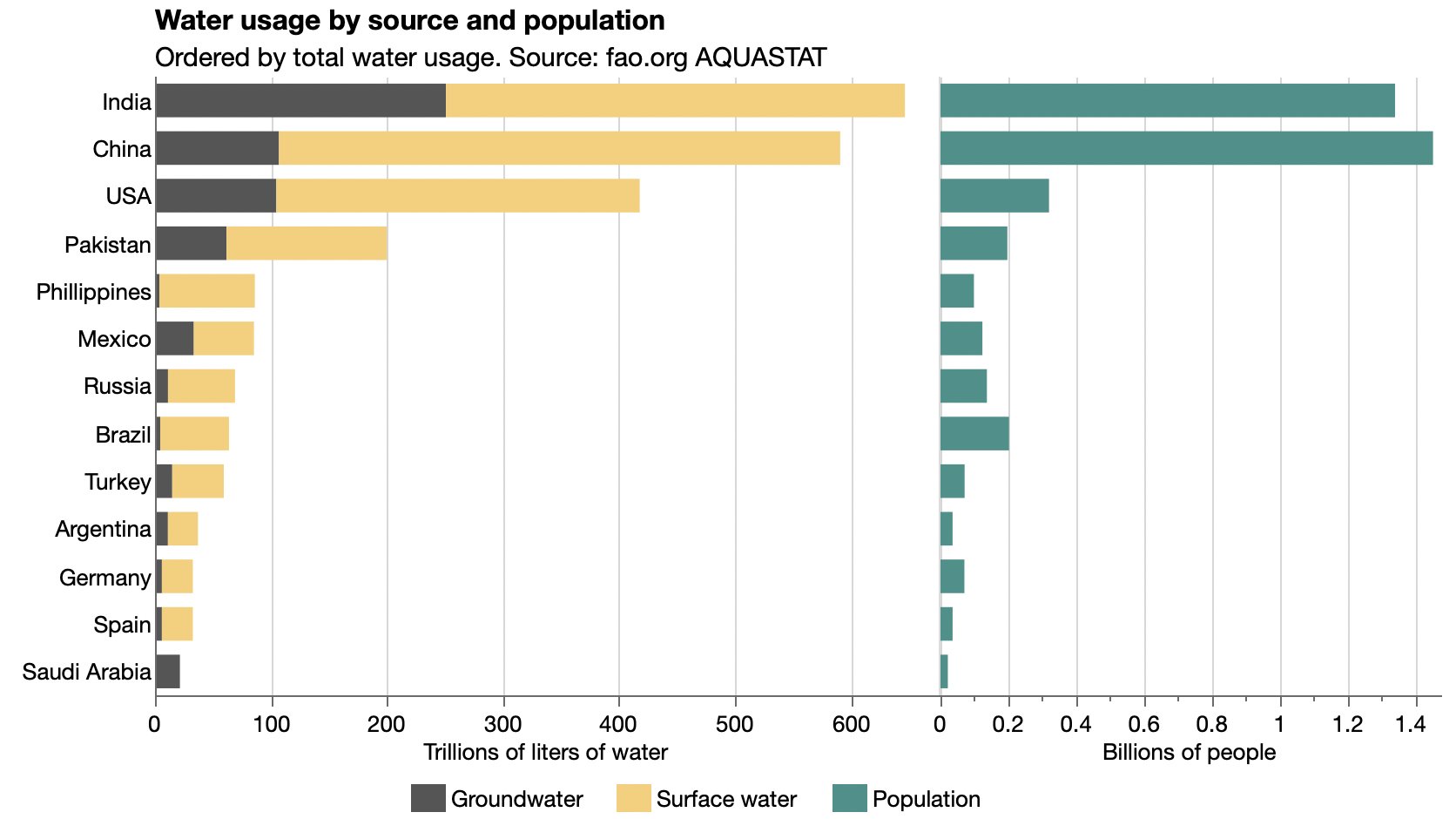
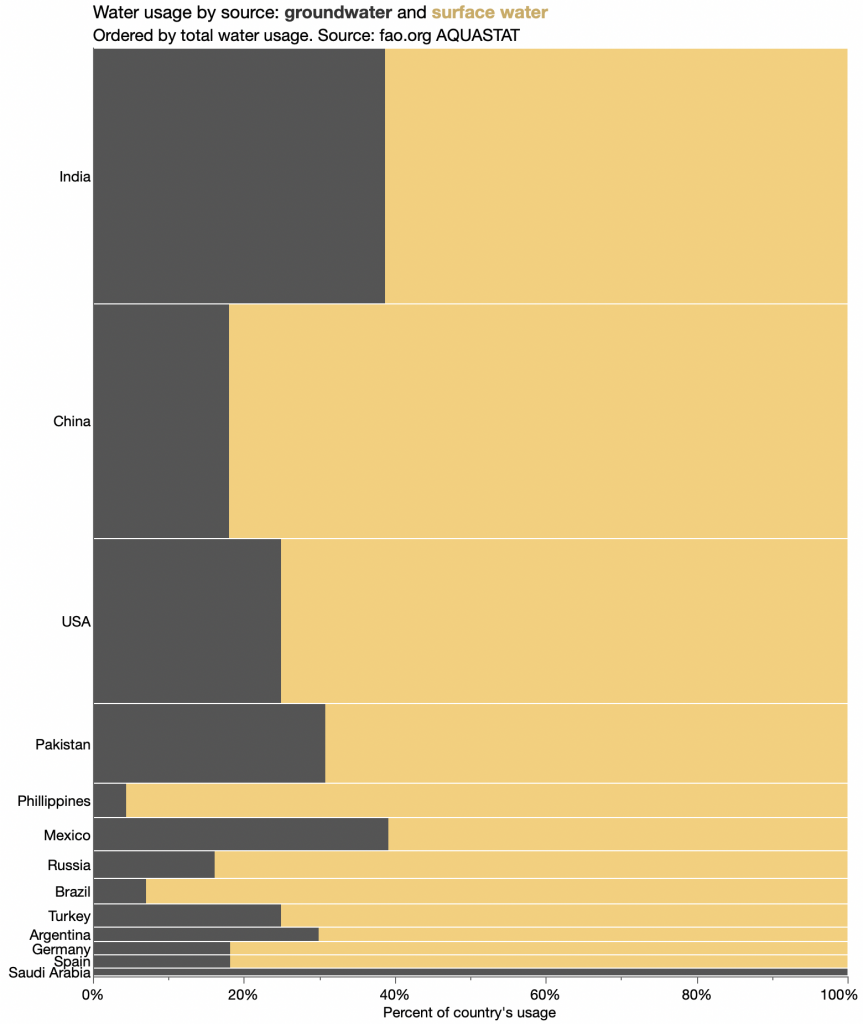
However, one chart puzzled me: this graphic comparing India with select other countries.
The form is called “bar-mekko” as a hybrid between a (stacked) bar chart and a marimekko or mosaic chart. That is, the bars have variable breadth according to some other variable. (I’ll use breadth and length as the rectangle dimensions, thinking height and width are more ambiguous for horizontal bars. For this chart, breadth is along the Y axis and length is along the X axis.)
I’m not sure bar-mekko is a good chart form in general, but I found this one particularly troublesome. Ignoring the color stacking as an orthogonal feature, three different quantities are visually represented by each rectangle: the breadth, the length and the area. But in this case, the area has no meaningful interpretation. Area is population × water use. The viewer sees area differences but has to ignore them, which is extra decoding work. For instance, USA is not far behind India and China in total usage (bar length), but you might think otherwise at first since it’s much smaller by area,
On Twitter, I suggested this rule for bar-mekko charts:
Area must have a meaningful interpretation.
Or more generally, for all charts:
All visual encoding channels in use must have meaningful interpretations.
To better understand the bar-mekko form, I set out to make a bar-mekko chart with this data where breadth, length and area all had meaningful interpretations.
Getting the data
The article cites several data sources, and I found most of the country-level data from the UN’s FAO AQUASTAT database. For some reason India was not there, so I read those values off the original chart. In the process of understanding the data, I found two errors.
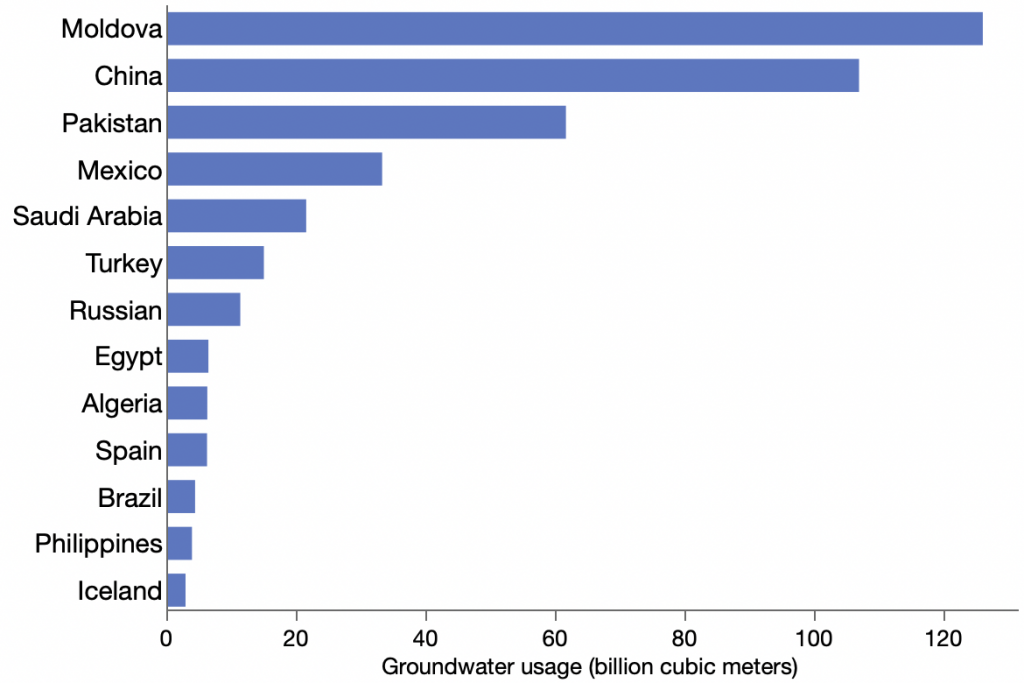
I downloaded recent water use data for all available countries and checked the top groundwater users to see if there were any other major groundwater users. India and USA were missing, but I was surprised that the Republic of Moldova was the top withdrawer of groundwater.
For a moment, I thought Moldova might have massive wells that supply all of Eastern Europe, but looking closer at the data, I saw that Moldova’s previous groundwater usage figure was about 1000x less, 0.129 versus 126. So likely it was a misplaced decimal point. I reported the issue to the AQUASTAT contact, and they responded quickly, confirmed the issue and quickly corrected the online database. Yea!
The other data error was discovered reading the India values from the original chart. Its X axis is in millions of liters. 600 million liters per year doesn’t seem like much for a country with over a billion people. Even as daily usage that wouldn’t be much. I now think it should be trillions of liters instead. The AQUASTAT data is in billions of cubic meters, and I suspect the author divided by 1000 instead of multiplying by 1000 to convert cubic meters to liters. However, I haven’t heard a response after sending a message to that effect.
Remake as bar-mekko
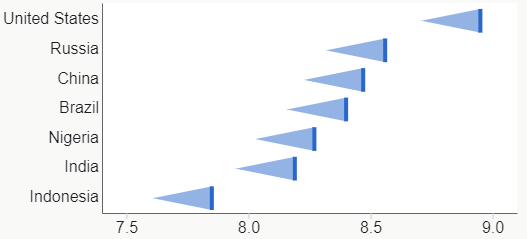
To follow the meaningful area rule, I sought to keep population as the rectangle breadth and use per-capita water use as the length, which would make area correspond to total usage.
It works, but the main message of the article, comparing India’s total water usage, is no longer so prominent. It’s still there, both in the area sizes and in the rank order of the Y axis, but the length of the bar along the X axis is most noticeable and easiest to compare. So the main message is the per-capita usage.
Other features of note: I’m not sure why this subset of countries was chosen for the original article, but I added Pakistan since it also has a lot of water usage and is near India. Oddly, Pakistan’s per-capita usage is more like the USA. Also, the unlabeled bar is Spain. Labeling is a challenge with variable-breadth bars; I could have used a tiny font like the original did, or squeezed in a special label, but I was too lazy.
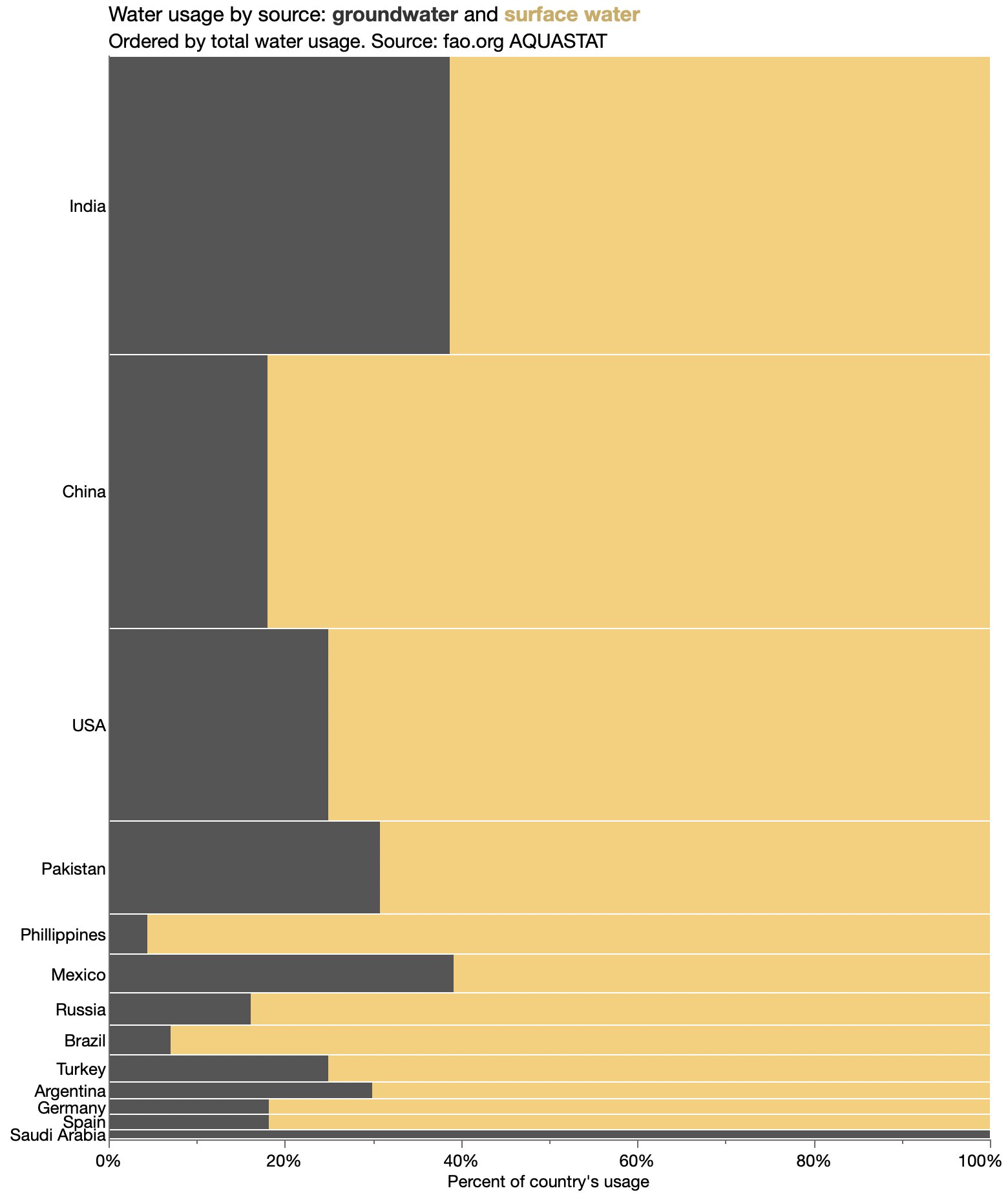
Remake as mosaic
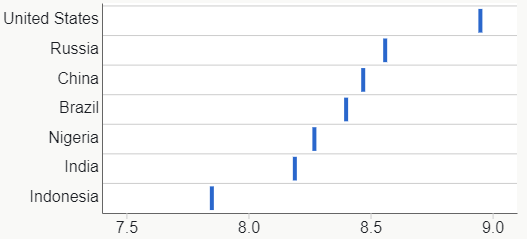
A traditional mosaic chart is more about proportions.
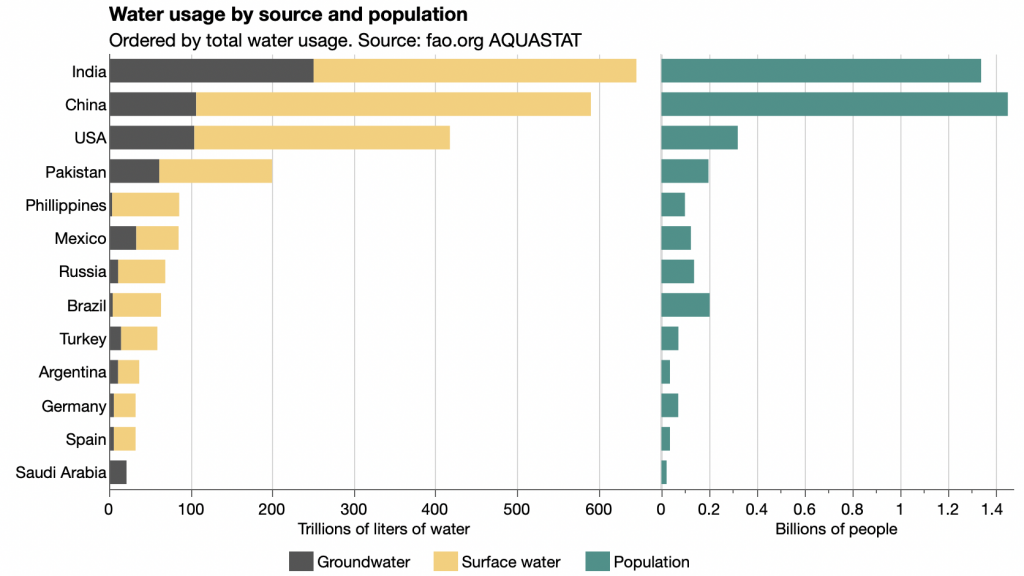
The breadths correspond to water usage for the entire country, the lengths correspond to the relative breakdown within country, and the areas correspond to the water usage for that country and source. Now it’s the proportion of each water source that’s easiest to compare.
I believe that it is always easier (and uniform) to compare components and the results of any math calculation (that includes basic arithmetic operations as well) than encoding the components and the results in one view.
That’s the thinking behind my bar chart version.
Now it’s easy to compare both the total water usage and the groundwater usage among countries without the area distraction or the tight labeling challenges.
After just missing advancing out of Google Code Jam Round 1A, I tried again in Round 1B and again in Round 1C, but with no success. I guess I haven’t adapted well to the new interactive problems. In both cases, I got the first problem solved and then got stuck on the second problem, which was interactive in both cases. The interactive problems require your submission exchange messages with another program to work out the solution, which makes it a bit different to debug.
In the interest of advancing, I should have moved on to the third problem or just did the easier subset of the interactive problem. But I’m only doing this for the fun of the challenge, and it was fun to eventually work out the solution, even though it took me a little longer than the allotted time.













:format(webp):no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/3362104/Screen_Shot_2014-10-09_at_10.54.30_AM.0.0.png)