The September edition of Andy Kirk’s Best of the Visualisation Web includes a Reuters Graphics article, India is running out of water, which explores India’s water sources. The main sources are groundwater (from wells) and surface water (from lakes and rivers). The article shows how some regions are using more groundwater than is being replenished. I feel like I learned a lot about the water supply in India, so I consider it a successful article.
However, one chart puzzled me: this graphic comparing India with select other countries.

The form is called “bar-mekko” as a hybrid between a (stacked) bar chart and a marimekko or mosaic chart. That is, the bars have variable breadth according to some other variable. (I’ll use breadth and length as the rectangle dimensions, thinking height and width are more ambiguous for horizontal bars. For this chart, breadth is along the Y axis and length is along the X axis.)
I’m not sure bar-mekko is a good chart form in general, but I found this one particularly troublesome. Ignoring the color stacking as an orthogonal feature, three different quantities are visually represented by each rectangle: the breadth, the length and the area. But in this case, the area has no meaningful interpretation. Area is population × water use. The viewer sees area differences but has to ignore them, which is extra decoding work. For instance, USA is not far behind India and China in total usage (bar length), but you might think otherwise at first since it’s much smaller by area,
On Twitter, I suggested this rule for bar-mekko charts:
Area must have a meaningful interpretation.
Or more generally, for all charts:
All visual encoding channels in use must have meaningful interpretations.
To better understand the bar-mekko form, I set out to make a bar-mekko chart with this data where breadth, length and area all had meaningful interpretations.
Getting the data
The article cites several data sources, and I found most of the country-level data from the UN’s FAO AQUASTAT database. For some reason India was not there, so I read those values off the original chart. In the process of understanding the data, I found two errors.
I downloaded recent water use data for all available countries and checked the top groundwater users to see if there were any other major groundwater users. India and USA were missing, but I was surprised that the Republic of Moldova was the top withdrawer of groundwater.
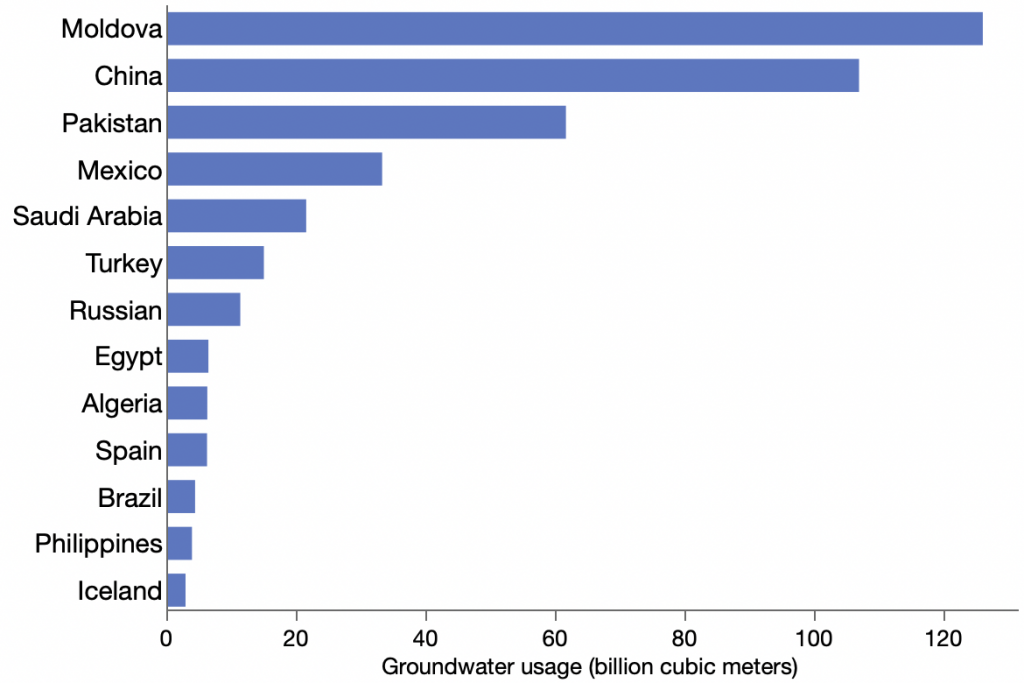
For a moment, I thought Moldova might have massive wells that supply all of Eastern Europe, but looking closer at the data, I saw that Moldova’s previous groundwater usage figure was about 1000x less, 0.129 versus 126. So likely it was a misplaced decimal point. I reported the issue to the AQUASTAT contact, and they responded quickly, confirmed the issue and quickly corrected the online database. Yea!
The other data error was discovered reading the India values from the original chart. Its X axis is in millions of liters. 600 million liters per year doesn’t seem like much for a country with over a billion people. Even as daily usage that wouldn’t be much. I now think it should be trillions of liters instead. The AQUASTAT data is in billions of cubic meters, and I suspect the author divided by 1000 instead of multiplying by 1000 to convert cubic meters to liters. However, I haven’t heard a response after sending a message to that effect.
Remake as bar-mekko
To follow the meaningful area rule, I sought to keep population as the rectangle breadth and use per-capita water use as the length, which would make area correspond to total usage.

It works, but the main message of the article, comparing India’s total water usage, is no longer so prominent. It’s still there, both in the area sizes and in the rank order of the Y axis, but the length of the bar along the X axis is most noticeable and easiest to compare. So the main message is the per-capita usage.
Other features of note: I’m not sure why this subset of countries was chosen for the original article, but I added Pakistan since it also has a lot of water usage and is near India. Oddly, Pakistan’s per-capita usage is more like the USA. Also, the unlabeled bar is Spain. Labeling is a challenge with variable-breadth bars; I could have used a tiny font like the original did, or squeezed in a special label, but I was too lazy.
Remake as mosaic
A traditional mosaic chart is more about proportions.
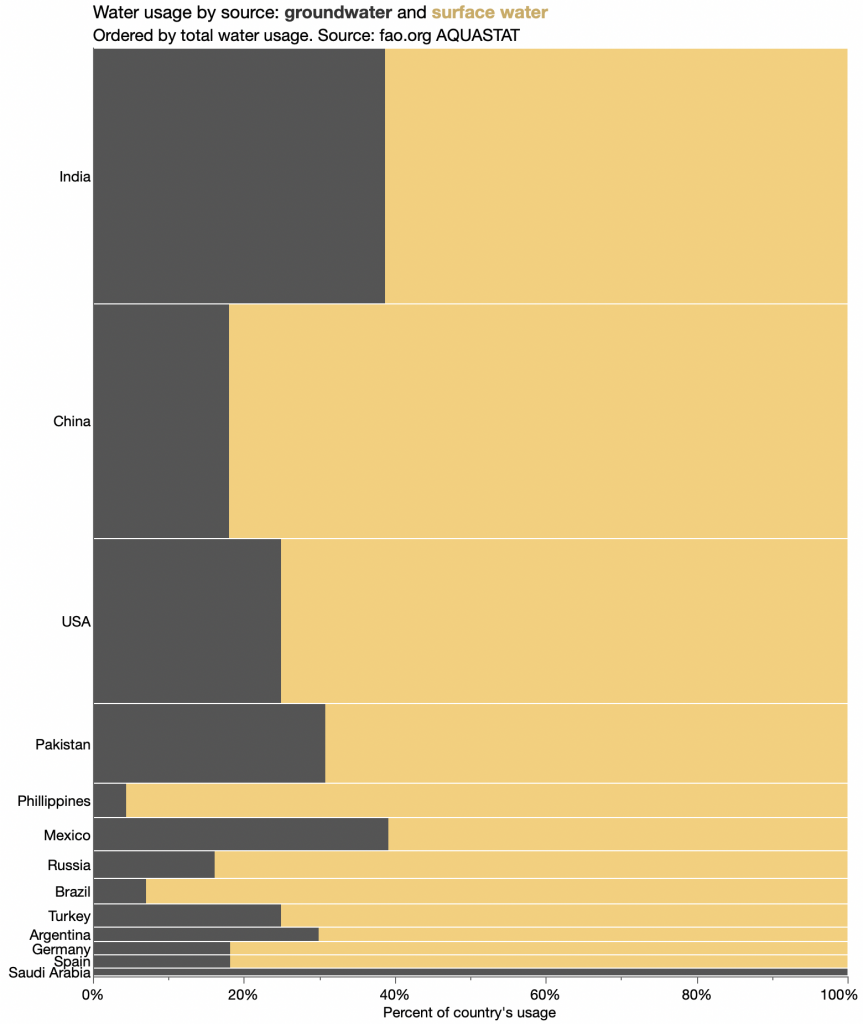
The breadths correspond to water usage for the entire country, the lengths correspond to the relative breakdown within country, and the areas correspond to the water usage for that country and source. Now it’s the proportion of each water source that’s easiest to compare.
Remake as bars
Regarding the general value of bar-mekko charts, Dan Zvinca noted on Twitter:
I believe that it is always easier (and uniform) to compare components and the results of any math calculation (that includes basic arithmetic operations as well) than encoding the components and the results in one view.
That’s the thinking behind my bar chart version.
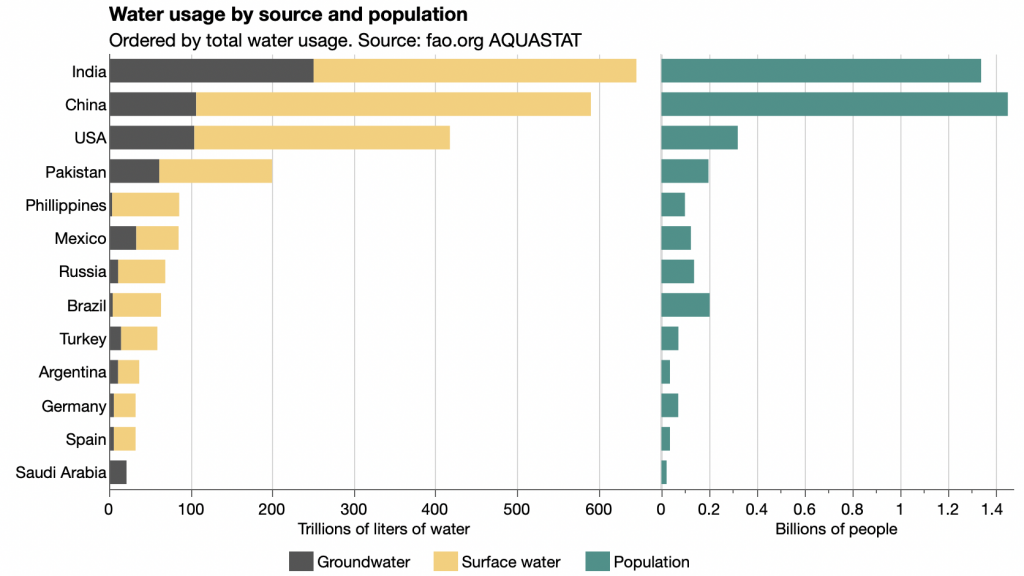
Now it’s easy to compare both the total water usage and the groundwater usage among countries without the area distraction or the tight labeling challenges.









